AWS News Blog
Amazon Redshift – Up to 2X Throughput and 10X Vacuuming Performance Improvements
My colleague Maor Kleider wrote today’s guest post!
— Jeff;
Amazon Redshift, AWS’s fully managed data warehouse service, makes petabyte-scale data analysis fast, cheap, and simple. Since launch, it has been one of AWS’s fastest growing services, with many thousands of customers across many industries. Enterprises such as NTT DOCOMO, NASDAQ, FINRA, Johnson & Johnson, Hearst, Amgen, and web-scale companies such as Yelp, Foursquare and Yahoo! have made Amazon Redshift a key component of their analytics infrastructure.
In this blog post, we look at performance improvements we’ve made over the last several months to Amazon Redshift, improving throughput by more than 2X and vacuuming performance by 10X.
Column Store
Large scale data warehousing is largely an I/O problem, and Amazon Redshift uses a distributed columnar architecture to minimize and parallelize I/O. In a column-store, each column of a table is stored in its own data block. This reduces data size, since we can choose compression algorithms optimized for each type of column. It also reduces I/O time during queries, because only the columns in the table that are being selected need to be retrieved.
However, while a column-store is very efficient at reading data, it is less efficient than a row-store at loading and committing data, particularly for small data sets. In patch 1.0.1012 (December 17, 2015), we released a significant improvement to our I/O and commit logic. This helped with small data loads and queries using temporary tables. While the improvements are workload-dependent, we estimate the typical customer saw a 35% improvement in overall throughput.
 Regarding this feature, Naeem Ali, Director of Software Development, Data Science at Cablevision, told us:
Regarding this feature, Naeem Ali, Director of Software Development, Data Science at Cablevision, told us:
Following the release of the I/O and commit logic enhancement, we saw a 2X performance improvement on a wide variety of workloads. The more complex the queries, the higher the performance improvement.
Improved Query Processing
In addition to enhancing the I/O and commit logic for Amazon Redshift, we released an improvement to the memory allocation for query processing in patch 1.0.1056 (May 17, 2016), increasing overall throughput by up to 60% (as measured on standard benchmarks TPC-DS, 3TB), depending on the workload and the number of queries that spill from memory to disk. The query throughput improvement increases with the number of concurrent queries, as less data is spilled from memory to disk, reducing required I/O.
Taken together, these two improvements, should double performance for customer workloads where a portion of the workload contains complex queries that spill to disk or cause temporary tables to be created.
Better Vacuuming
Amazon Redshift uses multi-version concurrency control to reduce contention between readers and writers to a table. Like PostgreSQL, it does this by marking old versions of data as deleted and new versions as inserted, using the transaction ID as a marker. This allows readers to build a snapshot of the data they are allowed to see and traverse the table without locking. One issue with this approach is the system becomes slower over time, requiring a vacuum command to reclaim the space. This command reclaims the space from deleted rows and ensures new data that has been added to the table is placed in the right sorted order.
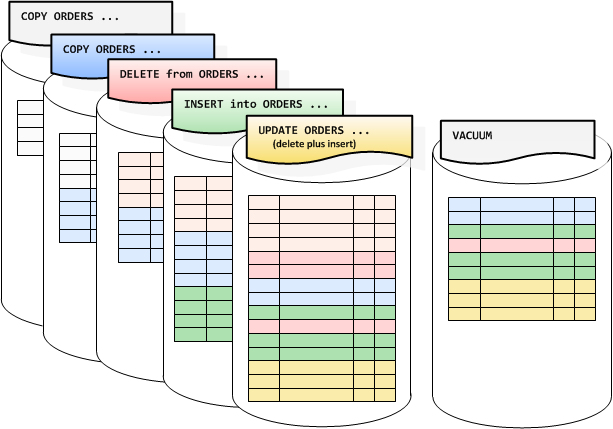
We are releasing a significant performance improvement to vacuum in patch 1.0.1056, available starting May 17, 2016. Customers previewing the feature have seen dramatic improvements both in vacuum performance and overall system throughput as vacuum requires less resources.
 Ari Miller, a Principal Software Engineer at TripAdvisor, told me:
Ari Miller, a Principal Software Engineer at TripAdvisor, told me:
We estimate that the vacuum operation on a 15TB table went about 10X faster with the recent patch, ultimately improving overall query performance.
Available Now
Unlike on-premise data warehousing solutions, there are no license or maintenance fees for these improvements or work required on your part to obtain them. They simply show up as part of the automated patching process during your maintenance window.
— Maor Kleider, Senior Product Manager, Amazon Redshift