Amazon Redshift
Ofrezca una relación precio/rendimiento inigualable a escala con SQL para su almacén de lago de datos
¿Por qué elegir Amazon Redshift?
Amazon Redshift permite el análisis de datos moderno a escala, con un rendimiento de precio hasta 3 veces superior y un rendimiento hasta 7 veces superior en comparación con otros almacenes de datos en la nube. Redshift sin servidor le ayuda a escalar las cargas de trabajo de análisis sin esfuerzo y sin tener que administrar la infraestructura del almacén de datos. Las integraciones sin ETL permiten realizar análisis casi en tiempo real al conectar con facilidad los datos de servicios de streaming, bases de datos operativas y aplicaciones empresariales de terceros sin necesidad de canalizaciones de datos complejas. Amazon Q en Redshift aumenta la productividad y simplifica la creación de SQL mediante lenguaje natural. Obtenga resultados más precisos en las aplicaciones de IA generativa al utilizar Redshift como base de conocimiento estructurada en Amazon Bedrock. Redshift se integra de forma fluida con la nueva generación de Amazon SageMaker, lo que permite aprovechar sus potentes capacidades de análisis en SQL sobre datos unificados en el lago de datos en Amazon SageMaker.
Respaldar la última generación de Amazon SageMaker
Beneficios
-
Obtenga hasta una relación entre precio y rendimiento hasta 3 veces superior y 7 veces más rendimiento que otros almacenes de datos en la nube a medida que escala sus cargas de trabajo de análisis de datos en Amazon Redshift. Reduzca los costos y cumpla con los SLA críticos para la empresa al aislar las cargas de trabajo con arquitecturas de almacenes de datos múltiples escalables en toda su organización. Con características de seguridad integrales, como el aislamiento de la red y controles de acceso detallados, como los permisos a nivel de la fila y la columna, puede proteger sus datos sin costo adicional.
Aproveche las potentes capacidades de análisis en SQL de Redshift sobre todos los datos unificados gracias a su integración fluida con Amazon SageMaker. Consulte los datos en formatos abiertos almacenados en Amazon S3 con alto rendimiento, sin necesidad de mover ni duplicar información entre los lagos de datos y el almacén de datos. Incorpore fácilmente los datos de Redshift al lago de datos en SageMaker, lo que permite que una amplia variedad de motores de análisis y herramientas de machine learning compatibles con AWS y Apache Iceberg accedan a estos.
-
Innove más rápido al hacer que los petabytes de datos estén disponibles para el análisis sin tener que crear y administrar canalizaciones complejas, lo que permite el acceso casi en tiempo real para los casos de uso de análisis. Aproveche las integraciones sin ETL para mover sin problemas los datos transaccionales de bases de datos como Amazon Aurora, RDS y DynamoDB a Redshift sin afectar al rendimiento. Incorpore grandes volúmenes de datos en tiempo real desde Amazon Kinesis y Amazon MSK con integraciones nativas de servicios de streaming. Con todos sus datos en un solo lugar, podrá realizar análisis casi en tiempo real y crear modelos predictivos de machine learning de forma directa en Amazon Redshift para obtener información empresarial de gran valor.
-
Comience a analizar sus datos en unos segundos con Amazon Redshift sin servidor. Amazon Redshift sin servidor aprende de sus cargas de trabajo y escala automáticamente los recursos de computación para gestionar sus necesidades analíticas cambiantes, de modo que pueda centrarse en descubrir información sin tener que administrar la infraestructura. Simplemente, conéctese a sus orígenes de datos y comience a analizar los datos, sin necesidad de configurar ni mantener la infraestructura.
-
Cree aplicaciones personalizadas con petabytes de datos de su organización mediante la integración perfecta de Amazon Redshift con Amazon Bedrock. Aumente la productividad al permitir a los usuarios de datos escribir consultas SQL con mayor rapidez mediante lenguaje natural con el SQL generativo de Amazon Q en Amazon Redshift Query Editor. Invoque modelos de lenguaje de gran tamaño de Amazon Bedrock y SageMaker para realizar tareas avanzadas de procesamiento del lenguaje natural, como el resumen de textos, la extracción de entidades y el análisis de opiniones, para obtener información más profunda de sus datos mediante SQL.
Capacidades críticas de Gartner para 2025 para los sistemas de administración de bases de datos en la nube
AWS se encuentra entre los dos proveedores con mayor puntuación en todos los casos de uso de análisis.
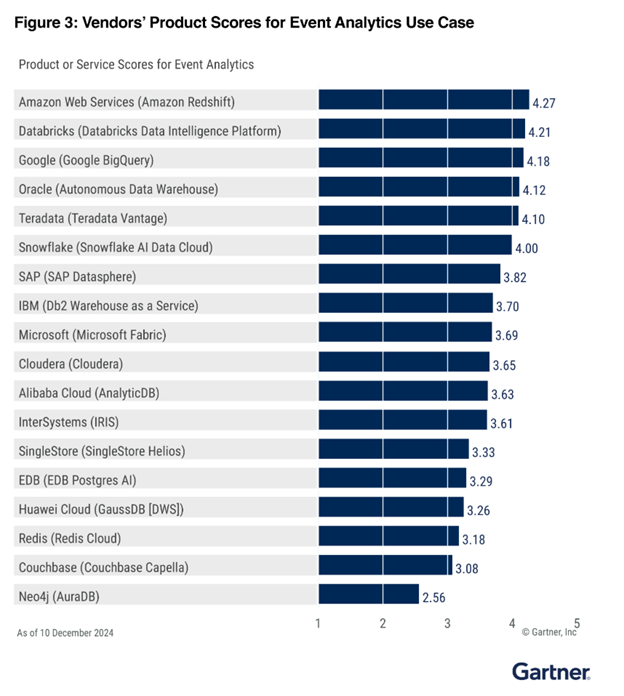
1.º en análisis de eventos
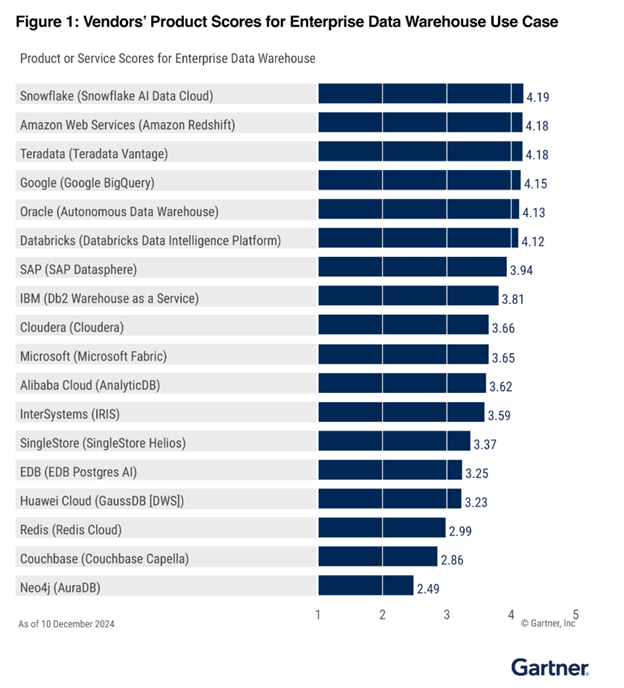
2.º en almacenamiento de datos empresariales
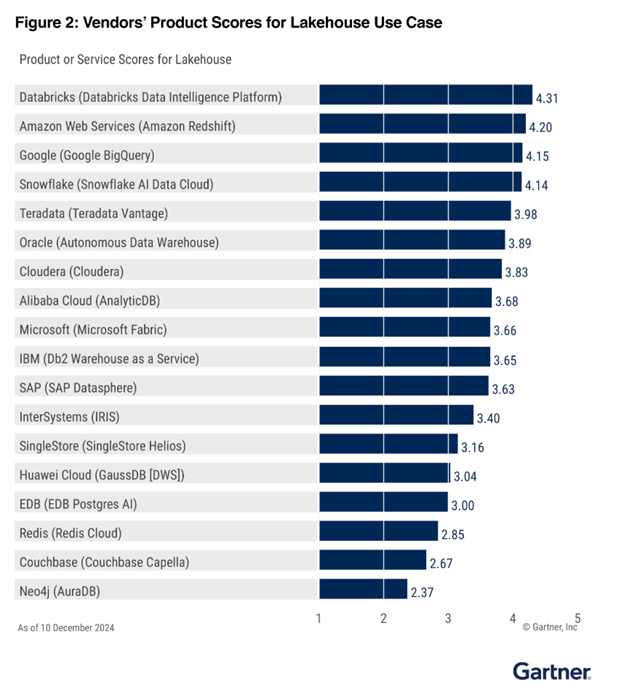
2.º en Lakehouse
Descargo de responsabilidad
GARTNER es una marca registrada y una marca de servicio de Gartner, Inc. y/o sus filiales en los Estados Unidos y a nivel internacional y se utiliza aquí con permiso. Todos los derechos reservados.
Gartner no respalda a ningún proveedor, producto o servicio representado en sus publicaciones de investigación y no aconseja a los usuarios de tecnología que seleccionen solo a los proveedores con las calificaciones más altas u otra designación. Las publicaciones de investigación de Gartner están formadas por opiniones de la organización de investigación de Gartner y no deben interpretarse como declaraciones de hecho. Gartner niega cualquier garantía, expresada o implícita, respecto a esta investigación, incluidas las garantías de comercialización o idoneidad para un fin particular. Gartner, Inc. publicó este gráfico dentro de un informe de investigación más extenso, por lo que se debe evaluar en el contexto del documento completo. El informe de Gartner se puede solicitar a AWS.
Casos de uso
Ingiera cientos de megabytes de datos por segundo para poder consultar los datos casi en tiempo real y crear aplicaciones de análisis de baja latencia para la detección de fraudes, marcadores en vivo y IoT.
Cree informes y paneles basados en información mediante Amazon Redshift y herramientas de inteligencia empresarial como Amazon QuickSight, Tableau o Microsoft PowerBI, entre otras.
Use SQL a fin de crear, entrenar e implementar modelos de ML para muchos casos de uso, incluidos el análisis predictivo, la clasificación o la regresión, entre otros, para respaldar el análisis avanzado de una gran cantidad de datos.
Cree aplicaciones sobre todos sus datos en bases de datos, almacenamientos de datos y lagos de datos. Comparta y colabore en los datos de forma fluida y segura a fin de generar más valor para sus clientes, monetizar sus datos como servicio y acceder a nuevas fuentes de ingresos.
Ya sea que se trate de datos de mercado, análisis de redes sociales, datos meteorológicos o más, suscríbase y combine datos de terceros en AWS Data Exchange con sus datos en Amazon Redshift sin tener que preocuparse por los procesos de licenciamiento e incorporación, y sin tener que trasladar los datos al almacén.
Amazon Redshift sin servidor
Ejecute y escale análisis con facilidad en segundos sin tener que aprovisionar ni administrar un almacenamiento de datos
Introducción a Amazon Redshift
¿Ha encontrado lo que buscaba hoy?
Ayúdenos a mejorar la calidad del contenido de nuestras páginas compartiendo sus comentarios