Category: Amazon RDS
Amazon RDS Update – PostgreSQL 9.4.1 Now Available
Amazon Relational Database Service (RDS) makes it easy for you to set up, operate, and scale a MySQL, PostgreSQL, SQL Server, or Oracle relational database in the cloud.
Today we are adding support for version 9.4.1 of PostgreSQL to RDS. Among other features, this version allows you to store JSON data in a compact, decomposed binary format known as jsonb. Data stored in this format is significantly faster to process and can also be indexed. It does not preserve extraneous white space or the textual order of keys within objects. For more information, read the PostgreSQL documentation on JSON Types.
You can launch an RDS Database Instance running this version of PostgreSQL from the RDS Console, RDS APIs, or the AWS Command Line Interface (CLI). Here’s how you do it from the Console:
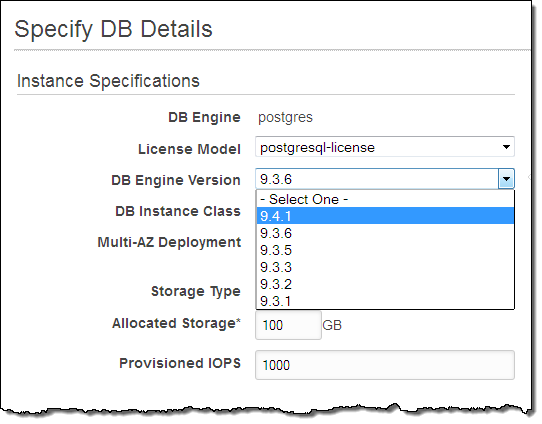
The new support for jsonb data will give you the power to create applications that make use of data that consists of a combination of static fields that are well known and dynamic values (perhaps from external applications or devices) that are not fully known or understood in advance.
This new version of PostgreSQL is available now and you can start using it today. In order to upgrade, you will need to create a SQL dump, launch a new instance that is running 9.4.1, and then restore the dump.
To learn more about the full set of enhancements and bug fixes that are present in the 9.4 series, take a look at the release notes.
— Jeff;
Data Encryption Made Easier – New Encryption Options for Amazon RDS
Encryption of stored data (often referred to as “data at rest”) is an important part of any data protection plan. Today we are making it easier for you to encrypt data at rest in Amazon Relational Database Service (RDS) database instances running MySQL, PostgreSQL, and Oracle Database.
Before today’s release you had the following options for encryption of data at rest:
- RDS for Oracle Database – AWS-managed keys for Oracle Enterprise Edition (EE).
- RDS for SQL Server – AWS-managed keys for SQL Server Enterprise Edition (EE).
In addition to these options, we are adding the following options to your repertoire:
- RDS for MySQL – Customer-managed keys using AWS Key Management Service (KMS).
- RDS for PostgreSQL – Customer-managed keys using AWS Key Management Service (KMS).
- RDS for Oracle Database – Customer-managed keys for Oracle Enterprise Edition using AWS CloudHSM.
For all of the database engines and key management options listed above, encryption (AES-256) and decryption are applied automatically and transparently to RDS storage and to database snapshots. You don’t need to make any changes to your code or to your operating model in order to benefit from this important data protection feature.
Let’s take a closer look at all three of these options!
Customer-Managed Keys for MySQL and PostgreSQL
We launched the AWS Key Management Service last year at AWS re:Invent. As I noted at the time, KMS provides you with seamless, centralized control over your encryption keys. It was designed to help you to implement key management at enterprise scale with facility to create and rotate keys, establish usage policies, and to perform audits on key usage (visit the AWS Key Management Service (KMS) home page for more information).
You can enable this feature and start to use customer-managed keys for your RDS database instances running MySQL or PostgreSQL with a couple of clicks when you create a new database instance. Turn on Enable Encryption and choose the default (AWS-managed) key or create your own using KMS and select it from the dropdown menu:
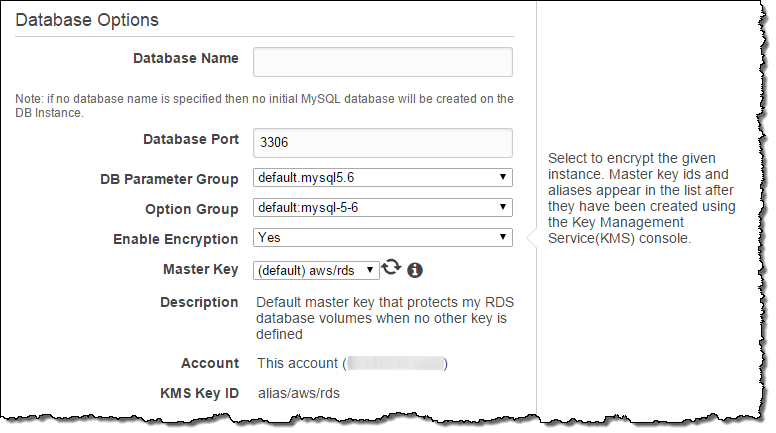
That’s all it takes to start using customer-managed encryption for your MySQL or PostgreSQL database instances. To learn more, read the documentation on Encrypting RDS Resources.
Customer-Managed Keys for Oracle Database
AWS CloudHSM is a service that helps you to meet stringent compliance requirements for cryptographic operations and storage of encryption keys by using single tenant Hardware Security Module (HSM) appliances within the AWS cloud.
CloudHSM is now integrated with Amazon RDS for Oracle Database. This allows you to maintain sole and exclusive control of the encryption keys in CloudHSM instances when encrypting RDS database instances using Oracle Transparent Data Encryption (TDE).
You can use the new CloudHSM CLI tools to configure groups of HSM appliances in order to ensure that RDS and other applications that use CloudHSM keep running as long as one HSM in the group is available. For example, the CLI tools allow you to clone keys from one HSM to another.
To learn how to use Oracle TDE in conjunction with a CloudHSM, please read our new guide to Using AWS CloudHSM with Amazon RDS.
Available Now
These features are available now and you can start using them today!
— Jeff;
Resource Groups and Tagging for AWS
For many years, AWS customers have used tags to organize their EC2 resources (instances, images, load balancers, security groups, and so forth), RDS resources (DB instances, option groups, and more), VPC resources (gateways, option sets, network ACLS, subnets, and the like) Route 53 health checks, and S3 buckets. Tags are used to label, collect, and organize resources and become increasingly important as you use AWS in larger and more sophisticated ways. For example, you can tag relevant resources and then take advantage AWS Cost Allocation for Customer Bills.
Today we are making tags even more useful with the introduction of a pair of new features: Resource Groups and a Tag Editor. Resource Groups allow you to easily create, maintain, and view a collection of resources that share common tags. The new Tag Editor allows you to easily manage tags across services and Regions. You can search globally and edit tags in bulk, all with a couple of clicks.
Let’s take a closer look at both of these cool new features! Both of them can be accessed from the new AWS menu:
Tag Editor
Until today, when you decided to start making use of tags, you were faced with the task of stepping through your AWS resources on a service-by-service, region-by-region basis and applying tags as needed. The new Tag Editor centralizes and streamlines this process.
Let’s say I want to find and then tag all of my EC2 resources. The first step is to open up the Tag Editor and search for them:
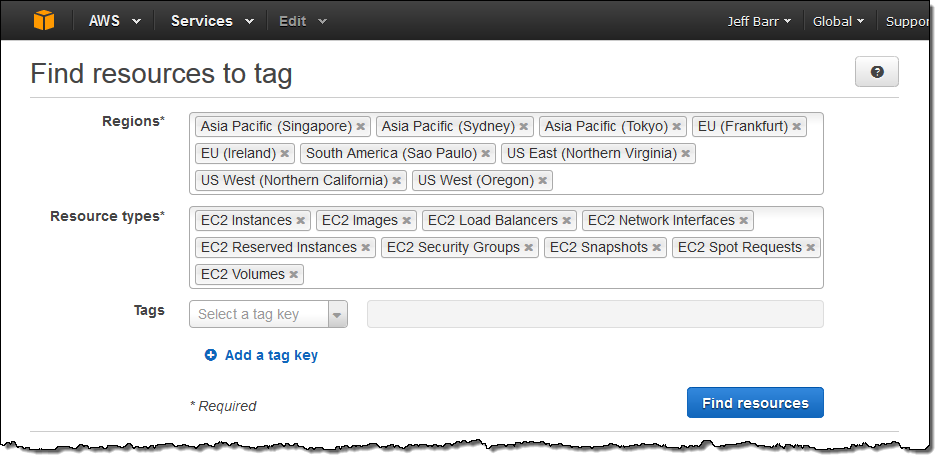
The Tag Editor searches my account for the desired resource types across all of the selected Regions and then displays all of the matches:
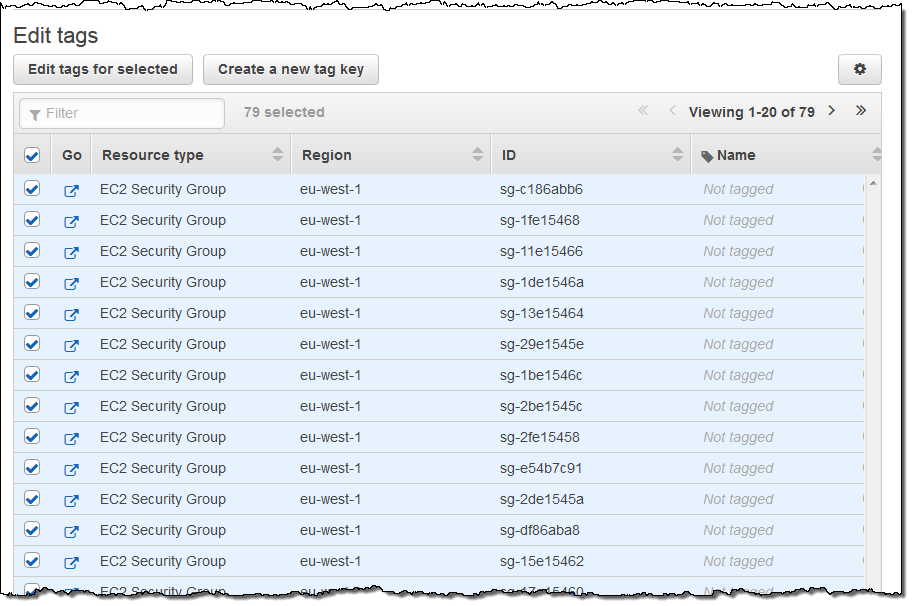
I can then select all or some of the resources for editing. When I click on the Edit tags for selected button, I can see and edit existing tags and add new ones. I can also see existing System tags:
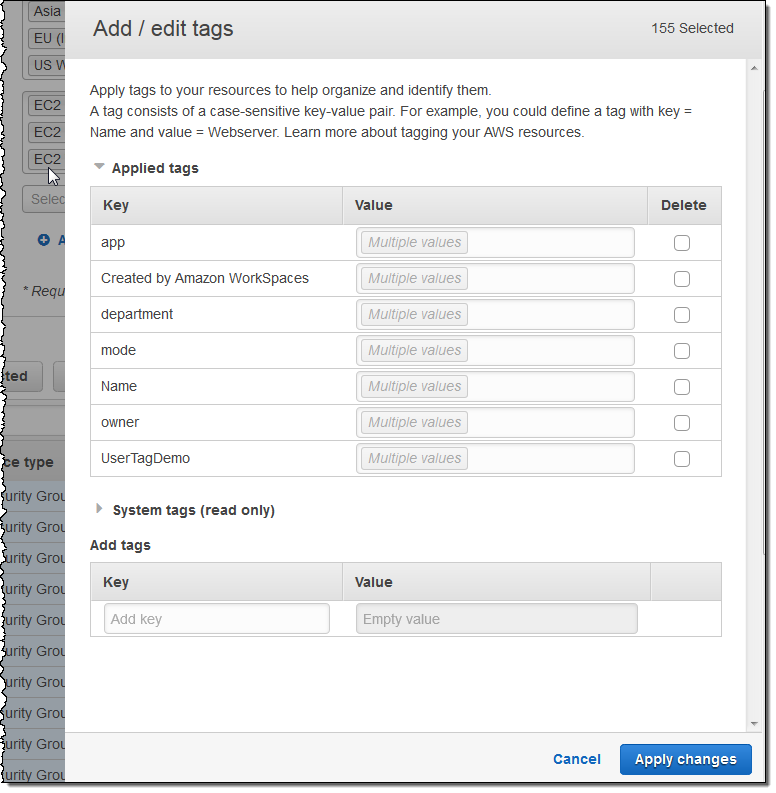
I can see which values are in use for a particular tag by simply hovering over the Multiple values indicator:
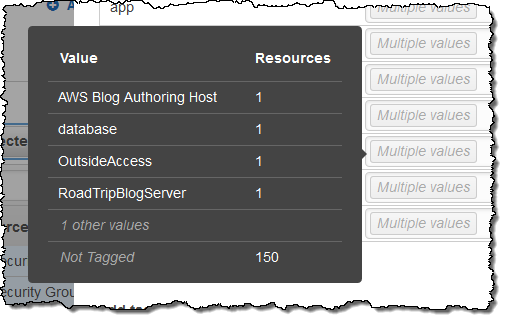
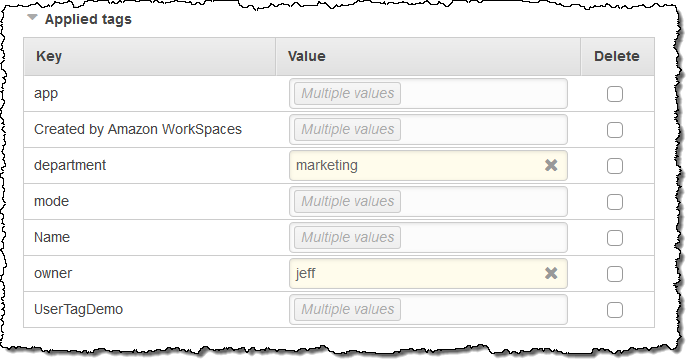
I can change multiple tags simultaneously (changes take effect when I click on Apply changes):
Resource Groups
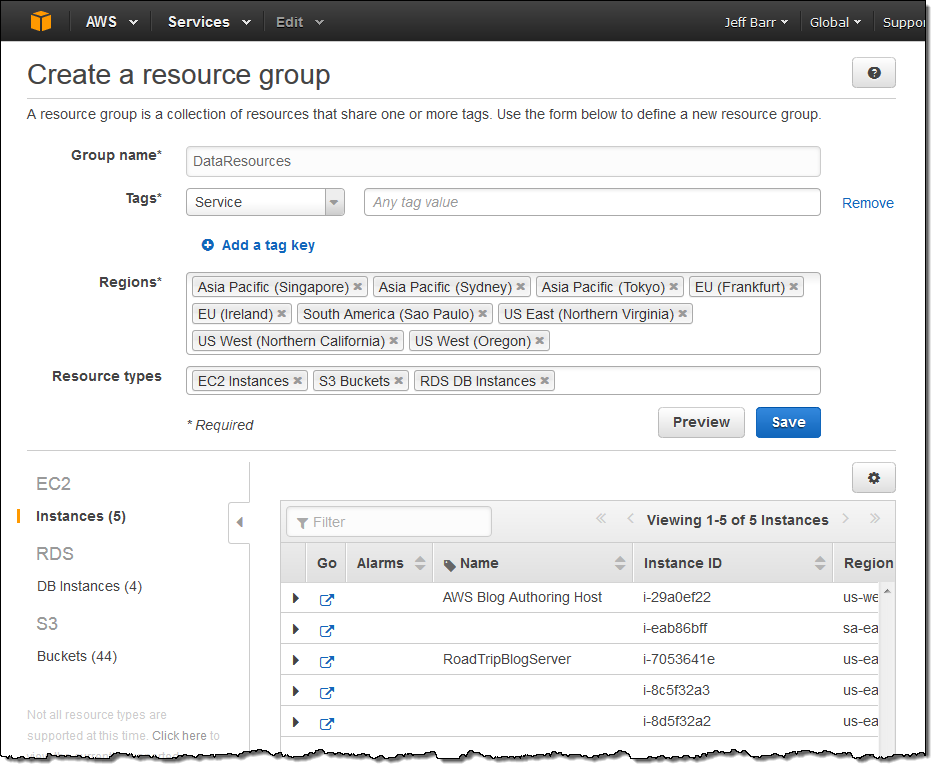
A Resource Group is a collection of resources that shares one or more tags. It can span Regions and services and can be used to create what is, in effect, a custom console that organizes and consolidates the information you need on a per-project basis.
You can create a new Resource Group with a couple of clicks. I tagged a bunch of my AWS resources with Service and then added the EC2 instances, DB instances, and S3 buckets to a new Resource Group:
My Resource Groups are available from within the AWS menu:
Selecting a group displays information about the resources in the group, including any alarm conditions (as appropriate):
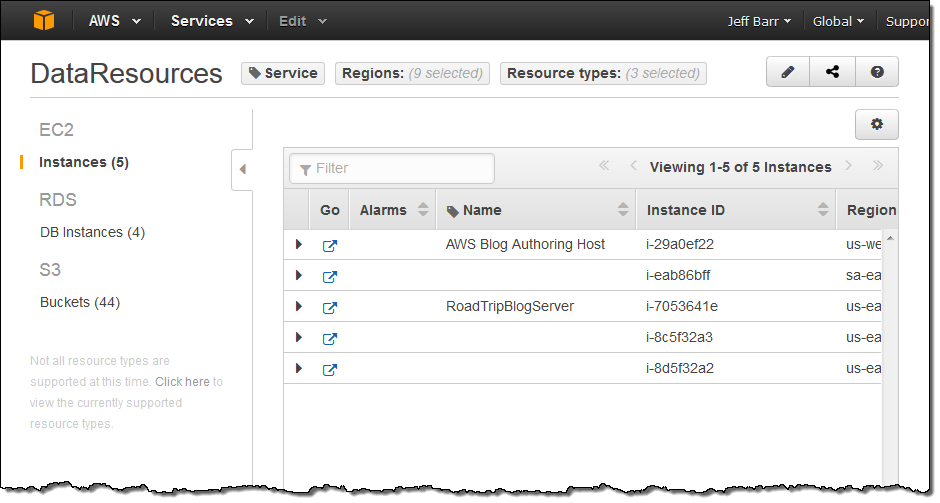
This information can be further expanded:
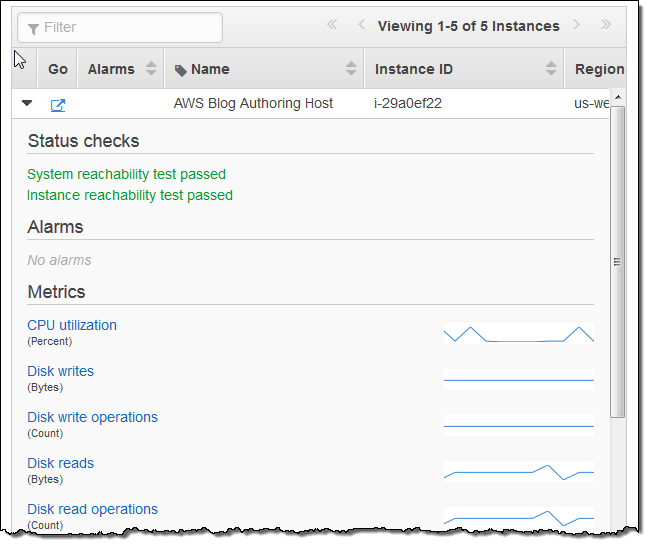
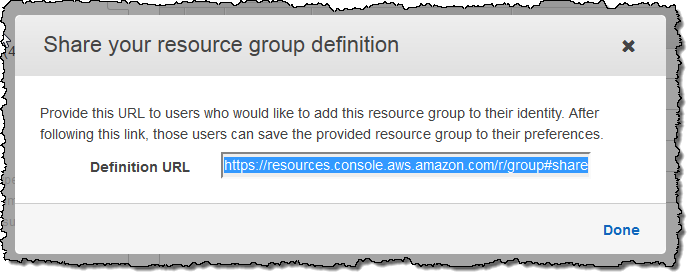
Each identity within an AWS account can have its own set of Resource Groups. They can be shared between identities by clicking on the Share icon:
Down the Road
We are, as usual, very interested in your feedback on this feature and would love to hear from you! To get in touch, simply open up the Resource Groups Console and click on the Feedback button.
Available Now
Resource Groups and the Tag Editor are available now and you can start using them today!
— Jeff;
Amazon Aurora – New Cost-Effective MySQL-Compatible Database Engine for Amazon RDS
We launched the Amazon Relational Database Service (RDS) service way back in 2009 to help you to set up, operate, and scale a MySQL database in the cloud. Since that time, we have added a multitude of options to RDS including extensive console support, three additional database engines ( Oracle, SQL Server, and PostgreSQL), high availability (multiple Availability Zones) and dozens of other features.
We have come a long way in five years, but there’s always room to do better! The database engines that I listed above were designed to function in a constrained and somewhat simplistic hardware environment — a constrained network, a handful of processors, a spinning disk or two, and limited opportunities for parallel processing or a large number of concurrent I/O operations.
The RDS team decided to take a fresh look at the problem and to create a relational database designed for the cloud. Starting from a freshly scrubbed white board, they set as their goal a material improvement in the price-performance ratio and the overall scalability and reliability of existing open source and commercial database engines. They quickly realized that they had a unique opportunity to create an efficient, integrated design that encompassed the storage, network, compute, system software, and database software, purpose-built to handle demanding database workloads. This new design gave them the ability to take advantage of modern, commodity hardware and to eliminate bottlenecks caused by I/O waits and by lock contention between database processes. It turned out that they were able to increase availability while also driving far more throughput than before.
Amazon Aurora – New MySQL-Compatible Database Engine
Today we are launching Aurora, is a fully-managed, MySQL-compatible, relational database engine that combines the speed and availability of high-end commercial databases with the simplicity and cost-effectiveness of open source databases.
When you use Amazon Aurora, you’ll spend less time managing and tuning your database, leaving you with more time to focus on building your application and your business. As your business grows, Amazon Aurora will scale with you. You won’t need to take your application off line in order to add storage. Instead, Amazon Aurora will add storage in 10 GB increments on as as-needed basis, all the way up to 64 TB. Baseline storage performance is rapid, reliable and predictable—it scales linearly as you store more data, and allows you to burst to higher rates on occasion. You can scale the instance size in minutes and you can add replicas with a couple of clicks.
Storage is automatically replicated across three AWS Availability Zones (AZs) for durability and high availability, with two copies of the data in each Availability Zone. This two-dimensional redundancy (within and across Availability Zones) allows Amazon Aurora to make use of quorum writes. Instead of waiting for all writes to finish before proceeding, Amazon Aurora can move ahead as soon as at least 4 of 6 writes are complete. Storage is allocated in 10 GB blocks distributed across a large array of SSD-powered storage. This eliminates hot spots and allows for a very high degree of concurrent access, while also being amenable to self-healing. In fact, Amazon Aurora can tolerate the loss of two copies of the data while it is handling writes and three copies of the data while it is handling reads. This scatter-write model also allows for very efficient and rapid backup to Amazon Simple Storage Service (S3). Because the writes take advantage of any available free space, backups are highly parallelized and do not impose any load on the database instance. In the event that a database instance fails, Amazon Aurora will make an attempt to recover to a healthy AZ with no data loss. Amazon Aurora also makes continuous, instantaneous backups. You can use these backups to restore your database to a previous state with one-second granularity (restoration would only be necessary if there were no replicas in any of the other Availability Zones).
Amazon Aurora is designed for 99.99% availability. It will automatically recover from instance and storage failures. You can create up to 15 Amazon Aurora replicas to increase read throughput and for use as failover targets. The replicas share storage with the primary instance and as such provide lightweight, fine-grained replication that is almost synchronous (there’s a very modest lag, on the order of 10-20 milliseconds, due to page caching in the replicas).
Your existing MySQL applications will most likely work without changes. If you are using Amazon RDS for MySQL, you can migrate to Amazon Aurora with a couple of clicks. Aurora is feature-compatible with version 5.6 of MySQL.
Launching an Aurora Database Instance
Let’s step through the process of launching a Database Instance from the AWS Management Console (this is the primary launch tool during the Limited Preview; AWS Command Line Interface (CLI), AWS CloudFormation template, and API support are all in the works).
Instances of this type must be run from within a Amazon Virtual Private Cloud. I’ll start by choosing the Aurora engine:
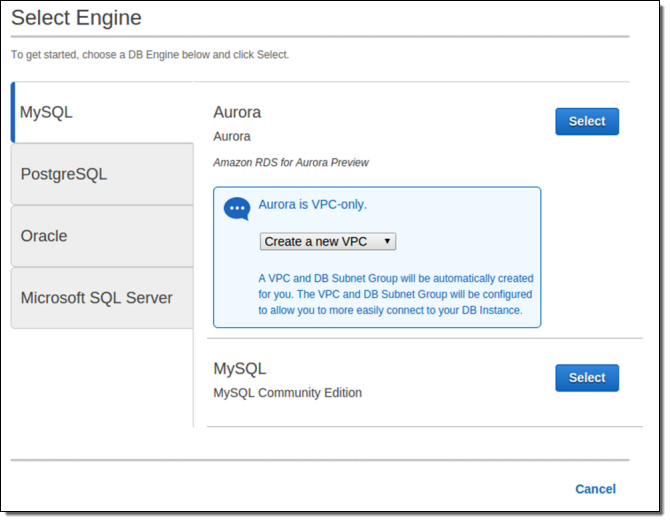
Then I choose a Database Instance type, name the database, and configure an account for the DBA:
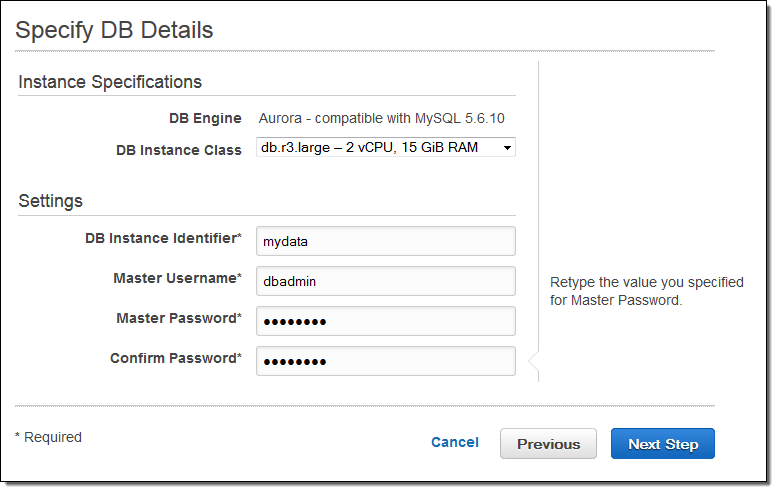
The final step is to set a few advanced details:
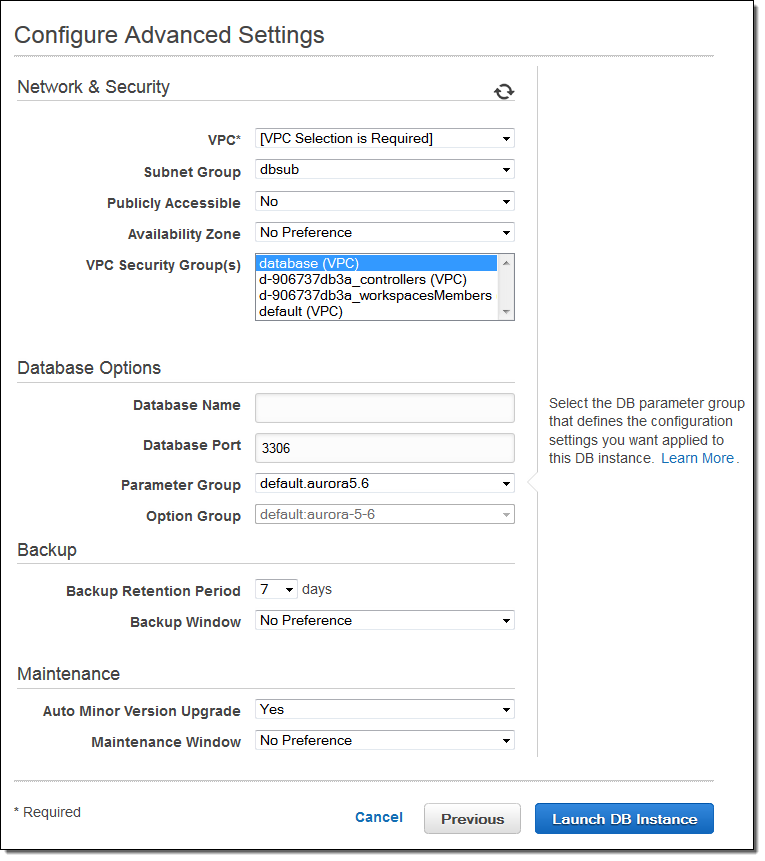
I don’t need to tell Amazon Aurora how much storage I need. Instead, the new storage engine will automatically and transparently allocate storage in 10 GB increments as I create and populate tables. The tables that I create in Amazon Aurora must use the InnoDB engine, and I will pay only for the storage that I actually use.
Once the instance is ready (generally less than 10 minutes) the endpoint is available in the console for use in my MySQL client code:
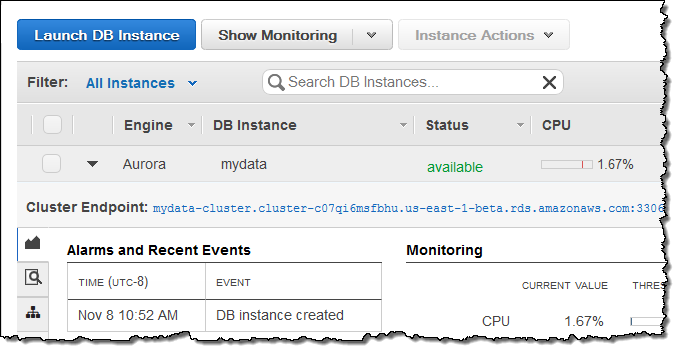
RDS Console Upgrades
The Console has been upgraded and now makes additional information about each of my instances available on a set of tabs (Alarms and Events, Configuration Details, and DB Cluster Details). Here’s the first one:
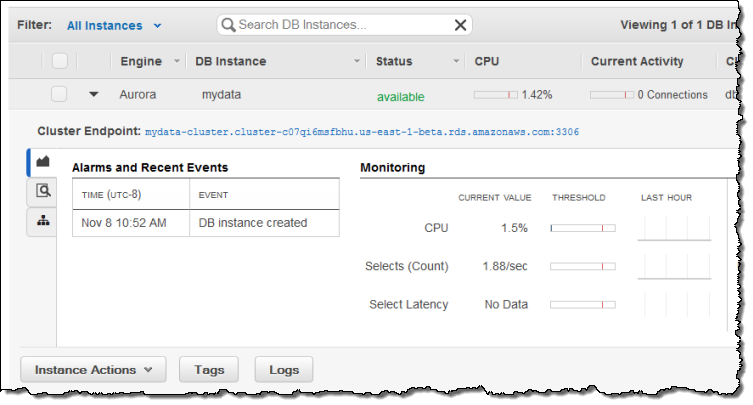
The Console also includes some additional monitoring options for my instances:
I can even expand the monitoring page to fill the screen (this is perfect for display on a big monitor in my operations room):
Pricing and Availability
Amazon Aurora was designed to provide you with a price to performance ratio that is more than 4 times better than previously available. When you migrate your existing RDS for MySQL database to RDS for Amazon Aurora you will likely find that you can achieve the same performance with a smaller database instance. Even better, with Amazon Aurora you pay only for the storage that you use.
We are launching Amazon Aurora in preview form in the US East (Northern Virginia) Region. If you are interested in joining the preview, simply click here and fill in the form.
— Jeff;
Amazon RDS for PostgreSQL Update – Read Replicas, 9.3.5 Support, Migration, Three New Extensions
My colleague Srikanth Deshpande of the Amazon Relational Database Service (RDS) team sent along a guest post in order to bring you up to date on the latest and greatest features added to Amazon RDS for PostgreSQL including Read Replications, data migration enhancements, and three new extensions.
— Jeff;
Read Replicas
Amazon RDS for PostgreSQL now supports Read Replicas, a popular RDS feature making it even easier for PostgreSQL customers to scale out databases to meet the needs of today’s read-heavy, high traffic web and mobile applications.
You can create multiple copies or replica of a given PostgreSQL database instance and scale your application by distributing read traffic across them. After you create a Read Replica, it is kept in sync using PostgreSQL’s asynchronous streaming replication. You can create or delete replicas in minutes using the point-and-click interface of the AWS Management Console, the AWS Command Line Interface (CLI), or the RDS APIs. Once you create a replica, it’s kept in sync with future updates using asynchronous PostgreSQL streaming replication (under certain conditions, Read Replicas can lag behind your write master). Amazon RDS gives you the ability to monitor replica lag so you can adjust your application as needed. Read Replicas can also be used with Multi-AZ, giving you the benefit of read scalability along with the durability and availability benefits of Multi-AZ deployments.
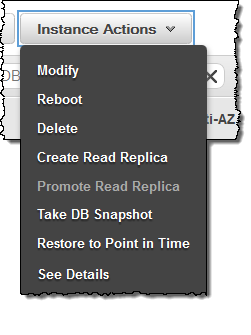
To create a Read Replica, select the write master in the Console and choose Create Read Replica from the Instance Actions menu:
Fill in the details and click on the Create Read Replica button:
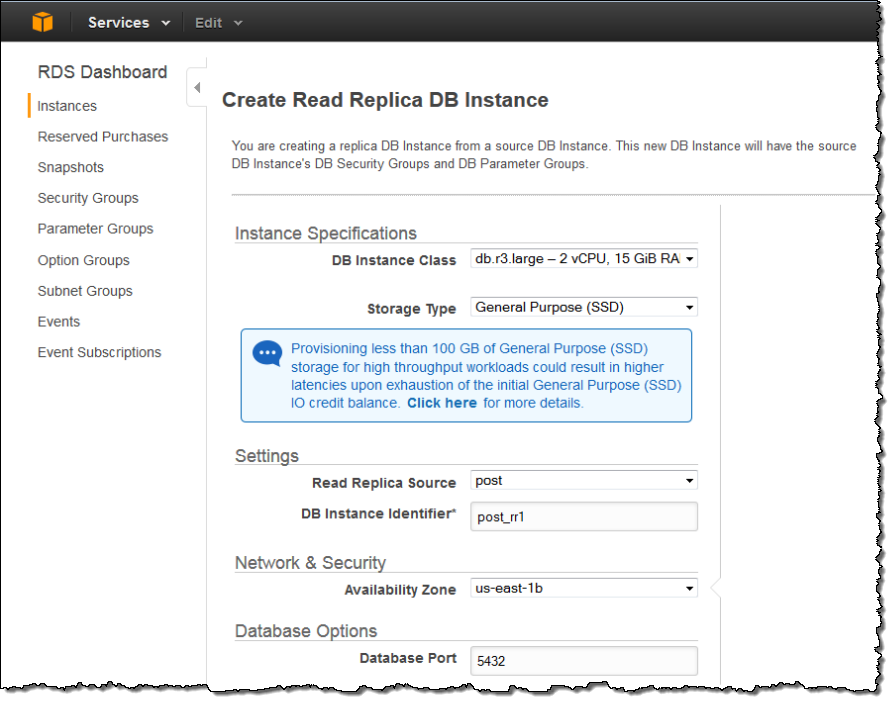
You’ll need to upgrade your existing instances to version 9.3.5 of PostgreSQL in order to take advantage of Read Replicas. Fortunately, you can upgrade within minutes using the AWS Management Console or the APIs and then start scaling out your read deployments. PostgreSQL 9.3.5 comes with PostGIS, which is now at version 2.1.3.
A Word From our Customers
I spoke to a couple of AWS customers in order to better understand how they are using Amazon RDS for PostgreSQL and to get a feel for how they will make use of Read Replicas.
Flipagram is a top 100 mobile app in the iOS Appstore and Google Play that helps users create and share video stories using their pictures. I spoke with Founder & CTO Brian Dilley; this is what he told me:
 We started our journey on RDS PostgreSQL and have grown to support a large user base on our app with a very small team by leveraging management capabilities, and compute, storage and I/O scalability of RDS PostgreSQL. We use Multi-AZ for high availability and love the ability to get HA for our production workloads using a check box on the management console. We run all of our production, integration and test/dev environments on RDS PostgreSQL. When we ranked as number one app in the Appstore in over 80 countries in December of 2013, RDS helped us scale our infrastructure to meet the huge spike in traffic with the push of a button. As we continue to grow, we look to forward to using Read Replicas to scale our read traffic while we focus on creating beautiful experiences for our users.
We started our journey on RDS PostgreSQL and have grown to support a large user base on our app with a very small team by leveraging management capabilities, and compute, storage and I/O scalability of RDS PostgreSQL. We use Multi-AZ for high availability and love the ability to get HA for our production workloads using a check box on the management console. We run all of our production, integration and test/dev environments on RDS PostgreSQL. When we ranked as number one app in the Appstore in over 80 countries in December of 2013, RDS helped us scale our infrastructure to meet the huge spike in traffic with the push of a button. As we continue to grow, we look to forward to using Read Replicas to scale our read traffic while we focus on creating beautiful experiences for our users.
E la Carte has been using Amazon RDS for PostgreSQL since it launched. Their guest-facing Presto tablets are designed for the coming era of Smart Dining. Bill Healey (CTO of E la Carte) told me:
 Before RDS Postgres, managing our own PostgreSQL instances required significant engineering resources whereas RDS makes it quick and easy to add replication and scale up both database size and IOPS. We’ve definitely been looking forward to the addition of read replicas for RDS Postgres. At E la Carte, we are very data-driven and are constantly analyzing data from both our production DB directly and our data warehouse aggregations. We’re looking forward to using RDS Read Replicas to drive our data warehouse ETL and our analytics tools resulting in increased performance and decreased load on our RDS production instances.
Before RDS Postgres, managing our own PostgreSQL instances required significant engineering resources whereas RDS makes it quick and easy to add replication and scale up both database size and IOPS. We’ve definitely been looking forward to the addition of read replicas for RDS Postgres. At E la Carte, we are very data-driven and are constantly analyzing data from both our production DB directly and our data warehouse aggregations. We’re looking forward to using RDS Read Replicas to drive our data warehouse ETL and our analytics tools resulting in increased performance and decreased load on our RDS production instances.
Trigger-Based Replication
RDS PostgreSQL now supports the session replication role. You can use this role in conjunction with open source, trigger-based tools such as Londiste and Bucardo to migrate existing data in to and out of RDS for PostgreSQL with minimal downtime.
Data Import (Londiste)
In order import data using Londiste, you would need to install it on the external PostgreSQL instance (not on RDS), set up RDS PostgreSQL instance as a replica, and enable replication. Londiste would initially do a dump and load of data into RDS PostgreSQL instance while the external instance is still taking write traffic. Over time, the RDS instance will catch up with the updates that are taking place on the external instance. Once the RDS instance is current, you can then point your applications to the RDS PostgreSQL instance, choosing the timing so as to minimize application downtime.
Data Export (Bucardo)
You can also use the session role to export data from an RDS for PostgreSQL instance to a remote target on-premises or on EC2. There are many ways to do this. For example, you can install Bucardo, an open source trigger-based lazy replication solution on the remote instance and set it up as a replication slave to the master RDS PostgreSQL instance. Bucardo replicates the data on the RDS instance to the remote instance as long as the remote instance is online. With lazy replication, when the remote instance goes offline and comes back online, Bucardo ensures that the remote instance will eventually catch up.
New Extensions
In addition to Read Replicas, support for version 9.3.5 of PostgreSQL, and trigger-based replication, we have also added support for three popular PostgreSQL extensions:
- pg_stat_statements – This extension provides lets you track execution statistics such as userid, exact query, and total time, for all SQL statements executed on the instance.
- postgres_fdw – This extension provides you with the ability to access and modify data stored in other PostgreSQL servers as if they are tables within the RDS PostgreSQL instance.
- PL/V8 – This is a PostgreSQL procedural language extension powered by the V8 JavaScript Engine. With this extension, you can write JavaScript functions that can be called from SQL.
You will need to create new instances or upgrade your existing instances to version 9.3.5 using the AWS Management Console or APIs in order to take advantage of these extensions.
The Amazon RDS for PostgreSQL page contains all of the technical and pricing information you’ll need to have in order to get started.
— Srikanth Deshpande, Senior Product Manager, Amazon RDS
Fast, Easy, Free Data Sync from RDS MySQL to Amazon Redshift
As you know, I’m a big fan of Amazon RDS. I love the fact that it allows you focus on your applications and not on keeping your database up and running. I’m also excited by the disruptive price, performance, and ease of use of Amazon Redshift, our petabyte-scale, fully managed data warehouse service that lets you get started for $0.25 per hour and costs less than $1,000 per TB per year. Many customers agree, as you can see from recent posts by Pinterest, Monetate, and Upworthy.
Many AWS customers want to get their operational and transactional data from RDS into Redshift in order to run analytics. Until recently, it’s been a somewhat complicated process. A few week ago, the RDS team simplified the process by enabling row-based binary logging, which in turn has allowed our AWS Partner Network (APN) partners to build products that continuously replicate data from RDS MySQL to Redshift.
Two APN data integration partners, FlyData and Attunity, currently leverage row-based binary logging to continuously replicate data from RDS MySQL to Redshift. Both offer free trials of their software in conjunction with Redshift’s two month free trial. After a few simple configuration steps, these products will automatically copy schemas and data from RDS MySQL to Redshift and keep them in sync. This will allow you to run high performance reports and analytics on up-to-date data in Redshift without having to design a complex data loading process or put unnecessary load on your RDS database instances.
If you’re using RDS MySQL 5.6, you can replicate directly from your database instance by enabling row-based logging, as shown below. If you’re using RDS MySQL 5.5, you’ll need to set up a MySQL 5.6 read replica and configure the replication tools to use the replica to sync your data to Redshift. To learn more about these two solutions, see FlyData’s Free Trial Guide for RDS MySQL to Redshift as well as Attunity’s Free Trial and the RDS MySQL to Redshift Guide. Attunity’s trial is available through the AWS Marketplace, where you can find and immediately start using software with Redshift with just a few clicks.
Informatica and SnapLogic also enable data integration between RDS and Redshift, using a SQL-based mechanism that queries your database to identify data to transfer to your Amazon Redshift clusters. Informatica is offering a 60-day free trial and SnapLogic has a 30 day free trial.
All four data integration solutions discussed above can be used with all RDS database engines (MySQL, SQL Server, PostgreSQL, and Oracle). You can also use AWS Data Pipeline (which added some recent Redshift enhancements), to move data between your RDS database instances and Redshift clusters. If you have analytics workloads, now is a great time to take advantage of these tools and begin continuously loading and analyzing data in Redshift.
Enabling Amazon RDS MySQL 5.6 Row Based Logging
Here’s how you enable row based logging for MySQL 5.6:
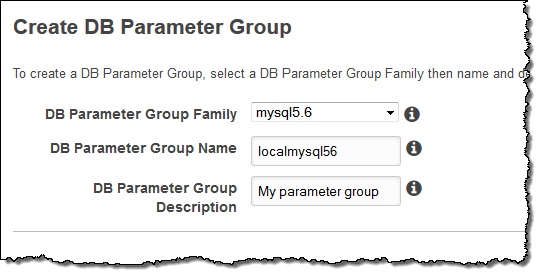
- Go to the Amazon RDS Console and click Parameter Groups in the left pane:
- Click on the Create DB Parameter Group button and create a new parameter group in the mysql5.6 family:
- Once in the detail view, click the Edit Parameters button. Then set the
binlog_formatparameter toROW: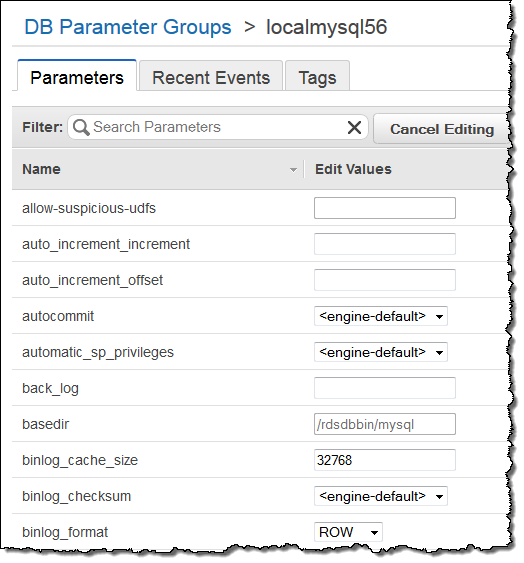
For more details please see Working with MySQL Database Log Files.
Free Trials for Continuous RDS to Redshift Replication from APN Partners
FlyData has published a step by step guide and a video demo in order to show you how to continuously and automatically sync your RDS MySQL 5.6 data to Redshift and you can get started for free for 30 days. You will need to create a new parameter group with binlog_format set to ROW and binlog_checksum set to NONE, and adjust a few other parameters as described in the guide above.
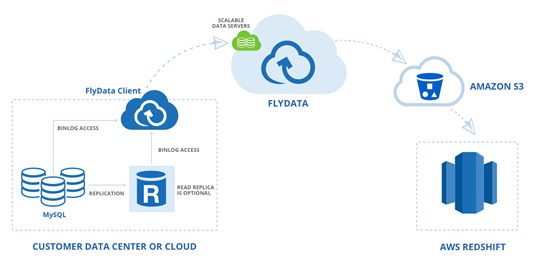
AWS customers are already using FlyData for continuous replication to Redshift from RDS. For example, rideshare startup Sidecar seamlessly syncs tens of millions of records per day to Redshift from two RDS instances in order to analyze how customers utilize Sidecar’s custom ride services. According to Sidecar, their analytics run 3x faster and the near-real-time access to data helps them to provide a great experience for riders and drivers. Here’s the data flow when using FlyData:
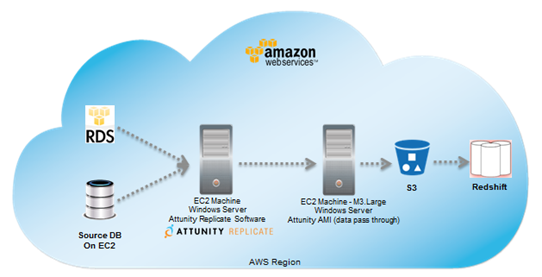
Attunity CloudBeam has published a configuration guide that describes how you can enable continuous, incremental change data capture from RDS MySQL 5.6 to Redshift (you can get started for free for 5 days directly from the AWS Marketplace. You will need to create a new parameter group with binlog_format set to ROW and binlog_checksum set to NONE.
For additional information on configuring Attunity for use with Redshift please see this quick start guide.
Redshift Free Trial
If you are new to Amazon Redshift, youre eligible for a free trial and can get 750 free hours for each of two months to try a dw2.large node (16 GB of RAM, 2 virtual cores, and 160 GB of compressed SSD storage). This gives you enough hours to continuously run a single node for two months. You can also build clusters with multiple dw2.large nodes to test larger data sets; this will consume your free hours more quickly. Each month’s 750 free hours are shared across all running dw2.large nodes in all regions.
To start using Redshift for free, simply go to the Redshift Console, launch a cluster, and select dw2.large for the Node Type:
Big Data Webinar
If you want to learn more, do not miss the AWS Big Data Webinar showcasing how startup Couchsurfing used Attunitys continuous CDC to reduce their ETL process from 3 months to 3 hours and cut costs by nearly $40K.
— Jeff;
New, Cost-Effective Memory-Optimized DB Instances for Amazon RDS
The Amazon Relational Database Service (RDS) takes care of just about all of the heavy lifting once associated with setting up, running, and scaling a MySQL, Oracle Database, SQL Server, or PostgreSQL database. You can focus on your application while RDS handles database upgrades, fault tolerance, and many other issues that once required a system administrator or DBA.
You can now take advantage of the R3 instance type with Amazon RDS. R3 instances are optimized for memory-intensive applications, have the lowest cost per GiB of RAM among Amazon RDS instance types, and are recommended for high performance database workloads. These new instances feature the latest Intel Xeon Ivy Bridge processors and deliver higher sustained memory bandwidth with lower network latency and jitter at prices up to 28% lower than comparable M2 DB Instances.
Better, Stronger, Faster
The R3 instances support enhanced networking and higher sustained memory bandwidth for higher performance. You can use them to support the demanding database workloads often found in gaming, enterprise, social media, web, and mobile applications. You can also consolidate databases that are currently spread across several smaller M2 instances to a smaller number of high-capacity db.r3.8xlarge instances.
The larger instances (db.r3.xlarge, db.r3.2xlarge, db.r3.4xlarge, and db.r3.8xlarge are optimized for Provisioned IOPS storage. For a workload comprised of 50% reads and 50% writes, you can realize up to 20,000 IOPS for MySQL and 25,000 IOPS for PostgreSQL when running on a db.r3.8xlarge instance.
R3 Details
You can currently launch DB instances that run version 5.6 of MySQL, PostgreSQL, or SQL Server. Support for versions 5.1 and 5.5 of MySQL in the works, as is support for Oracle Database.
Pricing for R3 database instances start at $0.089/hour (effective price) for 3 year Heavy Utilization Reserved Instances and $0.240/hour for On-Demand usage in the US West (Oregon) Region for MySQL. For more information on pricing, check out the RDS Pricing page.
These new instances are currently available in the US East (Northern Virginia), US West (Oregon), US West (Northern California), EU (Ireland), Asia Pacific (Tokyo), Asia Pacific (Sydney),and Asia Pacific (Singapore) Regions. We expect to make them available in the GovCloud (US), China (Beijing), and South America (São Paulo) Regions in the near future.
— Jeff;
Amazon RDS for SQL Server With Multi-AZ
The Amazon Relational Database Service (RDS) simplifies the process of setting up, running, and scaling your MySQL, Oracle, PostgreSQL, or Microsoft SQL Server database so that you can focus on your application instead of on complex and time-consuming database administration chores.
Many AWS customers are using RDS in demanding production environments and take advantage of powerful features like automated snapshot backups (no more tapes and easy point-in-time restores), Provisioned IOPS for fast and consistent I/O performance, easy database upgrades, and the ability to scale processing and storage by simply modifying the appropriate settings. Customers who make use of Amazon RDS for MySQL, Amazon RDS for Oracle Database, and Amazon RDS for PostgresQL can also enhance availability and data durability by creating a Multi-AZ (Availability Zone) deployment. When activated, this RDS feature creates primary and secondary database hosts, arranges for synchronous data replication from primary to secondary, and monitors both hosts to ensure that they remain healthy. In the event of a failure, RDS will promote the secondary to primary, create a new secondary, and re-establish replication, all with complete transparency and no user or application involvement.
Multi-AZ for SQL Server
Today we are bringing the benefits of Multi-AZ operation to Amazon RDS for SQL Server. This new release takes advantage of SQL Server Mirroring technology and makes all of the benefits listed above available to SQL Server users.
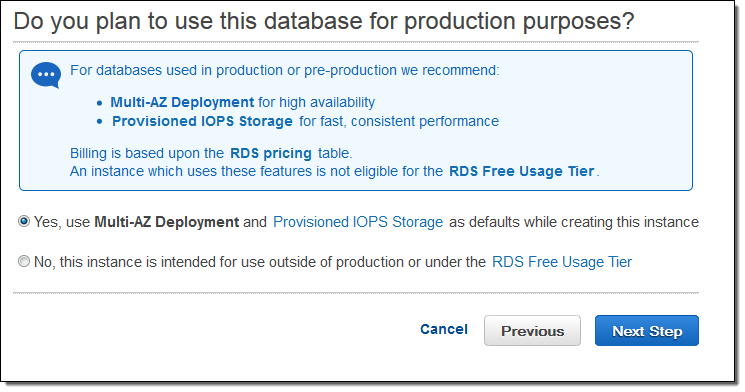
Setting up traditional SQL Server Mirroring requires hundreds of manual steps at the database and operating system level. With RDS, you can launch a fully managed, highly available instance of SQL Server with a few clicks in the AWS Management Console. If you choose the Standard or Enterprise edition of SQL Server 2008R2 or 2012, the console will ask you if the instance is for production use. In other words, it wants to know if you need a Multi-AZ deployment and Provisioned IOPS:
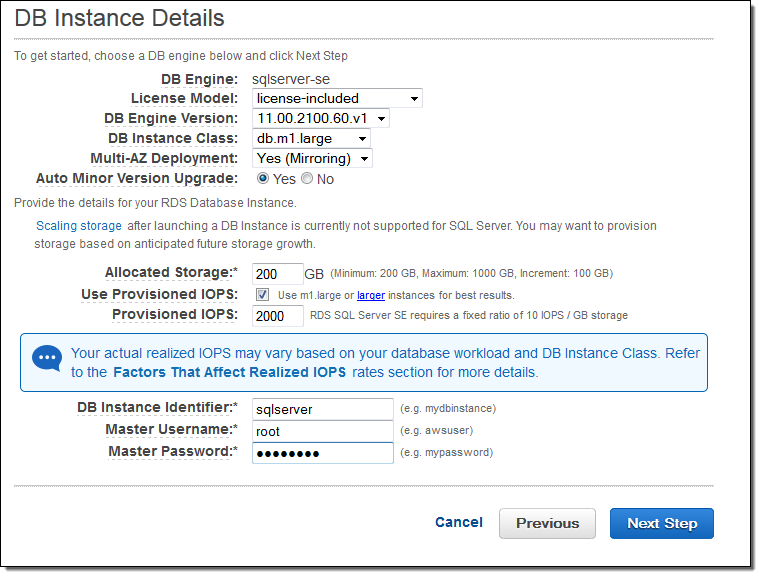
As is always the case with RDS, you have complete control of the engine version, storage allocation, and Provisioned IOPS. You can also set the database identifier, master user name, and password:
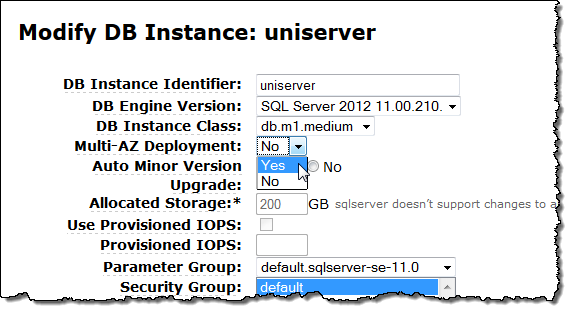
If you have an existing RDS for SQL Server instance, you can easily Modify it to add mirroring:
The Details
With the basics out of the way, let’s spend a few minutes on the details.
This new feature is available in the US East (Northern Virginia), West (Oregon), and EU (Ireland) Regions. We plan to support other AWS Regions in the future. The Multi-AZ feature always operates within a single Region. You can copy RDS Snapshots to another Region for cross-region backup if you’d like.
The entire SQL Server instance will fail over as an atomic unit to the standby host. You can test your application’s resiliency in the face of failover by triggering one manually:
You can create a DB Event Subscription if you would like to be notified by email or SMS when a failover occurs:
You can also view the DB Events for the instance to learn of failover events.
Users and logins are replicated from the active host to the standby host. At this time, the replication does not include other items stored in the msdb database such as user-defined roles or linked server objects.
Video and Webinar
To help you to get started with Amazon RDS for SQL Server with Multi-AZ, we have put together a short demonstration video:
We will also be running an Amazon RDS Webinar on Thursday, June 5th at 12:00 PM PDT. Intended for Database Administrators, Software Developers, Solutions Architects, and Technical Decision Makers, the webinar will provide you with an overview of Amazon RDS for SQL Server and it will help you to understand the architecture of an RDS SQL Server deployment that is spread across Availability Zones. You will see a demonstration of how to set up a highly available SQL Server deployment using Amazon RDS, and a demonstration of automatic failover from a primary to a standby. The webinar is free, but space is limited and preregistration is always a good idea.
Time to Start
This new feature is available now and you can start using it today!
— Jeff;
MySQL 5.5 to MySQL 5.6 Upgrade Support for Amazon RDS
The Amazon Relational Database Service (RDS) takes care of almost all of the day to day grunt work that would otherwise consume a lot of system administrator and DBA time. You don’t have to worry about hardware provisioning, operating system or database installation or patching, backups, monitoring, or failover. Instead, you can invest in your application and in your data.
Multiple Engine Versions
RDS supports multiple versions of the MySQL, Oracle, SQL Server, and PostgreSQL database engines. Here is the current set of supported MySQL versions:

You can simply select the desired version and create an RDS DB Instance in a minutes.
Upgrade Support
Today we are enhancing Amazon RDS with the ability to upgrade your MySQL DB Instances from version 5.5 to the latest release in the 5.6 series that’s available on RDS.
To upgrade your existing instances, create a new Read Replica, upgrade it to MySQL 5.6, and once it has caught up to your existing master, promote it to be the new master. You can initiate and monitor each of these steps from the AWS Management Console. Refer to the Upgrading from MySQL 5.5 to MySQL 5.6 section of the Amazon RDS User Guide to learn more.
For MySQL 5.5 instances that you create after today’s release, simply select the Modify option corresponding to the DB Instance to upgrade it to the latest version of MySQL 5.6. If you are using RDS Read Replicas, upgrade them before you upgrade the master.
Version 5.6 MySQL offers a number of important new features and performance benefits including crash safe slaves (Read Replicas), an improved query optimizer, improved partitioning and replication, NoSQL-style memcached APIs, and better monitoring.
The InnoDB storage engine now supports binary log access and online schema changes, allowing ALTER TABLE operations to proceed in parallel with other operations on a table. The engine now does a better job of reporting optimizer statistics, with the goal of improving and stabilizing query performance. An enhanced locking mechanism reduces system contention, and multi-threaded purging increases the efficiency of purge operations that span more than one table.
Planning for Upgrades
Regardless of the upgrade method that is applicable to your RDS DB Instances, you need to make sure that your application is compatible with version 5.6 of MySQL. Read the documentation on Upgrading an Instance to learn more about this.
— Jeff;
Use Oracle GoldenGate with Amazon RDS for Oracle Database
Many organizations face the need to move transactional data from one location to another location. As organizations continue to make
the cloud a central part of their overall IT architecture, this need seems to grow in tandem with the size, scope, and complexity of the organization. The application use cases range from migrating data from a master transactional database to a readable secondary database, or moving applications from on-premises to the cloud, or having a redundant copy in another data center location. Transactions that are generated and stored within a database run by one application may need to be copied over so that it can be processed, analyzed, and aggregated in a central location.
In many cases, one part of the organization has moved to a cloud-based data storage model that’s powered by the Amazon Relational Database Service (RDS). With support for the four most popular relational databases (Oracle, MySQL, SQL Server, and PostgreSQL), RDS has been adopted by organizations of all shapes and sizes. Users of Amazon RDS love the fact that it takes care of many important yet tedious deployment, maintenance, and backup tasks that are traditionally part and parcel of an on-premises database.
Oracle GoldenGate
Today we are giving RDS Oracle customers the ability to use Oracle GoldenGate with Amazon RDS. Your RDS Oracle Database Instances can be used as the source or the target of GoldenGate-powered replication operations.
Oracle GoldenGate can collect, replicate, and manage transactional data between a pair of Oracle databases. These databases can be hosted on-premises or in the AWS cloud. If both databases are in the AWS cloud, they can be in the same Region or in different Regions. The cloud-based databases can be RDS DB Instances or Amazon EC2 Instances that are running a supported version of Oracle Database. In other words, you have a lot of flexibility! Here are four example scenarios:
- On-premises database to RDS DB Instance.
- RDS DB Instance to RDS DB Instance.
- EC2-hosted database to RDS DB Instance.
- Cross-region replication from one RDS DB Instance to another RDS DB Instance.

You can also use GoldenGate for Amazon RDS to upgrade to a new major version of Oracle.
Getting Started
As you can see from the scenarios listed above, you will need to run the GoldenGate Hub on an EC2 Instance. This instance must have sufficient processing power, storage, and RAM to handle the anticipated transaction volume. Supplemental logging must be enabled for the source database and it must retain archived redo logs. The source and target database need user accounts for the GoldenGate user, along with a very specific set of privileges.
After everything has been configured, you will use the Extract and Replicat utilities provided by Oracle GoldenGate.
The Amazon RDS User Guide contains the information that you will need to have in order to install and configure the hub and to run the utilities.
— Jeff;