What is Amazon SageMaker Model Training?
Amazon SageMaker Model Training reduces the time and cost to train and tune machine learning (ML) models at scale without the need to manage infrastructure. You can take advantage of the highest-performing ML compute infrastructure currently available, and SageMaker can automatically scale infrastructure up or down, from one to thousands of GPUs. Since you pay only for what you use, you can manage your training costs more effectively. To train deep learning models faster, SageMaker helps you select and refine datasets in real time. SageMaker distributed training libraries can automatically split large models and training datasets across AWS GPU instances, or you can use third-party libraries, such as DeepSpeed, Horovod, or Megatron. Train foundation models (FMs) for weeks and months without disruption by automatically monitoring and repairing training clusters.
Benefits of cost effective training
Train models at scale
Fully managed infrastructure at scale
Efficiently manage system resources with a wide choice of GPUs and CPUs. This includes NVIDIA A100 and H100 GPUs as well as AWS accelerators like AWS Trainium and AWS Inferentia. SageMaker automatically scale infrastructure up or down, from one to thousands of GPUs.
Amazon SageMaker Hyperpod
SageMaker HyperPod removes the undifferentiated heavy lifting involved in building and optimizing ML infrastructure for training FMs, reducing training time by up to 40%. SageMaker HyperPod is pre-configured with SageMaker’s distributed training libraries that allow you to automatically split training workloads across thousands of accelerators, so workloads can be processed in parallel for improved model performance. When a hardware failure occurs, SageMaker HyperPod automatically detects the failure, repairs or replaces the faulty instance, and resumes the training from the last saved checkpoint, allowing you to train for week or months in a distributed setting without disruption.
High-performance distributed training
With only a few lines of code, you can add either data parallelism or model parallelism to your training scripts. SageMaker makes it faster to perform distributed training by automatically splitting your models and training datasets across AWS GPU instances.
Smart data shifting (Preview)
Accelerate deep learning model training by automatically filtering out low difficulty samples from your training data. By selecting data samples dynamically, the training dataset size is effectively reduced to include only informative samples. Using a refined subset of your data, the training job is completed up to 35% faster and with minimal or no impact to model accuracy.
Built-in tools for the highest accuracy and lowest cost
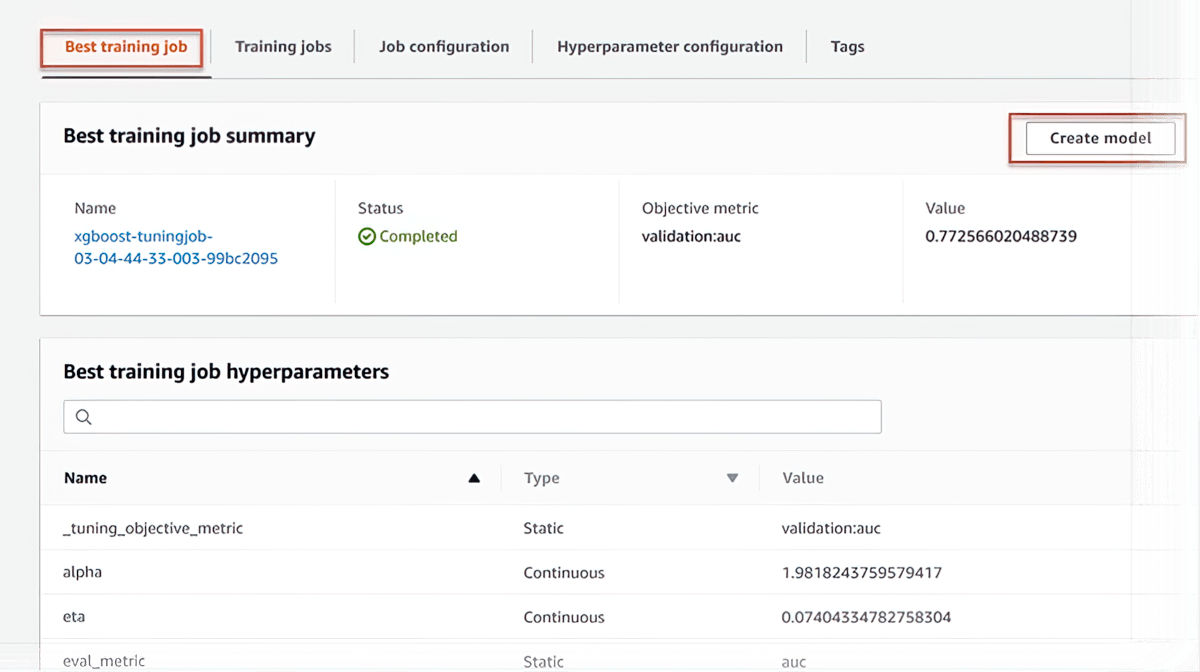
Automatic model tuning
SageMaker can automatically tune your model by adjusting thousands of algorithm parameter combinations to arrive at the most accurate predictions, saving weeks of effort. It helps you to find the best version of a model by running many training jobs on your dataset.
Managed Spot training
SageMaker helps reduce training costs by up to 90 percent by automatically running training jobs when compute capacity becomes available. These training jobs are also resilient to interruptions caused by changes in capacity.
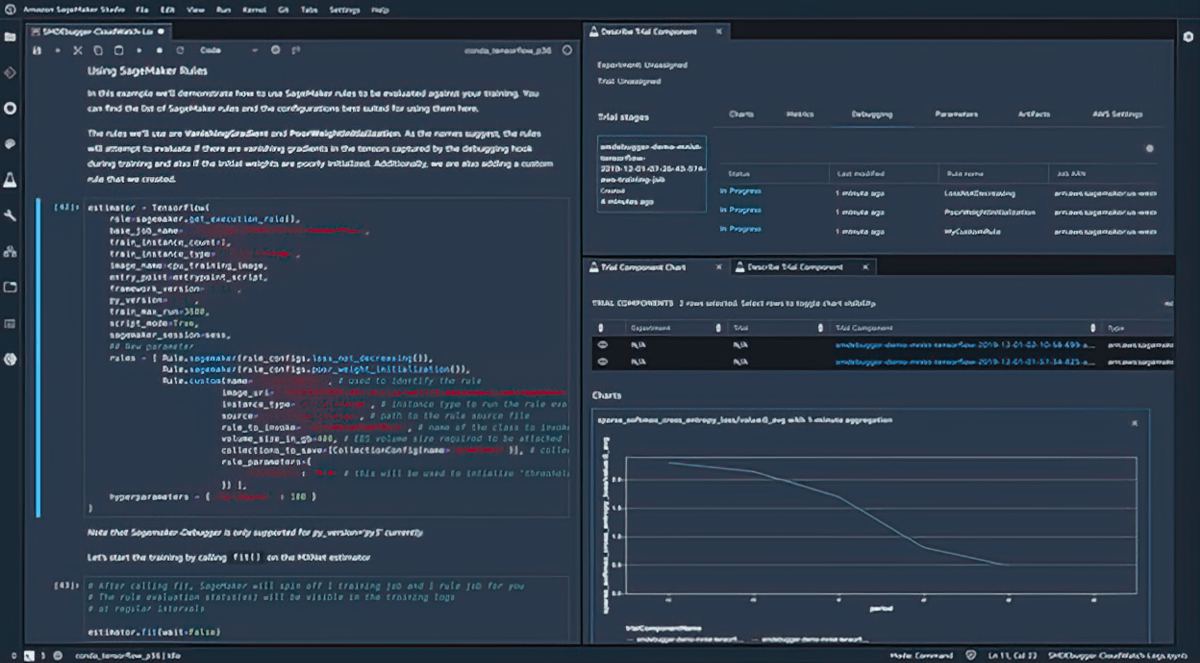
Debugging
Amazon SageMaker Debugger captures metrics and profiles training jobs in real time, so you can quickly correct performance issues before deploying the model to production. You can also remotely connect to the model training environment in Amazon SageMaker for debugging with access to the underlying training container.
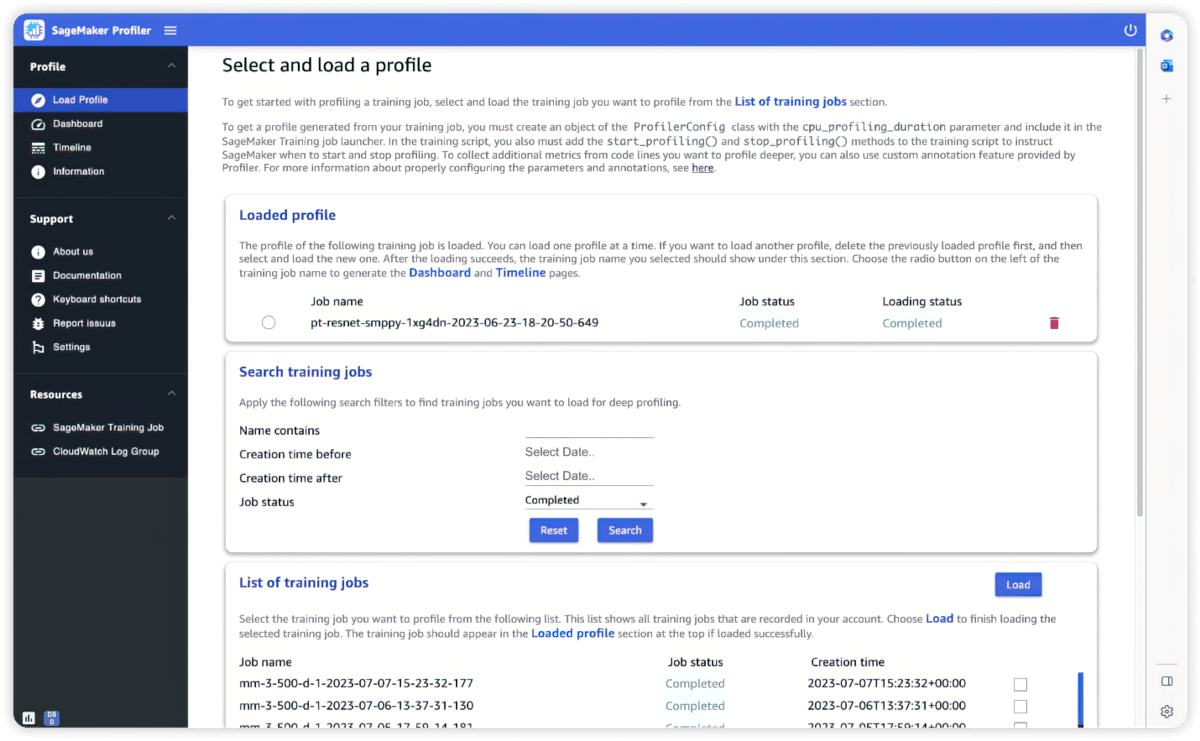
Profiler
Built-in tools for interactivity and monitoring

Experiment management
Amazon SageMaker Experiments captures input parameters, configurations, and results, and it stores them as experiments to help you track ML model iterations.
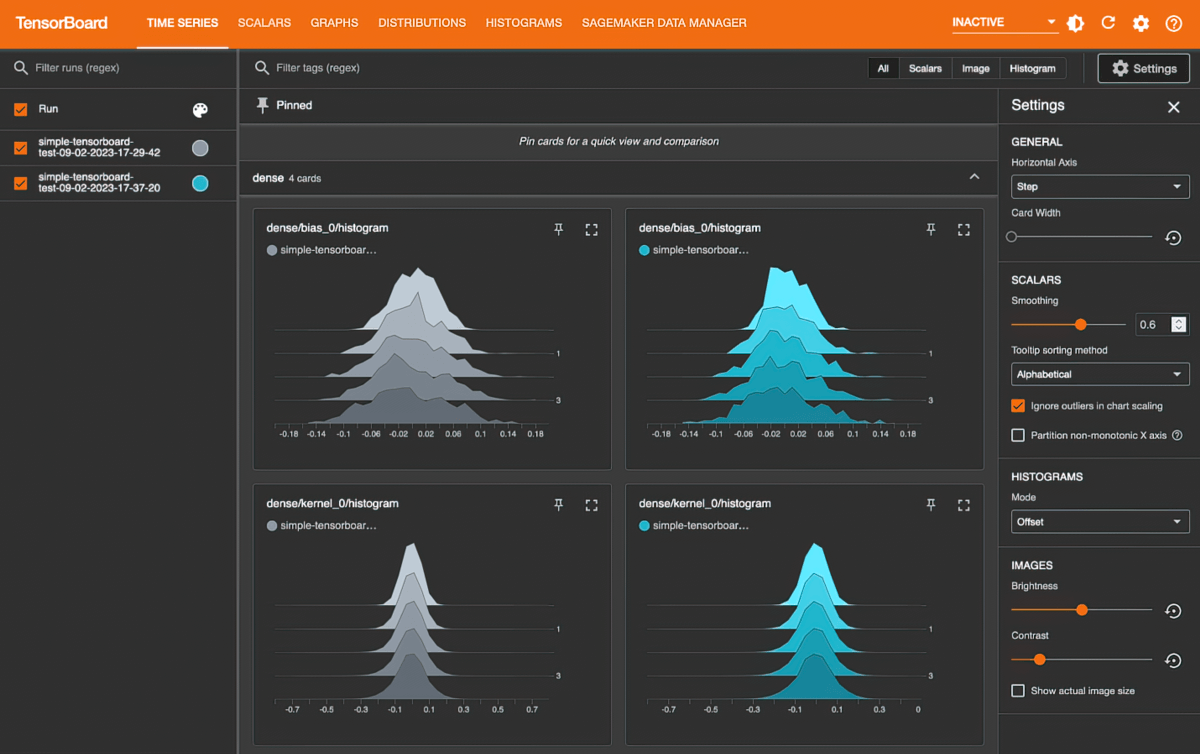
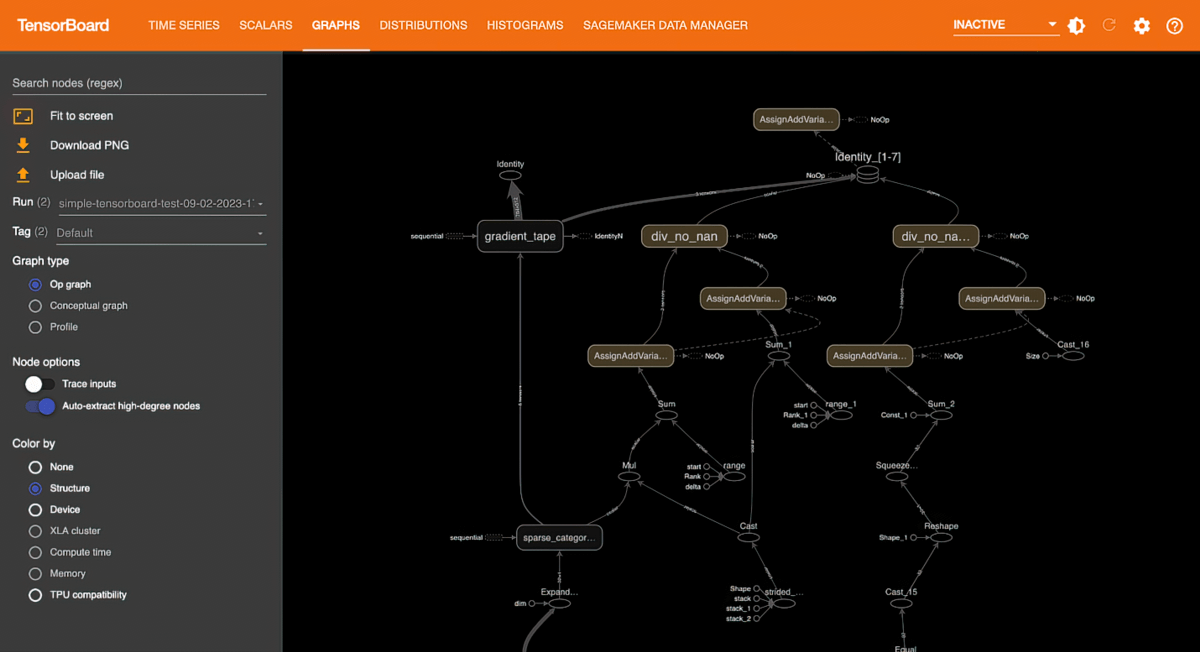
Amazon SageMaker with TensorBoard
Amazon SageMaker with TensorBoard helps you to save development time by visualizing the model architecture to identify and remediate convergence issues, such as validation loss not converging or vanishing gradients.
Flexible and faster training
Full customization
Local code conversion
Amazon SageMaker Python SDK helps you execute ML code authored in your preferred IDE and local notebooks along with the associated runtime dependencies as large-scale ML model training jobs with minimal code changes. You only need to add a line of code (Python decorator) to your local ML code. SageMaker Python SDK takes the code along with the datasets and workspace environment setup and runs it as a SageMaker Training job.
Automated ML training workflows
Automating training workflows using Amazon SageMaker Pipelines helps you create a repeatable process to orchestrate model development steps for rapid experimentation and model retraining. You can automatically run steps at regular intervals or when certain events are initiated, or you can run them manually as needed.