AWS Partner Network (APN) Blog
Deploying a Data Lake in Minutes with Cloudwick’s Data Lake Foundation on AWS
September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details.
By Arun Kumar Palathumpattu Thankappan, Cloud Practices Lead at Cloudwick
 |
| Cloudwick |
 |
To gain the insights needed to fuel business growth, organizations need to collect more data and do more with it.
That’s where a data lake can help—it’s a repository that holds a large amount of raw data in its native (structured or unstructured) format until that data is needed, enabling you to accommodate virtually any use case.
Data lakes can be applied to any industry vertical and usually employ an ELT (extract, load, and transform) strategy, as compared to the more common ETL strategy employed in a traditional data warehouse, where the structure must be defined before data is loaded.
With a data lake, you don’t need to think through every possible use case ahead of time. You should include a data catalog, though, which I will get into a bit later.
So how can you build your own data lake and put it to use?
A while back, Cloudwick—an AWS Advanced Consulting Partner with the AWS Data & Analytics Competency—began offering a Data Lake Jumpstart to help customers deploy, pilot, and migrate into production a fully-functional data lake running on Amazon Web Services (AWS). This four-week engagement is a heavily-discounted program from both AWS and Cloudwick, with a typical cost of less than $20,000.
If you’d like to experiment with a data lake but aren’t ready for that kind of investment, check out our Data Lake Foundation on AWS Quick Start that we co-authored along with AWS Solutions Architects.
You can use this Quick Start to get your own data lake up and running in about 20 minutes. There are no consulting fees, and you won’t pay anything beyond the costs to run it on AWS.
In this post, I will provide a high-level overview of our Quick Start—and then drill down a bit deeper into the workings and value of the data catalog, which we implemented using Amazon OpenSearch Service (successor to Amazon Elasticsearch Service).
Check out Cloudwick’s Data Lake Foundation on AWS Quick Start >>
Architecture for the Data Lake Foundation on AWS Quick Start
At a high level, our Quick Start provides a data lake foundation that integrates various AWS services to help you migrate both structured and unstructured data from your on-premises environment to the AWS Cloud—and then store, monitor, and analyze the data.
Figure 1 provides a top-down architectural view, and a full description—including solution architecture, deployment options, and detailed deployment steps—can be found in the deployment guide.

Figure 1 – This Quick Start provides a data lake foundation to migrate structured and unstructured data.
After you deploy the data lake, you can use it to collect and combine multiple data sources and data types in Amazon Simple Storage Service (Amazon S3) with a unified view across all the data. This enables a path to ground truth—that is, information provided by direct observation and empirical evidence vs. information provided by inference—and provides a common repository for that information to be shared.
Here’s How it All Comes Together:
- When you launch the Quick Start, it sets up a virtual private cloud (VPC) that spans two Availability Zones (AZs) and includes two public and private subnets, along with an internet gateway. You can chose to create a new VPC or deploy into your existing VPC on AWS. If you choose the latter, the AWS CloudFormation template that deploys the Quick Start skips creating the VPC and internet gateway.
. - In the public subnets, managed NAT gateways allow outbound internet access for resources in the private subnets, and optional Linux bastion hosts in an Auto Scaling Group allow inbound Secure Shell (SSH) access to Amazon Elastic Compute Cloud (Amazon EC2) instances in the public and private subnets. This allows secure access to all the data lake components. Such a setup not only prevents unauthorized access to the data lake but enables integration with other components through NAT gateway.
. - Amazon Relational Database Service (Amazon RDS), which is also deployed in the private subnets, enables data migration from a relational database to Amazon Redshift using Amazon Data Pipeline. For ETL, we can also leverage AWS Glue.
. - In the private subnets, a web server instance (Amazon Machine Image, or AMI) in an Auto Scaling Group hosts the data lake portal. This web server also installs Zeppelin to run analytics on the data loaded into Amazon S3.
. - AWS Lambda is used to index the metadata from different data sources into Amazon OpenSearch Service. This enables indexing the data flowing into the data lake at scale, without human intervention, and provides visibility into the data. We also use Zeppelin for ad hoc and exploratory data analysis.
. - AWS Identity and Access Management (IAM) roles are used to manage permissions to access AWS resources—such as accessing the data in Amazon S3, enabling Amazon Redshift to copy data from S3 into its tables, and associating the generated IAM role with the Redshift cluster.
. - The other key services being used are Auto Scaling and Elastic Load Balancing (ELB). Both of these services are important pillars of a well-architected application in cloud. Auto Scaling, for example, allows Amazon EC2 capacity to scale out or scale in as per demand, while ELB allows the traffic to be spread across the Amazon EC2 fleet. ELBs support multiple types—Application, Network and Classic Load Balancing—and depending on the application use case, customers can pick up the Load Balancers.
The Value of a Data Catalog and Why We Used Amazon ES
Let’s talk about the data catalog, which is supported through our use of Amazon OpenSearch Service. The variety, velocity, and veracity of data that flows into your data lake can be vast, which is why a strong data management layer is required. The data catalog is at the core of this layer and, as such, is the number one component to consider when architecting a data lake.
But why is the data catalog so important? Remember, the beauty of a data lake is that you don’t need to think through every possible use case up front.
To use the data you collect effectively, however, you’ll need to capture metadata to identify which data streams are coming into your data lake, where they come from, their format, and other aspects. Amazon ES does just that, automatically indexing the data that flows into your data lake and making it available via a simple search.
The diagram in Figure 2 shows how this indexing is performed:
- Files can flow into Amazon S3 through any channel.
- File creation in Amazon S3 produces an event you can catch with a Lambda function.
- The Lambda function retrieves data and metadata from Amazon S3, and pushes it into OpenSearch.
- Using Direct OpenSearch API calls or, at a larger scale, Amazon Kinesis Data Firehose can be used to populate OpenSearch. You can also use Logstash, which is a data-collection and log-parsing engine.
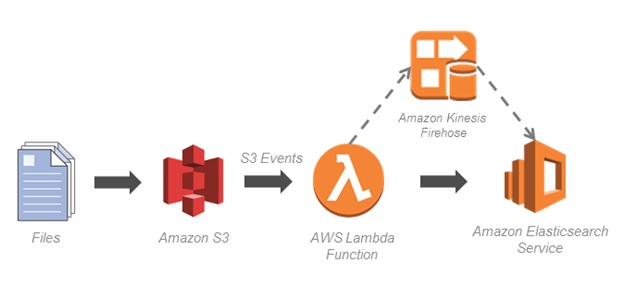
Figure 2 – This architecture offers a versatile means of collecting different types of information.
Because the data catalog is indexed, searches are very fast. More importantly, the data catalog makes information in the data lake easy to discover and is accessible by many users, not just the people who built it. The data catalog also gives your data scientists, business analysts, and other users unencumbered, self-service access to the information without the need for highly specialized technical assistance.
Because Amazon OpenSearch Service includes Kibana, those users can visualize the content that’s indexed on an OpenSearch cluster in powerful ways. In addition, Amazon OpenSearch Service captures and indexes all API calls to the data lake, giving you a full audit record of who accessed what.
At this point, you may be asking, “I get the value of Elasticsearch, but what’s the difference between Elasticsearch—an open source offering—and Amazon OpenSearch Service?” Put simply, Amazon OpenSearch Service makes it easy to deploy, secure, operate, and scale Elasticsearch for log analytics, full text search, application monitoring, and more.
As a fully managed service, Amazon OpenSearch Service provides all the capabilities of Elasticsearch alongside the availability, scalability, and security that production workloads require. It even includes built-in integrations with Kibana, Logstash, and AWS services such as Amazon VPC, Amazon Kinesis Data Firehose, AWS Lambda, and Amazon CloudWatch—enabling you to go from raw data to actionable insights very quickly.
Summary
Do you absolutely need a built-in data catalog like the one we implemented using Amazon OpenSearch Service? In my opinion, yes.
I often come across companies with data lakes that lack such capabilities, and they suffer from a damaging lack of visibility into data sources, data formats, frequency of data capture, and other aspects of their data. They often have this information somewhere, but it is stored in a place where it is not useful or accessible.
A data catalog based on Amazon OpenSearch Service automatically captures and surfaces what’s in your data lake, making it infinitely more valuable when it comes to why you built it in the first place: to uncover the insights needed to fuel business growth.
Next Steps
Check out our Data Lake Foundation on AWS Quick Start >>
AWS Solution Space features many customer-ready solutions, including Cloudwick’s Data Lake Foundation on AWS. Discover value from this solution by gaining access to AWS credits to support a Proof-of-Concept (POC) and special consulting offers that include AWS co-investments.
The content and opinions in this blog are those of the third party author and AWS is not responsible for the content or accuracy of this post.
.

.
Cloudwick – AWS Partner Spotlight
Cloudwick is an AWS Data & Analytics Competency Partner that enables enterprises to gain competitive advantage from open source, big data, cloud, and advanced analytics.
Contact Cloudwick | Partner Overview
*Already worked with Cloudwick? Rate this Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.