AWS for Life Sciences
Built for breakthroughs: discover why 9 out of the top 10 pharma companies globally choose AWS for data analytics and machine learning.
New! Generative AI in Healthcare and Life Sciences resource hub
Innovation for insights that matter
Benefits
Why choose AWS for Life Sciences
AWS is the most secure, compliant, and resilient cloud for life sciences with the highest network availability of any cloud provider, and offering more than 146 HIPAA-eligible services and certifications for global compliance standards, like GDPR, GxP, and HITRUST CSF.
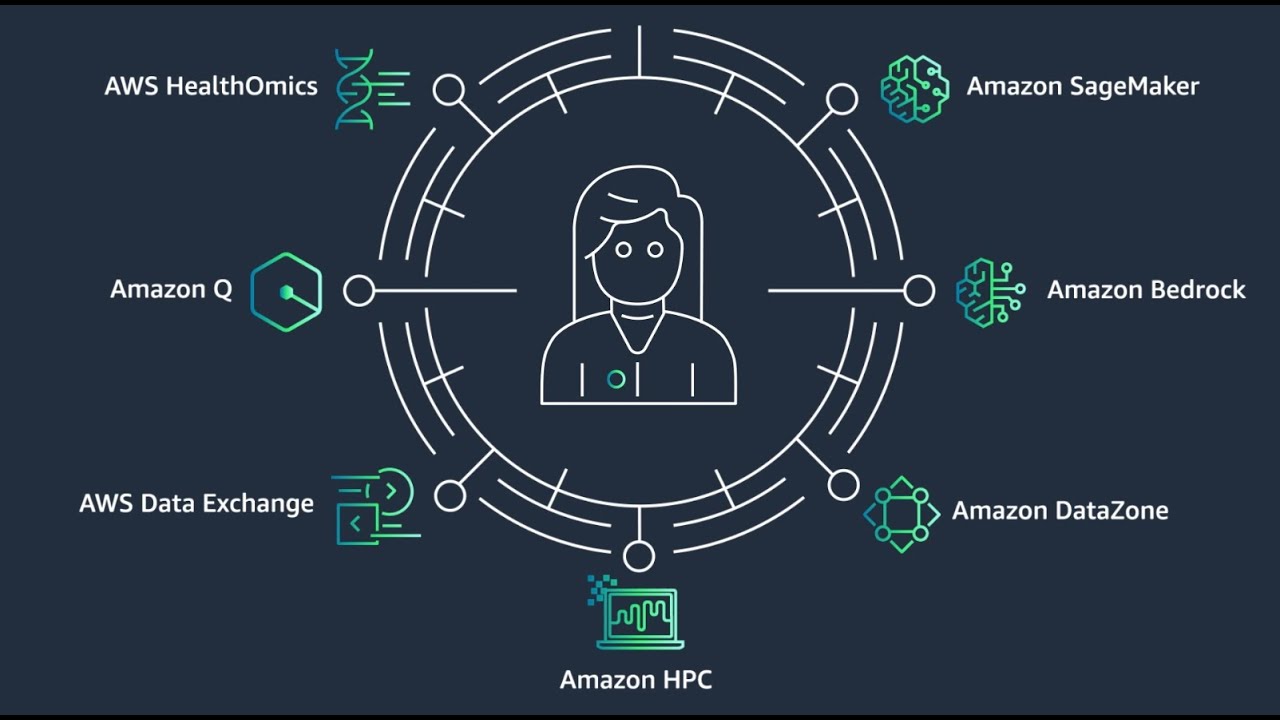
With 6 services built specifically for healthcare and life sciences use cases—more than any other cloud provider—AWS makes it easier to access, analyze, and extract key insights from complex unstructured data.
AWS enables life sciences organizations to discover and select the best offerings to address their unique business needs and accelerate time-to-value through the AWS Partner Network and AWS Marketplace.
Customer Stories
Sanofi
Gilead
AstraZeneca
 AstraZeneca's Development Assistant—an AI-powered, interactive agent—enables natural language access to its clinical trial data landscape for accelerating insights.
AstraZeneca's Development Assistant—an AI-powered, interactive agent—enables natural language access to its clinical trial data landscape for accelerating insights.
Research and development
Accelerate time to discovery, de-risk portfolios, and advance candidates into development faster with AWS, all while maintaining the highest levels of security and privacy.
Roche
Pfizer
Institut Pasteur
Key Use Cases
Lab digitization
Research data management & collaboration
Pharmacogenomics
High-throughput modeling and screening
Service Spotlight
Clinical development
Power the entire clinical development process—from more effective and inclusive trials to streamlining the regulatory submission process. AWS and AWS Partner solutions help securely capture and extract insights from the massive amounts of data generated during clinical trials, facilitate decentralized trials, and effectively collaborate between stakeholders.
Pfizer
 Pfizer deploys an efficient, scalable, and automated method to run custom-built digital biomarkers on trial participants’ wearable device data from large global clinical trials
Pfizer deploys an efficient, scalable, and automated method to run custom-built digital biomarkers on trial participants’ wearable device data from large global clinical trials
Merck
Novo Nordisk
Key Use Cases
Trial data management
Protocol design & trial optimization
Regulatory submission process
Service Spotlight
Manufacturing & Supply Chain
Gain end-to-end visibility into your manufacturing and supply chain process to drive new efficiencies, improve resiliency, and avoid compliance violations with the most comprehensive suite of data, analytics, and IoT services. Unlock new insights and proactively identify potential disruptions with advanced analytics offerings and AI tools trained on Amazon’s own datasets.
Merck
Baxter
Amazon Pharmacy
 Amazon Pharmacy Increases Forecast Accuracy and Reduces Manual Efforts Using AWS Supply Chain
Amazon Pharmacy Increases Forecast Accuracy and Reduces Manual Efforts Using AWS Supply Chain
Use Cases
Manufacturing optimization
Supply chain resiliency
Regulatory compliance
Service Spotlight
Commercialization & Medical Affairs
Turn your data into a strategic asset to help you focus on more targeted product launches, gain deeper customer insights, and create more personalized patient experiences by leveraging the most comprehensive suite of data, analytics, and AI offerings.
Eli Lilly
Alnylam
Alcon
Use Cases
Adverse event detection
Real world evidence and Real world data
Personalized patient experiences
Service Spotlight
Innovate with key industry partners
Discover purpose-built life sciences solutions and services from an extensive network of industry-leading AWS Partners who have demonstrated technical expertise and customer success in building solutions on AWS.
AWS Partner Network
 AWS offers the largest network of partners, along with flexible workflow choice, and options for fully managed solutions to help you get to life sciences insights faster.
AWS offers the largest network of partners, along with flexible workflow choice, and options for fully managed solutions to help you get to life sciences insights faster.
AWS Marketplace
 Accelerate life sciences innovation, discovery, and development with third-party purpose-built solutions.
Accelerate life sciences innovation, discovery, and development with third-party purpose-built solutions.
Get started
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages