Projetado para alta taxa de transferência e baixa latência, o Amazon CloudSearch oferece suporte a um conjunto completo de recursos que incluem processamento de texto específico por idioma para 34 idiomas, pesquisa de texto livre, pesquisa facetada, pesquisa geoespacial, classificação personalizável de relevância, destaque, autopreenchimento e opções de escalabilidade e disponibilidade configuráveis pelo usuário.
Para usar o Amazon CloudSearch, siga estas etapas simples:
- Crie um domínio de pesquisa
- Configure as opções de indexação dos seus dados
- Faça o upload dos dados para
- Envia solicitações de pesquisa a partir de seu site ou aplicativo.
Veja detalhes de como o CloudSearch funciona na seção a seguir.
Experimente o Amazon CloudSearch gratuitamente
Inicie um teste gratuito do CloudSearchSaiba mais
Obtenha 750 horas gratuitas de instâncias de pesquisa totalmente funcionais por 30 dias. Para começar:
Faça login em sua conta da AWS e inicie o console do CloudSearch
Crie e configure um domínio de pesquisa com alguns cliques
Você cria um domínio de pesquisa do Amazon CloudSearch para cada coleção de dados que deseja tornar pesquisável. Um domínio de pesquisa encapsula os dados e os recursos de hardware e software necessários para operar um mecanismo de pesquisa. Cada domínio de pesquisa tem uma ou mais instâncias de pesquisa. Uma instância de pesquisa é uma instância de servidor que tem uma quantidade finita de recursos de RAM e de CPU para indexar dados e processar solicitações. O número de instâncias de pesquisa em um domínio depende dos documentos de sua coleção e do volume e complexidade das solicitações de pesquisa.
Sendo um serviço gerenciado, o Amazon CloudSearch determina o tamanho e o número de instâncias de pesquisa necessárias para disponibilizar um desempenho de pesquisa com baixa latência e alta taxa de transferência. Quando você cria um domínio de pesquisa, o Amazon CloudSearch usa por padrão o tipo de instância de pesquisa pequena (search.m1.small). Você pode selecionar um tipo de instâncias maior para aumentar a capacidade de atualização do domínio e reduzir a quantidade de tempo necessária para fazer upload e indexar uma grande coleção de dados. (Se você precisa de capacidade superior à oferecida pelo maior tipo de instância, pode aumentar o número de instâncias usadas para particionar o índice.)
À medida que cresce a quantidade de dados no índice de pesquisa, o Amazon CloudSearch redimensiona automaticamente o domínio de pesquisa de acordo com a necessidade. Quando o índice excede a capacidade do tipo de instância atual, o domínio é redimensionado para o tipo de instância de tamanho imediatamente superior. Se o índice de pesquisa excede a capacidade do maior tipo de instância, o Amazon CloudSearch particiona o índice entre várias instâncias. De modo oposto, se o índice diminuir, o CloudSearch redimensiona o domínio para menos partições ou para um tipo de instância menor.
O Amazon CloudSearch também redimensiona automaticamente para processar aumentos no volume de tráfego de pesquisa. Quando um tipo de instância se aproxima da carga máxima de consultas, o CloudSearch implementa uma réplica da instância de pesquisa. Por outro lado, quando o tráfego cai, o Amazon CloudSearch remove as réplicas desnecessárias para minimizar os custos.
Por exemplo, um índice de pesquisa dividido em três partições usa três instâncias de pesquisa, uma para cada partição. Quando o tráfego de pesquisa excede a capacidade de processamento das instâncias de pesquisa individuais, as partições são replicadas para oferecer capacidade adicional de consultas. Quando as instâncias são replicadas, o domínio passa a ter seis instâncias de pesquisa, duas para cada partição. Se o tráfego continua a crescer, o Amazon CloudSearch adiciona mais réplicas de acordo com a necessidade.
Se você espera ter um grande volume de tráfego de consultas ou picos substanciais de tráfego, pode adicionar explicitamente mais réplicas de instâncias de pesquisa ao seu domínio.

Você pode visualizar os recursos usados pelos seus domínios do Amazon CloudSearch na página de atividade da conta no site da AWS, no AWS Management Console ou enviando solicitações de API do CloudSearch por meio do AWS CLI ou de AWS SDKs.
A quantidade de dados suportada em cada tipo de instância depende principalmente do tamanho dos documentos indexados e das opções de indexação configuradas no domínio.
Para demonstrar a capacidade de cada tipo de instâncias, vamos examinar um exemplo de documento e de configuração para o conjunto de dados de filmes do IMDb. O exemplo a seguir mostra um documento de filme do IMDb que tem um tamanho aproximado de 1 KB:
{
"fields" : {
"directors" : [
"Francis Lawrence"
],
"release_date" : "2013-11-11T00:00:00Z",
"genres" : [
"Action",
"Adventure",
"Sci-Fi",
"Thriller"
],
"image_url" : "http://ia.media-imdb.com/images/M/MV5xMzNeMzAx._V1_SX400_.jpg",
"trama" : "Katniss Everdeen e Peeta Mellark tornam-se alvos do Capitólio após a vitória nos Jogos Vorazes 74 deflagrar uma rebelião nos Distritos de Panem.","title" : "The Hunger Games: Catching Fire",
"rank" : 4,
"running_time_secs" : 8760,
"actors" : [
"Jennifer Lawrence",
"Josh Hutcherson",
"Liam Hemsworth"
],
"year": 2013
},
"id" : "tt1951264",
"type": "add"
}
Para indexar e pesquisar documentos de filme como esse, configuramos o domínio de pesquisa com um campo de índice para cada campo do documento. Podemos especificar várias opções de indexação para cada campo, como o tipo do campo e se o campo é pesquisável, comporta facetas, comporta retornos, comporta classificação e comporta destaque. Essas opções de indexação afetam diretamente a quantidade de documentos que podem ser processados em uma instância de pesquisa. A tabela a seguir mostra um exemplo de configuração dos campos de indexação dos nossos documentos de filmes do IMDb.
| Nome |
Tipo |
Pesquisa |
Faceta |
Voltar |
Classificação | Destaque |
|---|---|---|---|---|---|---|
| actors |
array de texto |
✔ | – | ✗ | – | ✗ |
| directors |
array de texto |
✔ | – | ✗ | – | ✗ |
| genres |
array de literal |
✔ | ✔ | ✗ |
– | – |
| url_imagem |
text |
✗ | – | ✗ | ✗ | ✗ |
| plot |
text |
✔ | – | ✗ | ✗ | ✔ |
| rank | int | ✔ | ✗ | ✗ | ✔ | – |
| nota |
double |
✔ | ✔ | ✗ | ✔ | – |
| data_lancamento |
data |
✔ | ✔ | ✗ | ✔ | – |
| running_time_secs |
int |
✔ | ✔ | ✗ | ✔ | – |
| title |
text |
✔ | – | ✔ | ✔ | ✔ |
| year |
int |
✔ | ✔ | ✔ | ✔ | – |
Com base no tamanho do documento (1 KB) e nessa configuração de índice, cada tipo de instância de pesquisa tem a capacidade de documentos mostrada na tabela a seguir.
| Tipo de instância de pesquisa | Capacidade de dados |
|---|---|
| Instância de pesquisa pequena (search.m1.small) |
2 milhões de documentos |
| Instância de pesquisa grande (search.m1.large) | 8 milhões de documentos |
| Instância de pesquisa extragrande (search.m2.xlarge) |
16 milhões de documentos |
| Instância de pesquisa dupla extragrande (search.m2.2xlarge) | 32 milhões de documentos |
Naturalmente, este é apenas um exemplo. Documentos e configurações diferentes podem alterar drasticamente o número de documentos comportados por uma instância. Se você exceder a capacidade de uma única instância de pesquisa dupla extragrande, o Amazon CloudSearch automaticamente particionará o índice de pesquisa em várias instâncias de pesquisa do tipo dupla extragrande. Um índice pode ser particionado em até 10 instâncias de pesquisa do tipo dupla extragrande para suportar dezenas ou centenas de milhões de documentos. Se você precisa de escalabilidade adicional, entre em contato conosco.
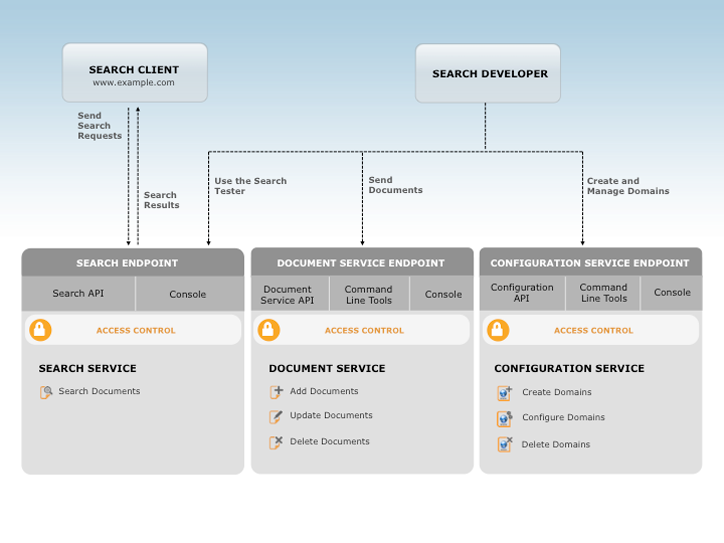
A interação com o Amazon CloudSearch é feita por meio de três serviços:
- Serviço de configuração: Crie e configure domínios de pesquisa
- Serviço de documentos: Faça upload de lotes de documentos
- Serviço de pesquisa: Envie solicitações de pesquisa e sugestões
As políticas do AWS Identity and Access Management (IAM) são usadas para gerenciar o acesso ao serviço de configuração do Amazon CloudSearch e aos documentos e serviços de pesquisa de cada domínio.
O serviço de configuração permite criar e configurar domínios de pesquisa. Para definir um domínio de pesquisa, você atribui a ele um nome único e configura opções de indexação, esquemas de análise de texto, opções de disponibilidade, opções de escalabilidade, sugestores e expressões:
- As opções de indexação especificam os campos que você deseja incluir no índice. Você pode usar o AWS Management Console ou as ferramentas de linha de comando do Amazon CloudSearch para examinar os dados e configurar automaticamente as opções de indexação padrão.
- Os esquemas de análise de texto especificam opções de processamento de texto específicas do idioma para campos de texto e de array de texto. Os esquemas de análise controlam as palavras vazias que devem ser ignoradas durante a indexação, definem sinônimos comuns para os termos e especificam como os termos são mapeados para raízes de palavras comuns.
- As opções de disponibilidade permitem implementar um domínio em duas zonas de disponibilidade para garantir alta disponibilidade em caso de interrupção de serviços.
- As opções de escalabilidade permite determinar previamente a escala do domínio, especificando o tipo de instâncias e o número de replicações e de partições desejados. Isso é útil quando é necessário fazer upload de um grande volume de documentos ou quando é esperado um aumento significativo no tráfego de consultas.
- Os sugestores permitem recuperar as correspondências possíveis para uma consulta de pesquisa incompleta, permitindo a exibição de resultados à medida que o usuário digita.
- As expressões são expressões numéricas avaliadas durante a execução da consulta. Você pode usar expressões para controlar como os resultados de pesquisa são classificados. Por padrão, os documentos são classificados de acordo com uma pontuação de relevância que considera a frequência dos termos de pesquisa em um documento. É possível usar expressões para incluir outros fatores na classificação. Por exemplo, se os documentos contêm um campo numérico denominado "popularidade", você pode definir uma expressão que combina a popularidade com a pontuação padrão de relevância para classificar os documentos populares nas primeiras posições dos resultados de pesquisas.
O serviço de documentos permite alterar os dados pesquisáveis de um domínio. Cada domínio tem um único endpoint HTTP de serviço de documentos.
Para enviar dados para o domínio, é preciso formatá-los em JSON ou XML. Cada item que deve poder ser obtido como resultado de pesquisa é representado como um documento. Cada documento tem um ID único e um ou mais campos que contêm os dados que podem ser pesquisados e retornados como resultados. Os campos de um documento podem conter dados sob a forma de sequências UTF-8. As opções de indexação do domínio especificam como os dados devem ser indexados e utilizados.
O serviço de pesquisa processa as solicitações de pesquisa e as sugestões de um domínio. Cada domínio tem um único endpoint HTTP de pesquisa. Quando você envia uma solicitação de pesquisa ou sugestão, o serviço de pesquisa retorna uma lista dos documentos correspondentes. Os resultados podem ser retornados em JSON ou XML.
O Amazon CloudSearch oferece uma linguagem de consulta rica que permite pesquisar em campos específicos, efetuar pesquisas booleanas complexas, recuperar informações de facetas e especificar quais dados você deseja que sejam incluídos nos resultados. Podem ser especificadas também opções para controlar como os termos de pesquisa são processados e a utilização de outros interpretadores de termos de consulta, como o do Lucene ou o do DisMax.
É possível usar o testador de busca situado no console do Amazon CloudSearch para testar amostras de consultas.
O uso deste serviço está sujeito ao Acordo do cliente da Amazon Web Services.