AWS Partner Network (APN) Blog
Amazon Fraud Detector Can Accelerate How AI is Embedded in Your Business
By Andrew Smale, Head of Sensory Digital at Inawisdom
By Phil Basford, Head of Solutions Architecture at Inawisdom
 |
Online fraud is estimated to be costing businesses more than £3billion a year, according to the FBI’s Internet Crime Report 2019. Excluding the United States, the United Kingdom is by far the worst affected country by number of victims.
Common types of fraud include:
- Email account compromise (personal or business)
- Social engineering (phishing, vishing, smishing, etc.)
- New account fraud
- Online account takeover or extortion (ransomware)
- Non-payment or non-delivery (including card numbers compromised)
- Scams, organised crime rings, and hacktivist/terrorism
At Inawisdom, our post-fraud analyses have identified several patterns. The most common include using a common IP address or similar data in fraudulent accounts, such as email domains. In other cases, fraudsters fake the entered country, residential status, or work status when applying for accounts.
Fraudsters also evolve new behaviours to get around preventive measures. As a result, we don’t have to solve one problem, we need a strategy that enables us to be responsive to new problems as they emerge.
Inawisdom is an AWS Premier Consulting Partner with the AWS Competencies in Machine Learning, DevOps, and Financial Services. Our goal is to accelerate adoption of advanced analytics, artificial intelligence (AI), and machine learning (ML) by providing a full-stack of Amazon Web Services (AWS) cloud and data services.
In this post, we will share our impressions of using Amazon Fraud Detector, along with a summary of what’s involved in setting up the service, training the models, and deploying them. We’ll finish with a few real-world considerations and personal recommendation.
Machine Learning Reduces Fraud
We commonly use machine learning to detect if something fishy is going on. Most of us have grown used to spam email filtering. It’s the classic example of how to use training data to recognise and categorise new events (arriving mail) so that an inbound email goes to the Junk folder.
Mostly it works, but we’ve all experienced the inconvenience of missing an email that was miscategorised by over-zealous filtering.
We also commonly detect online orders that are likely fraudulent and new accounts that are probably fake. In fact, one of our earliest ML projects at Inawisdom detected insurance fraud. We are currently focused on using augmented intelligence to reduce the burden on humans to check for fraud.
Why ML is Better than Rules
In the early days of online fraud prevention, we were encouraged to define specific checks; business rules, in effect. Business rules are great for covering specific conditions such as:
If IP_ADDRESS_LOCATION == [‘England’] and CUST_ADDRESS_COUNTRY != [‘England’] THEN CALL ‘AlertInvestigateLocationAnomaly’
What makes machine learning more flexible is its focus on identifying general patterns by looking at lots of examples. Because an ML data set is based on so many different cases, our defences can continue to work even when fraudsters change part of their approach. That’s because ML models adapt to changes that would get around rules like the one above.
It’s also important to continue to adapt; to close the loop by confirming fraud labelling and retraining the model to optimise its performance. We still use rules to interpret the model, but these rules are based on the output from the ML model. We also use human fraud detectors help to tune the rules, so we’re still very important in the process.
Tuning the model to specific fraud attempts is important because generic models underperform, and often require time-consuming data transformations. Data scientists call this tuning effort “feature engineering,” which includes selecting features based importance and optimising them using scaling or one hot encoding to improve the sensitivity and/or specificity of your model.
About Amazon Fraud Detector
Amazon Fraud Detector is a high-level AI service launched at AWS re:invent 2019 that’s designed to detect potentially fraudulent online activities and prevent them.
Inawisdom found Amazon Fraud Detector easy to use and flexible enough to accelerate how AI can be embedded in your online business. You can dynamically adjust the customer experience based on a result from Amazon Fraud Detector. Trusted customers who pass the detector get an optimal experience, so they do not suffer from fraudsters.
If the detector returns a positive match, you can ask for further authentication; for example, have a PIN sent to a mobile number.
There is currently one model type, Online Fraud Insights. This model type covers new account fraud, online payment fraud, and fake reviews. However, you can bring your own Amazon SageMaker model if you have a specialized model for a specific type of fraud.
The minimum required training data for the online fraud is two variables (like email, timestamp, or IP address) and two labels of whether data is fraudulent or not. Any number of other attributes can be added for consideration to improve the model. The key challenge is to separate the relevant data from the not-so-relevant, so you can seek out the strong relationship to fraudulent activities (feature selection).
Benefits of Amazon Fraud Detector
The main benefit of Amazon Fraud Detector is that it uses Amazon’s online fraud expertise. Your fraud team gets more control to swap detection models and versions in and out on the fly. Using Amazon’s rich online history accelerates time to value, but the protection is still built on your own business experience by using your own data.
Amazon Fraud Detector has been designed to integrate with other AWS services. You can build it from a template with data in Amazon Simple Storage Service (Amazon S3), and then train your model using an automated pipeline.
One way to automate your pipeline (if necessary) is to trigger your model retraining when data is uploaded to Amazon S3. Of course, you can use your own custom models if you want to.
How to Use Amazon Fraud Detector
As with many AWS machine learning services, there is a set workflow to follow, with optional steps:
- Source your data
- Create the model
- Train and tune the model
- Check model performance metrics
- Deploy the model
- Define detectors
- Test the model with sample data
Step 1: Source Your Data
To begin, you need a reasonable amount of historical fraud data in which you have identified (retrospectively, in many cases) that an activity was dodgy. Amazon Fraud Detector’s current Online Fraud Insights template expects a minimum 10,000 records. AWS recommend 3-6 months of historic data.
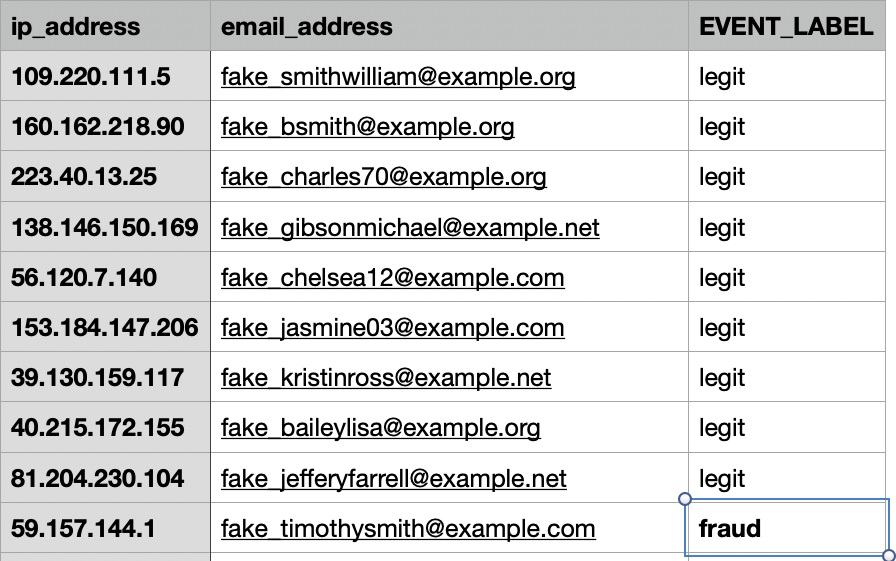
Figure 1 – Example of records with suspicious activity.
The sample dataset in Figure 1 shows the amount of data that’s necessary try out the Amazon Fraud Detector service. Note, particularly, the highlighted fraud_label, which is the output used in training the model. It can be any set of values, but to keep it simple, the test set defines “0” as legitimate data and “1” as fraudulent data.
You also need to configure these values in the model definition.
Step 2: Create the Model
Once you have sufficient data, you can create the ML model. If your case is simple, you can use the template provided by AWS. Provided types are built from Amazon.com’s years of experience and uses AutoML to produce a model. If you already have your own model or are an experienced data scientist, then you can use your own Amazon SageMaker model.
Define the data source path in Amazon S3; these are attributes to use as model inputs from columns headers. Also, specify the AWS Identity and Access Management (IAM) role to use, and the labels for fraudulent and legitimate data mentioned in Step 1.
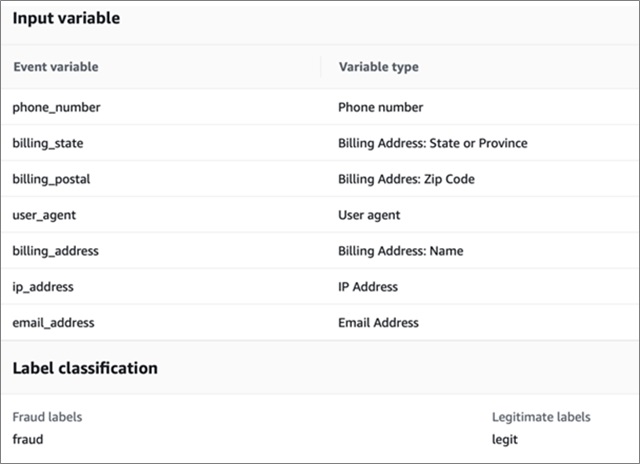
Figure 2 – Labels for fraudulent and legitimate data.
Step 3: Train and Tune the Model
Train the model and tune it to your desired level of detection accuracy. It’s critical to balance the trade-off between impacting all (legitimate) customers and preventing the minority who conduct fraudulent activity.
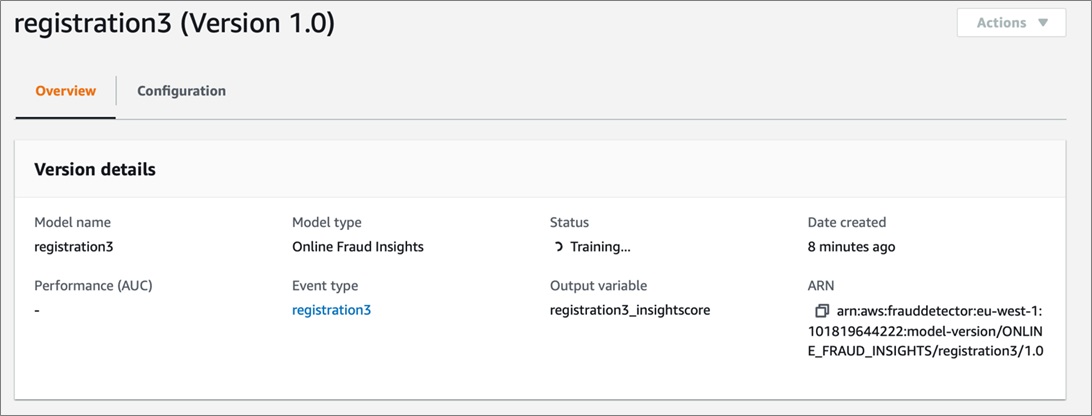
Figure 3 – Training and tuning the model in Amazon Fraud Detector.
The Models page in Figure 3 lists all of your models. Select it to see the performance and status of a model.
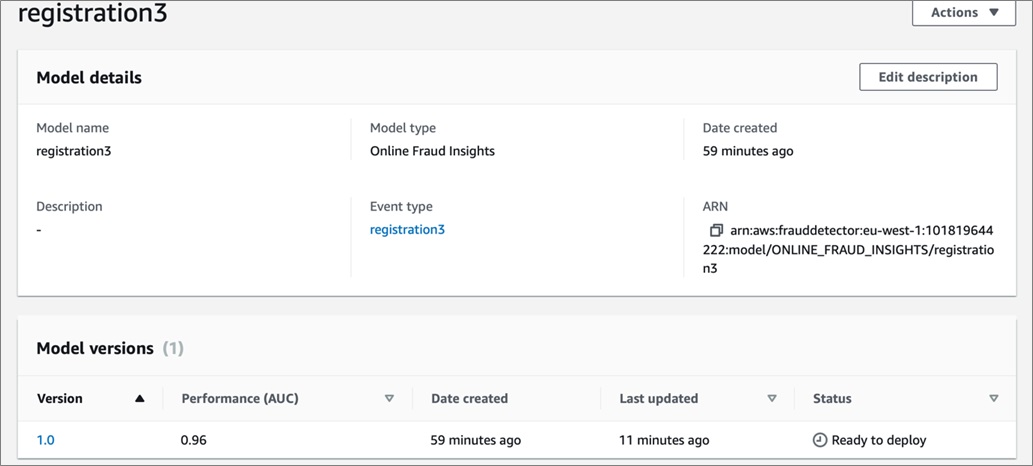
Figure 4 – Model versions and overall performance.
Step 4: Check Model Performance Metrics
To get detailed metrics for your trained model, select the version (for example, 1.0) on the left pane of the Models window.
The window that appears displays model specifications, charts, and tables, including the confusion matrix. The confusion matrix is a classic way to measure the impact on legitimate users through its false positive rate (FPR).
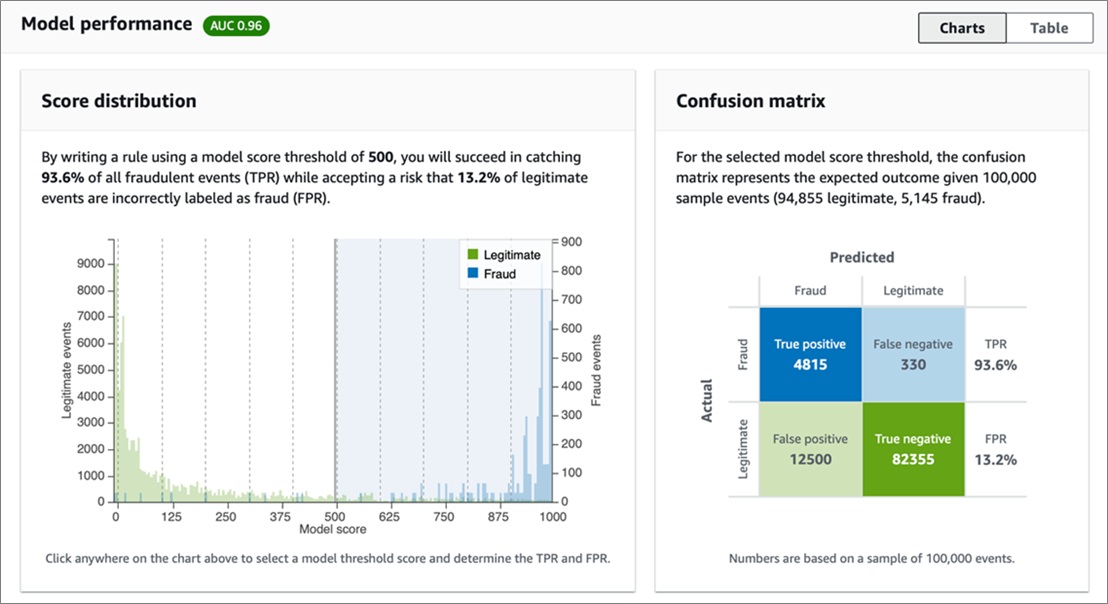
Figure 5 – Details about model performance, including the confusion matrix.
The Table tab includes a simple guide to tune the model to minimise false negatives (the model missed fraudulent data) and false positives (affecting your genuine users). This is why the overall metric displayed as Area Under Curve (AUC) links True Positive Rate (TPR) to False Positive Rate (FPR).
As previously mentioned, this is the crux of your fraud detection and prevention strategy. What is acceptable should ultimately be a business decision.
Step 5: Deploy the Model
Once you’re happy with the performance against test data, which should probably be higher than 90 percent, you can deploy the model.
Use the Actions menu on the top right of the window, as shown in Figure 5 above. Select Deploy model version and the status changes to Deploying. After a few minutes, the model is deployed and the status changes to Active.
Step 6: Define Detectors
Once the model version is Active, define a detector so the GetEventPrediction API can be called through an endpoint. Your detectors reference the deployed model and version, and then configure actual outcome behaviours when fraud is suspected.
To define detectors, first configure decision rules, which you can base either on the raw data or the outputs of the training, known as “insights.” Each rule, when triggered, invokes one or more “outcomes.”
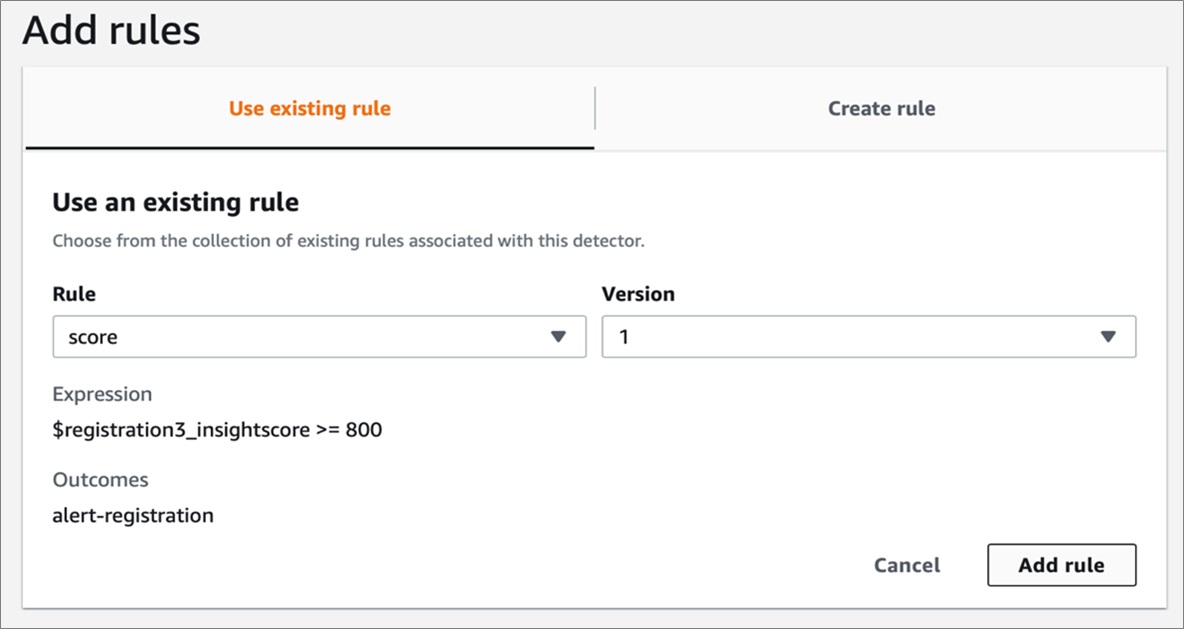
Figure 6 – Configuring rules as part of defining detectors.
You can create new outcomes or have multiple rules lead to the same outcome (for example, reject the account). Rules can lead to more than one outcome, which is a nice feature, but if outcomes need to change, keeping track of decisions can get complicated.
To avoid this confusion, we recommend you draw up a simple decision tree of this level of rules.
Step 6: Test the Model with Sample Data
Once all of this is done, your applications must submit events generated online to get back a prediction of potential fraud. Although you can define many detectors, only one can be Active at a time. You can have other versions in Draft form, or retain older detectors in an Inactive state within the service.
We found the versioning of models, detectors, and rules very powerful. We could also see how someone could lose track of all the versions. For instance, when you execute the detector API, you can either get back the first matched rule or all the matched rules.
A simple test form is incorporated in the service for the fundamental attributes along with the outcome, which is a string representing what action should be taken. There are three things you can do with an action—store it somewhere, raise it as an alarm, or develop a custom workflow to carry out other tasks.
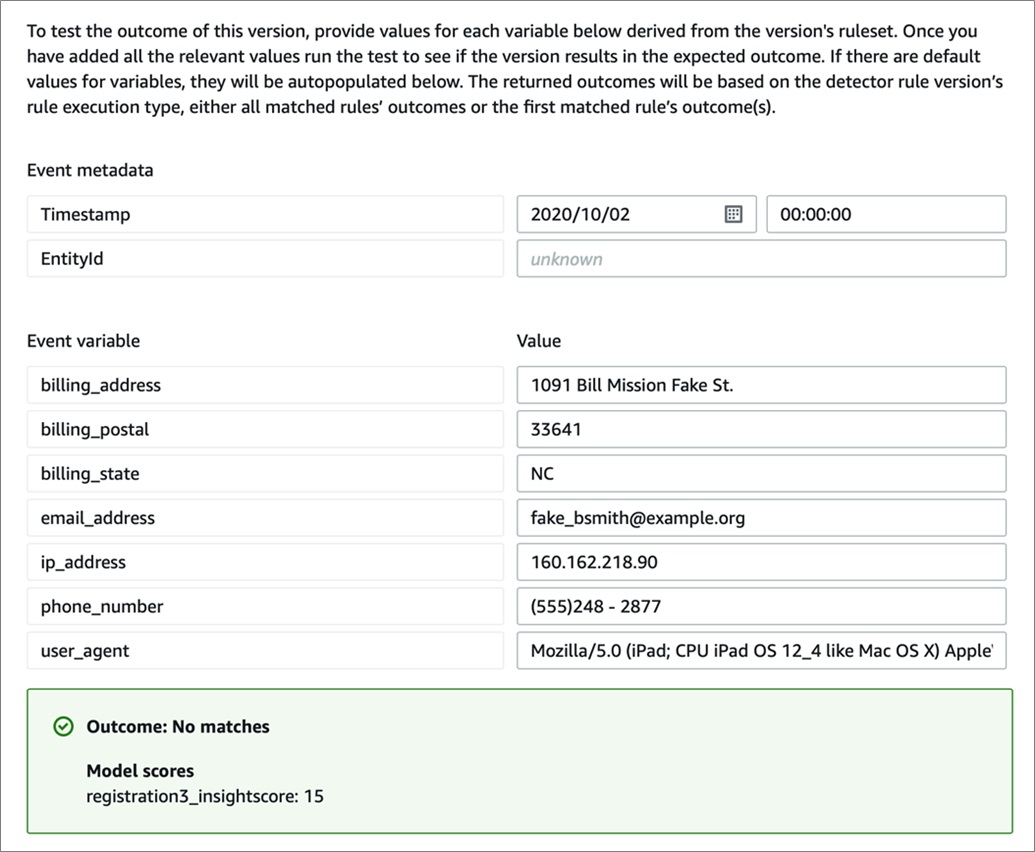
Figure 7 – Model outcome.
Integration and MLOps
Once deployed and tested, your model is ready to be integrated with whatever methods you chose as part of a wider solution. Once integrated, you’ll want to preform MLOps on your model.
Amazon Fraud Detector provides you with an array of metrics that are accessible via Amazon CloudWatch for you to be able todo this, including metrics for the number of predictions and latency of the inference, for example.
Currently, Amazon Fraud Detector does not provide an evaluation of the models’ predictions versus actual values to allow you to judge if the model has differed and needs retraining.
Considerations for Live Services
To avoid disrupting online users, inferences need to be returned with low latency. Typical detectors based on models return within 200 milliseconds at the 50th percentile, with rules-only detectors returning in about 140 milliseconds for rules only. As you would expect, the service auto scales under higher demand.
Check regularly the relevance of rules and freshness of the data, and retrain if necessary. Treat online fraud detection as part of a wider security strategy involving layers. For example, linking fraud detection rates to web application firewall (WAF) is a way of using strength in depth to give your website quality protection.
Practical Considerations
The Amazon Fraud Detector User Guide lists a number of conditions the data must meet. For instance, Amazon Fraud Detector handles missing data, but if any required column has more than 20 percent nulls, it issues a warning (90 percent in optional columns). Warnings are also shown if an optional field contains a single value.
The model fails if there are fewer than 10,000 rows, or less than 400 are labelled as positive for fraud. Timestamps are also crucial, so the model fails if more than 0.1 percent of values in “Event Timestamp” are invalid or null.
Recommendations
Based on our experience helping Inawisdom clients, we strongly recommend customers with online registrations that have experienced fraudulent activities to consider adding the Amazon Fraud Detector service.
The main criterion for using Amazon Fraud Detector is to have enough data from established and growing user bases. The service can quickly offer another layer of security in the fight against cybercrime, and the service can evolve and grow with your business.
If you would like some help with this, please contact us at info@inawisdom.com.
The content and opinions in this blog are those of the third party author and AWS is not responsible for the content or accuracy of this post.
.

.
Inawisdom – AWS Partner Spotlight
Inawisdom is an AWS Premier Consulting Partner that accelerates adoption of advanced analytics, artificial intelligence, and machine learning by providing a full-stack of AWS cloud and data services.
Contact Inawisdom | Practice Overview
*Already worked with Inawisdom? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.