AWS News Blog
AWS Storage Gateway Recap – SMB Support, RefreshCache Event, and More

|
To borrow my own words, the AWS Storage Gateway is a service that includes a multi-protocol storage appliance that fits in between your existing application and the AWS Cloud. Your applications see the gateway as a file system, a local disk volume, or a Virtual Tape Library, depending on how it was configured.
Today I would like to share a few recent updates to the File Gateway configuration of the Storage Gateway, and also show you how they come together to enable some new processing models. First, the most recent updates:
SMB Support – The File Gateway already supports access from clients that speak NFS (versions 3 and 4.1 are supported). Last month we added support for the Server Message Block (SMB) protocol. This allows Windows applications that communicate using v2 or v3 of SMB to store files as objects in S3 through the gateway, enabling hybrid cloud use cases such as backup, content distribution, and processing of machine learning and big data workloads. You can control access to the gateway using your existing on-premises Active Directory (AD) domain or a cloud-based domain hosted in AWS Directory Service, or you can use authenticated guest access. To learn more about this update, read AWS Storage Gateway Adds SMB Support to Store and Access Objects in Amazon S3 Buckets.
Cross-Account Permissions – Some of our customers run their gateways in one AWS account and configure them to upload to an S3 bucket owned by another account. This allows them to track departmental storage and retrieval costs using chargeback and showback models. In order to simplify this important use case, you can configure the gateway to provide the bucket owner with full permissions. This avoids a pain point which could arise if the bucket owner was unable to see the objects. To learn how to set this up, read Using a File Share for Cross-Account Access.
Requester Pays – Bucket owners are responsible for storage costs. Owners pay for data transfer costs by default, but also have the option to have the requester pay. To support this use case, the File Gateway now supports S3’s Requester Pays Buckets. Data collectors and aggregators can use this feature to share data with research organizations such as universities and labs without incurring the costs of access themselves. File Gateway provides file based access to the S3 objects, caches recently accessed data locally, helping requesters reduce latency and costs. To learn more, read about Creating an NFS File Share and Creating an SMB File Share.
File Upload Notification – The gateway caches files locally, and uploads them to a designated S3 bucket in the background. Late last year we gave you the ability to request notification (in the form of a CloudWatch Event) when new files have been uploaded. You can use this to initiate cloud-based processing or to implement advanced logging. To learn more, read Getting File Upload Notification and study the NotifyWhenUploaded function.
Cache Refresh Event – You have long had the ability to use the RefreshCache function to make sure that the gateway is aware of objects that have been added, removed, or replaced in the bucket. The new Storage Gateway Cache Refresh Event lets you know that the cache is now in sync with S3, and can be used as a signal to initiate local processing. To learn more, read Getting Refresh Cache Notification.
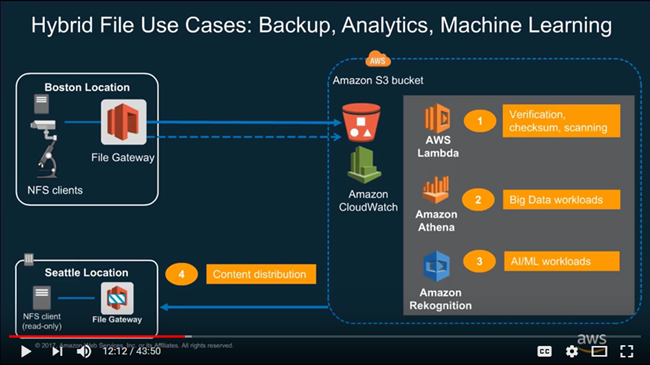
Hybrid Processing Using File Gateway
You can use the File Upload Notification and Cache Refresh to automate some of your routine hybrid process tasks!
Let’s say that you run a geographically distributed office or retail business, with locations all over the world. Raw data (metrics, cash register receipts, or time sheets) is collected at each location, and then uploaded to S3 using a File Gateway hosted at each location. As the data arrives, you use the File Upload Notifications to process each S3 object, perhaps using an AWS Lambda function that invokes Amazon Athena to run a stock set of queries against each one. The data arrives over the course of a couple of hours, and results accumulate in another bucket. At the end of the reporting period, the intermediate results are processed, custom reports are generated for each branch location, and then stored in another bucket (this bucket, as it turns out, is also associated with a gateway, and each gateway will have cached copies of the prior versions of the reports). After you generate your reports, you can refresh each of the gateway caches, wait for the corresponding notifications, and then send an email to the branch managers to tell them that their new report is available.
Here’s a video (and presentation) with more information about this processing model:
Now Available
All of the features listed above are available now and you can start using them today in all regions where Storage Gateway is available.
— Jeff;