AWS News Blog
Analyze Large Data Sets on Elastic MapReduce Clusters With Impala
Impala is an open source query tool for Hadoop. You can use familiar SQL-like statements to activate Impala’s distributed in-memory query engine, allowing you to quickly and efficiently process large amounts of data. In many cases, Impala is significantly faster than Hive, allowing you to interact with your data in real-time. Impala can process data stored in HDFS and HBase tables, work with unstructured data in a variety of formats, and supports user defined functions. Its a great application for ad hoc queries, and is compatible with many popular Business Intelligence (BI) tools.
Today we are making Impala available as part of Amazon Elastic MapReduce. You can now launch a cluster with Impala preinstalled, load new data or access existing data, and run fast queries using a SQL-like language. Clusters can be launched from the command line using the Elastic MapReduce tools, or from the AWS Management Console:
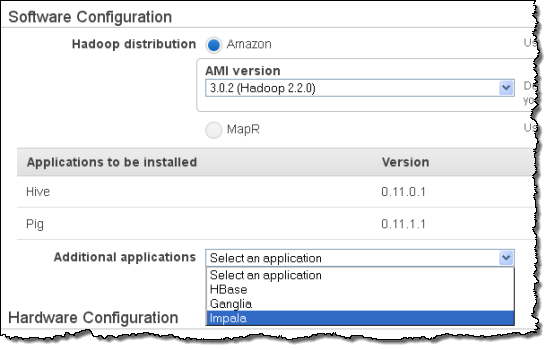
Note that you must launch an Amazon distribution containing Hadoop 2.x (AMI version 3.0.2) if you want to make use of Impala.
I spent some time working through the new Impala tutorial in the Elastic MapReduce Developer Guide. Despite my lack of experience with Hadoop or Impala, I was able to create, load and query a sample data set without too much trouble. The sample data set consists of text files named customers, books, and transactions, each containing randomly generated data items of the appropriate type.
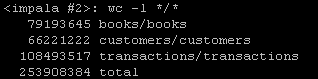
I started out with 1 gigabyte files and then scaled up to 5 gigabytes. Here’s what that means in terms of line counts (equivalent to database records):
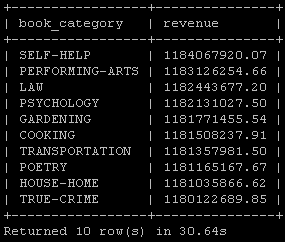
I was able to import each of these files in less than 2.5 seconds on an 11 node cluster composed of m1.large instances. There’s no indexing phase and the tables can be queried immediately after the import. For example, the following memory-intensive query joins three tables:
SELECT tmp.book_category, ROUND(tmp.revenue, 2) AS revenue FROM ( SELECT books.category AS book_category, SUM(books.price * transactions.quantity) AS revenue FROM books JOIN [SHUFFLE] transactions ON ( transactions.book_id = books.id AND YEAR(transactions.transaction_date) BETWEEN 2008 AND 2010 ) GROUP BY books.category ) tmp ORDER BY revenue DESC LIMIT 10;
It ran in a little over 30 seconds on my 11 node cluster:
Because Impala is part of the Hadoop ecosystem, it is easy to scale in order to accommodate ever-growing data sets. You can scale out by adding additional nodes to your Amazon EMR cluster. If you need additional memory per node, you can easily create a new cluster that uses instance types with additional RAM.
Impala is available today and you can start using it now!
— Jeff;