AWS Partner Network (APN) Blog
SaaS Storage Partitioning with Amazon Aurora Serverless
By Tod Golding, Partner Solutions Architect at AWS
Storage partitioning is always a challenging topic for Software-as-a-Service (SaaS) developers. For SaaS environments, you must find some way to effectively and efficiently partition tenant data while still being mindful of the complex scaling and cost optimization needs that SaaS demands.
This can be particularly challenging when you are working with relational databases, where your partitioning strategy must also consider how the instances running these databases can address the scaling requirements of a multi-tenant workload.
With the introduction of Amazon Aurora Serverless (currently in preview), SaaS providers are now equipped with a model to bring the scale and cost efficiency of serverless computing directly to storage partitioning models of SaaS solutions.
In this post, we take a closer look at how Aurora Serverless works and how it influences your approach to storage partitioning in SaaS environments. The goal here is to highlight the implications of the serverless storage model, identifying key areas that will be of particular interest to SaaS developers.
The SaaS Partitioning Challenge
To understand the value and power of Aurora Serverless, we must first look at how SaaS developers currently implement data partitioning with relational databases. Partitioning is typically achieved via a few common schemes. The first option, shown in Figure 1, is to create a separate database instance for each tenant. This is referred to as a “siloed” storage model.
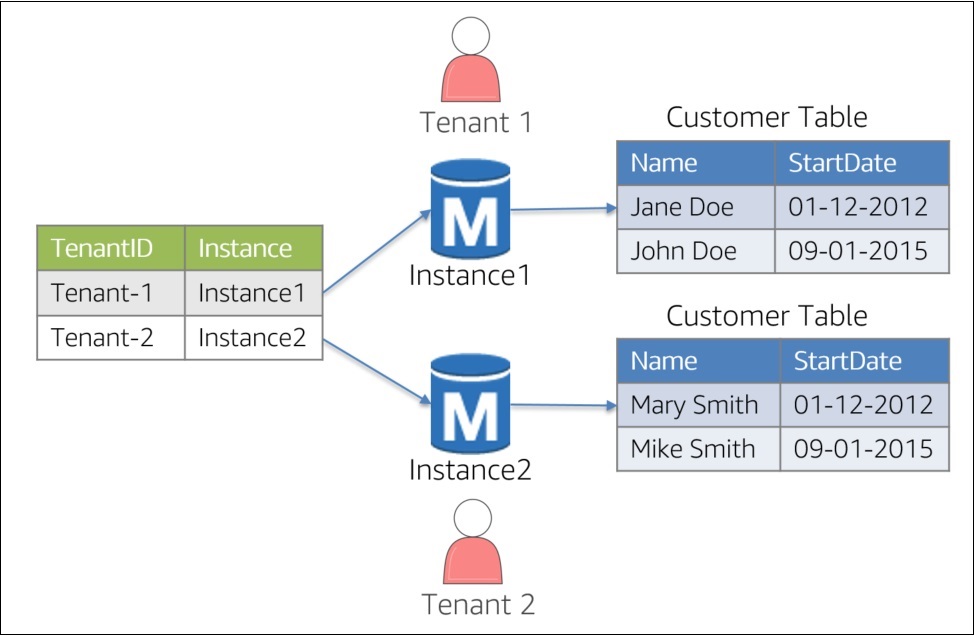
Figure 1 – Siloed Instances
The basic idea is that each tenant has its own dedicated instance. Access to the data is then resolved though some mapping construct (shown on the left). This strategy is particularly common in SaaS environments where customers demand a high degree of data isolation.
While the siloed model has its merits, it can be more challenging to manage and can undermine the agility and cost of SaaS environments. As an alternative, some SaaS teams will use what is referred to as a “pooled” model where all tenant data resides within a single database instance. The diagram in Figure 2 represents a simplified view of a pooled configuration.
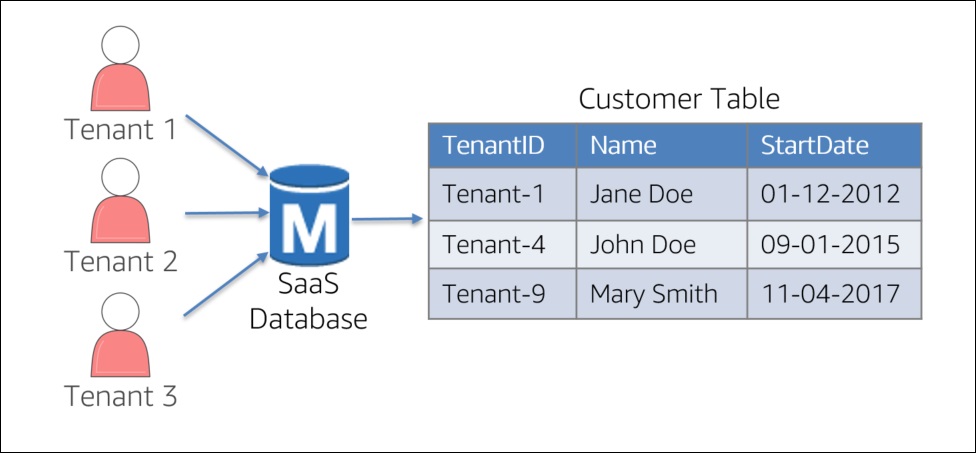
Figure 2 – Pooled Partitioning
The key difference with this approach is that we must introduce a tenant identifier into the data to determine which data belongs to which tenants. This strategy simplifies the management and data migration models for your environment, often improving the overall agility of your solution.
You’ll notice that all tenants must be processed through a shared database instance. This instance must be sized to accommodate the varying loads and data footprints of each of a system’s tenants. While you get some operational and management efficiency out of this approach, you also create a potential bottleneck at this instance level. This often forces you to over-provision the size of your database instance to limit the potential for bottlenecks.
There are creative ways to counteract this problem. One approach is to add some intelligence to your partitioning model by analyzing load and activity in an attempt to better distribute the load placed on any one instance. However, this adds a degree of complexity to your overall solution.
The Heart of the Problem
Given this backdrop and the partitioning schemes we outlined, you can see how SaaS, by its nature, can push the limits of any one database instance. The fundamental challenge we face here is that any approach we take still binds us to a computing instance. Yes, you can be clever about how you distribute that load, but you still must select an instance with some size that approximates the maximum load your tenant(s) demand.
This dependence on a server also has a cascading impact on the efficiency and cost of your SaaS environment. While our goal with SaaS is to always size dynamically based on actual tenant load, the servers for multi-tenant database instances require us to over-provision, artificially increasing the costs of your SaaS environments.
Aurora Serverless to the Rescue
In looking at the nature of the problem, it’s clear that our biggest challenge is that we simply have no way to avoid the fact that SaaS databases—no matter how we set them up—cannot really be treated like on-demand resources. This need to detach ourselves from the physical servers is exactly the problem that is being targeted by Aurora Serverless.
With Aurora Serverless, developers can adopt the same mindset and values they do for serverless compute environments. This enables Aurora to offer all the scale and power it has today without any awareness of the underlying instances that are being used to manage our data.
The diagram in Figure 3 provides a high-level view of the Aurora Serverless model. You’ll notice the instances that were part of our previous partitioning model have been replaced by a serverless proxy layer that sits between you and your Aurora databases.

Figure 3 – Aurora Serverless Model
The proxy layer added by Aurora Serverless is at the core of enabling your ability to detach your solution from any awareness of Aurora instances. This layer manages all of your database connections and presents the surface that is the façade for all of your interactions with the underlying data. This is achieved without adding additional complexity to the development experience. As instances are swapped in and the out on the other side of the proxy, the connections being used by your code will gracefully and transparently make this transition.
With the proxy layer in place, Aurora Serverless has a natural mechanism for managing the compute resources needed to process your current load. With instances removed from the equation, Aurora Serverless can dynamically assess the activity in your system and determine how much compute is needed based the actual system load.
Behind the proxy, Aurora Serverless includes new mechanisms to ensure your solution sizes itself efficiently and dynamically. This is achieved through the introduction of a new pooling model that enables Aurora Serverless to rapidly add resources on the fly. Figure 4 provides a conceptual representation of these pooled Aurora resources.

Figure 4 – Pooled Aurora Resources
The pool (shown on the right) represents a warm fleet of instances that can be easily swapped in to add capacity to your environment. These instances are allocated in a range of sizes, providing Aurora Serverless with a more granular approach to how it responds to variations in load. In fact, if there is no storage activity on your system, Aurora Serverless will actually pause your cluster.
Aurora Serverless can also reduce the fundamental complexity of our SaaS environments. Gone is the need to profile and partition storage instances based on our own profiling and analytics. Instead, you can now rely on Aurora to effectively distribute the compute load of your system.
SaaS Scaling Efficiency
As you can imagine, the introduction of this proxy layer in Aurora Serverless directly addresses the SaaS partitioning challenges outlined earlier in the post. Now, with instances out of the equation, your SaaS architecture no longer has to concern itself with matching instance sizes with the unpredictable loads of your multi-tenant data.
With this ability to scale and swap the instance dynamically, Aurora Serverless can assess the current load on my system and match that with the appropriate amount of computing resources. Ultimately, what this model gives us is the ability to scale up and the scale down in way that accommodates the variations so commonly seen in SaaS environments. This level of optimization was simply not achievable without the introduction of a serverless model.
Cost Optimization
The move to a serverless model also has a positive impact on the cost footprint of your SaaS applications. The removal of instances from the equation enabled Aurora Serverless to offer a true consumption-based pricing model where your bill is derived from actual activity (instead of provisioned instances).
You can imagine just how appealing this is to SaaS providers since these environments may often cycles where Aurora load may be fairly minimal at certain times of the day.
SaaS and Serverless: A Natural Intersection
Serverless computing has already gained momentum. Developers see real value in the building, deployment, management, security, and cost value proposition of this model. Now, as these values extend their reach into the database universe, we are seeing new and interesting ways that serverless can improve the scale, performance, and cost footprint of our multi-tenant storage strategies.
The serverless database model can be very compelling for SaaS providers who are looking for a more effective model for supporting the dynamic nature of SaaS workloads. Aurora Serverless equips SaaS architects with new tools and strategies for dealing with the challenges of multi-tenant data and varying user activity, freeing you up to focus on the functional aspects of a solution.

About AWS SaaS Factory
AWS SaaS Factory helps organizations at any stage of the SaaS journey. Whether looking to build new products, migrate existing applications, or optimize SaaS solutions on AWS, we can help. Visit the AWS SaaS Factory Insights Hub to discover more technical and business content and best practices.
SaaS builders are encouraged to reach out to their account representative to inquire about engagement models and to work with the AWS SaaS Factory team.
Sign up to stay informed about the latest SaaS on AWS news, resources, and events.