AWS News Blog
Lambda@Edge – Intelligent Processing of HTTP Requests at the Edge

|
Late last year I announced a preview of Lambda@Edge and talked about how you could use it to intelligently process HTTP requests at locations that are close (latency-wise) to your customers. Developers who applied and gained access to the preview have been making good use of it, and have provided us with plenty of very helpful feedback. During the preview we added the ability to generate HTTP responses and support for CloudWatch Logs, and also updated our roadmap based on the feedback.
Now Generally Available
Today I am happy to announce that Lambda@Edge is now generally available! You can use it to:
- Inspect cookies and rewrite URLs to perform A/B testing.
- Send specific objects to your users based on the User-Agent header.
- Implement access control by looking for specific headers before passing requests to the origin.
- Add, drop, or modify headers to direct users to different cached objects.
- Generate new HTTP responses.
- Cleanly support legacy URLs.
- Modify or condense headers or URLs to improve cache utilization.
- Make HTTP requests to other Internet resources and use the results to customize responses.
Lambda@Edge allows you to create web-based user experiences that are rich and personal. As is rapidly becoming the norm in today’s world, you don’t need to provision or manage any servers. You simply upload your code (Lambda functions written in Node.js) and pick one of the CloudFront behaviors that you have created for the distribution, along with the desired CloudFront event:
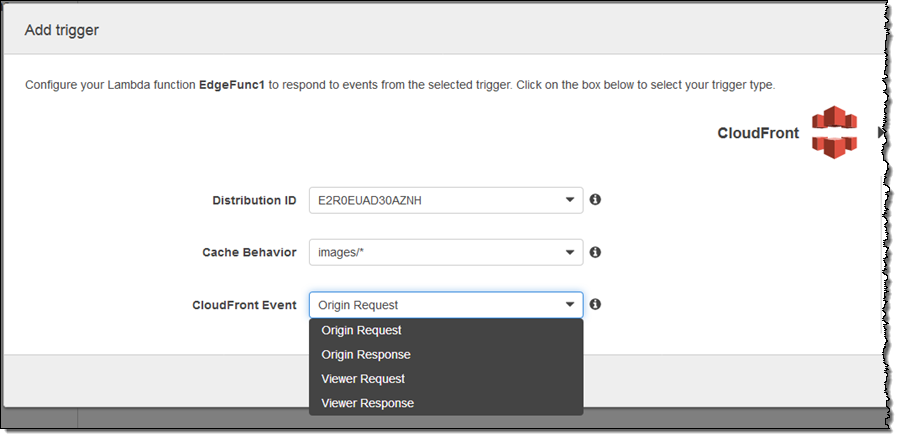
In this case, my function (the imaginatively named EdgeFunc1) would run in response to origin requests for image/* within the indicated distribution. As you can see, you can run code in response to four different CloudFront events:
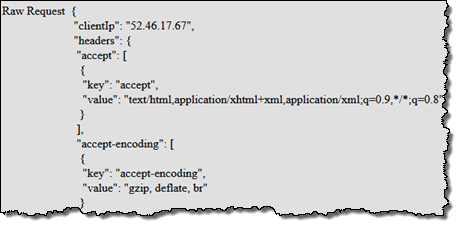 Viewer Request – This event is triggered when an event arrives from a viewer (an HTTP client, generally a web browser or a mobile app), and has access to the incoming HTTP request. As you know, each CloudFront edge location maintains a large cache of objects so that it can efficiently respond to repeated requests. This particular event is triggered regardless of whether the requested object is already cached.
Viewer Request – This event is triggered when an event arrives from a viewer (an HTTP client, generally a web browser or a mobile app), and has access to the incoming HTTP request. As you know, each CloudFront edge location maintains a large cache of objects so that it can efficiently respond to repeated requests. This particular event is triggered regardless of whether the requested object is already cached.
Origin Request – This event is triggered when the edge location is about to make a request back to the origin, due to the fact that the requested object is not cached at the edge location. It has access to the request that will be made to the origin (often an S3 bucket or code running on an EC2 instance).
Origin Response – This event is triggered after the origin returns a response to a request. It has access to the response from the origin.
Viewer Response – This is event is triggered before the edge location returns a response to the viewer. It has access to the response.
Functions are globally replicated and requests are automatically routed to the optimal location for execution. You can write your code once and with no overt action on your part, have it be available at low latency to users all over the world.
Your code has full access to requests and responses, including headers, cookies, the HTTP method (GET, HEAD, and so forth), and the URI. Subject to a few restrictions, it can modify existing headers and insert new ones.
Lambda@Edge in Action
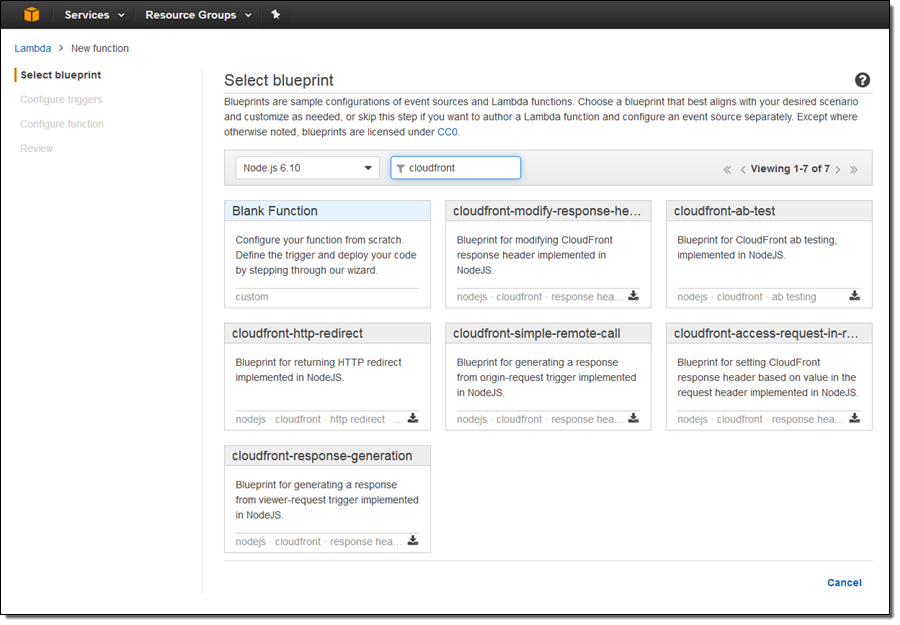
Let’s create a simple function that runs in response to the Viewer Request event. I open up the Lambda Console and create a new function. I choose the Node.js 6.10 runtime and search for cloudfront blueprints:
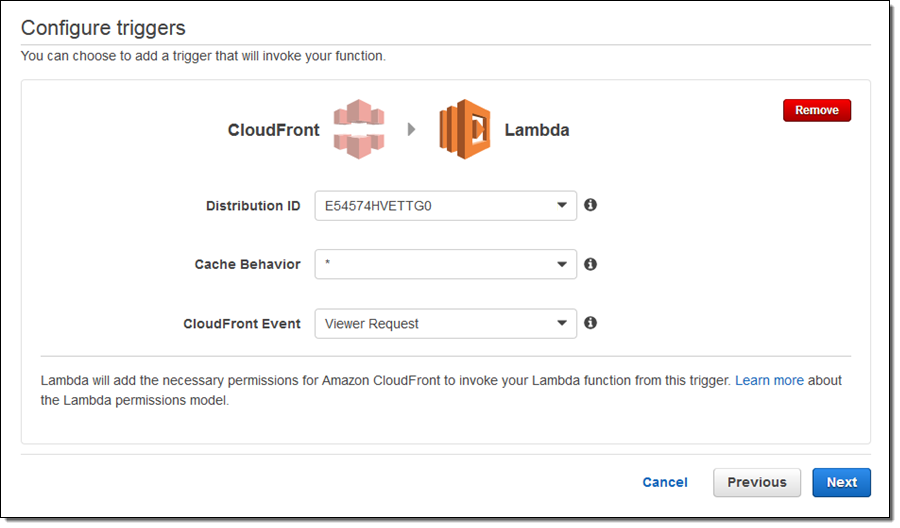
I choose cloudfront-response-generation and configure a trigger to invoke the function:
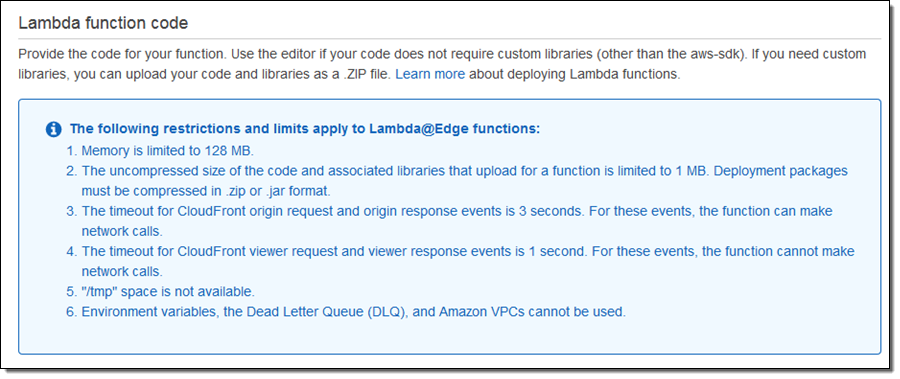
The Lambda Console provides me with some information about the operating environment for my function:
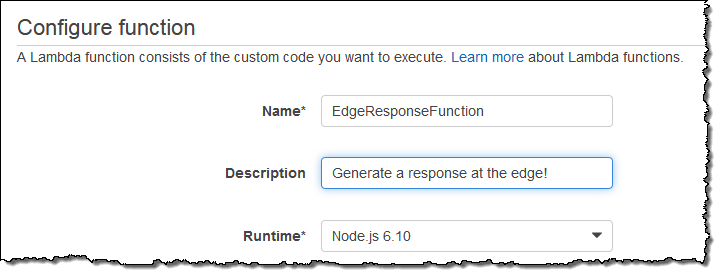
I enter a name and a description for my function, as usual:
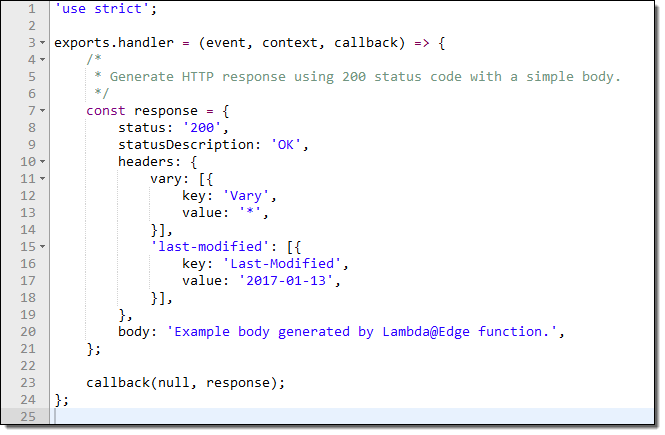
The blueprint includes a fully operational function. It generates a “200” HTTP response and a very simple body:
I used this as the starting point for my own code, which pulls some interesting values from the request and displays them in a table:
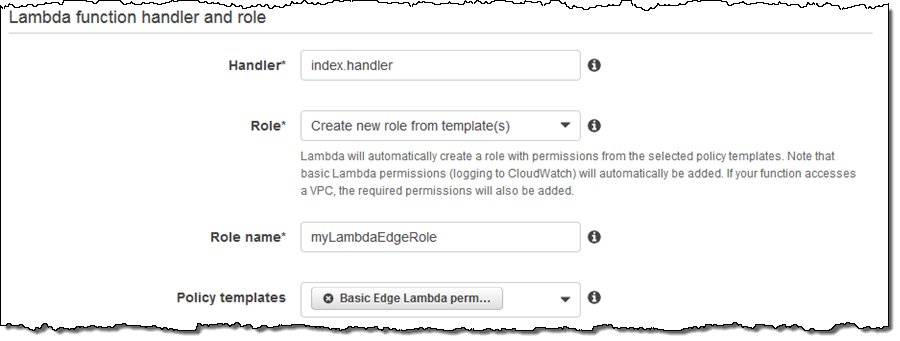
I configure my handler, and request the creation of a new IAM Role with Basic Edge Lambda permissions:
On the next page I confirm my settings (as I would do for a regular Lambda function), and click on Create function:
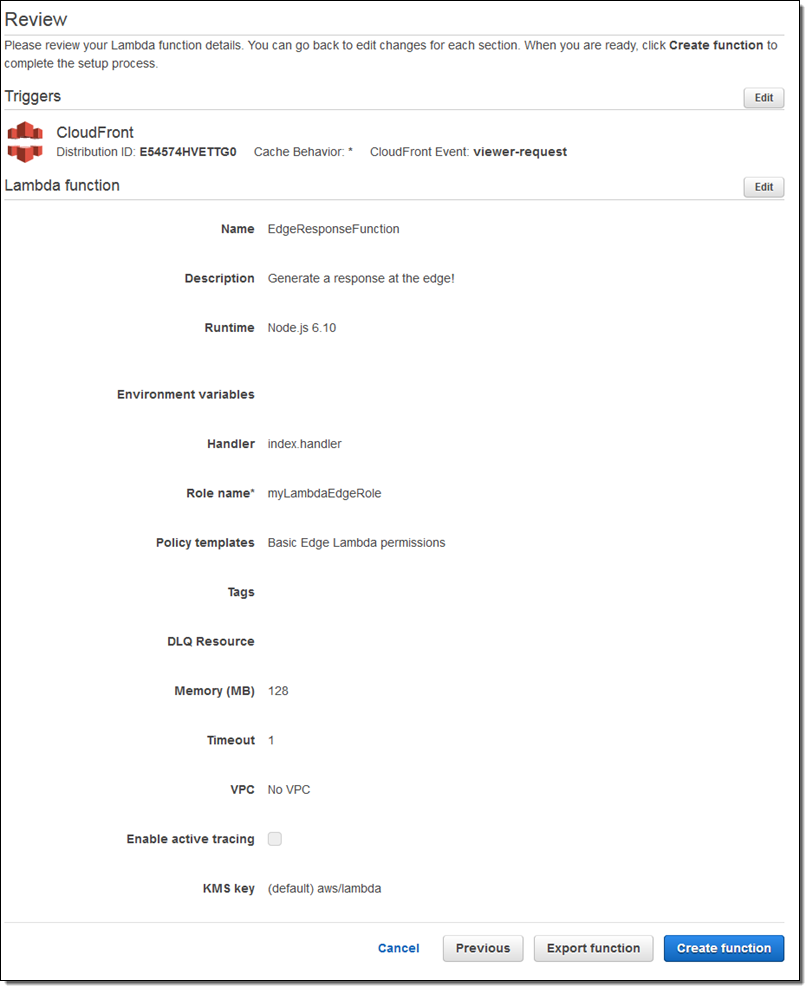
This creates the function, attaches the trigger to the distribution, and also initiates global replication of the function. The status of my distribution changes to In Progress for the duration of the replication (typically 5 to 8 minutes):
The status changes back to Deployed as soon as the replication completes:
Then I access the root of my distribution (https://dogy9dy9kvj6w.cloudfront.net/), the function runs, and this is what I see:
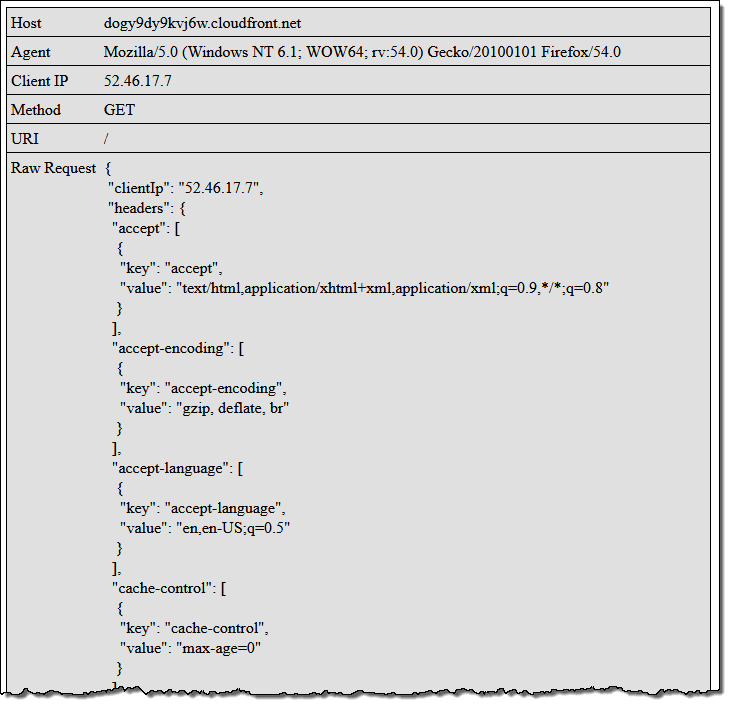 Feel free to click on the image (it is linked to the root of my distribution) to run my code!
Feel free to click on the image (it is linked to the root of my distribution) to run my code!
As usual, this is a very simple example and I am sure that you can do a lot better. Here are a few ideas to get you started:
Site Management – You can take an entire dynamic website offline and replace critical pages with Lambda@Edge functions for maintenance or during a disaster recovery operation.
High Volume Content – You can create scoreboards, weather reports, or public safety pages and make them available at the edge, both quickly and cost-effectively.
Create something cool and share it in the comments or in a blog post, and I’ll take a look.
Things to Know
Here are a couple of things to keep in mind as you start to think about how to put Lambda@Edge to use in your application:
Timeouts – Functions that handle Origin Request and Origin Response events must complete within 3 seconds. Functions that handle Viewer Request and Viewer Response events must complete within 1 second.
Versioning – After you update your code in the Lambda Console, you must publish a new version and set up a fresh set of triggers for it, and then wait for the replication to complete. You must always refer to your code using a version number; $LATEST and aliases do not apply.
Headers – As you can see from my code, the HTTP request headers are accessible as an array. The headers fall in to four categories:
- Accessible – Can be read, written, deleted, or modified.
- Restricted – Must be passed on to the origin.
- Read-only – Can be read, but not modified in any way.
- Blacklisted – Not seen by code, and cannot be added.
Runtime Environment – The runtime environment provides each function with 128 MB of memory, but no builtin libraries or access to /tmp.
Web Service Access – Functions that handle Origin Request and Origin Response events must complete within 3 seconds can access the AWS APIs and fetch content via HTTP. These requests are always made synchronously with request to the original request or response.
Function Replication – As I mentioned earlier, your functions will be globally replicated. The replicas are visible in the “other” regions from the Lambda Console:
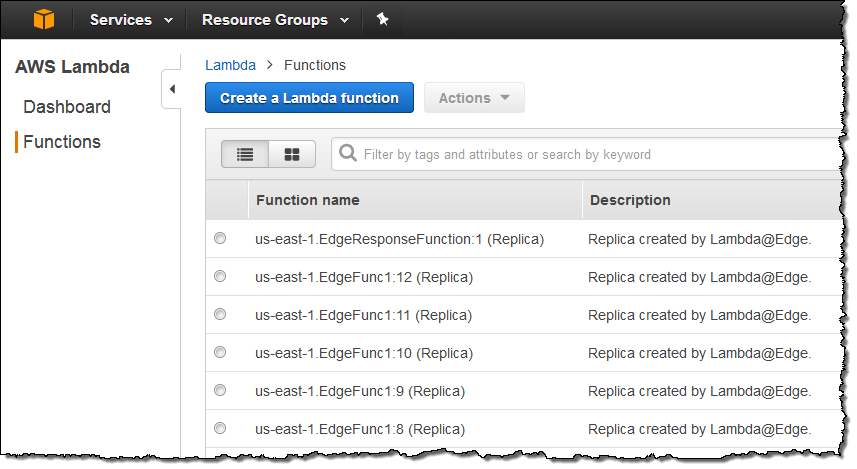
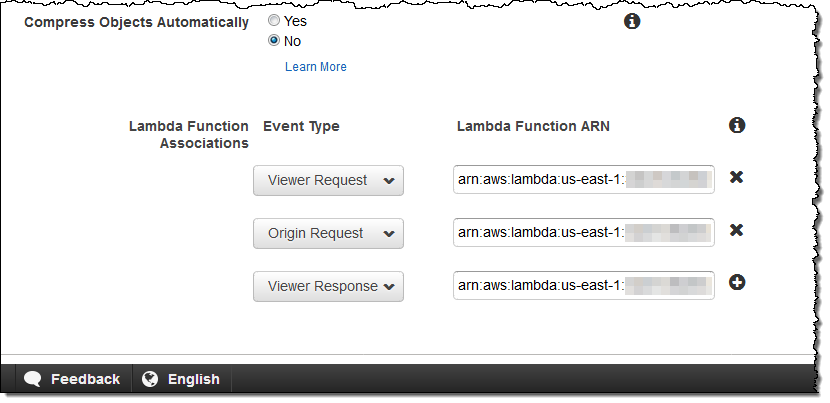
CloudFront – Everything that you already know about CloudFront and CloudFront behaviors is relevant to Lambda@Edge. You can use multiple behaviors (each with up to four Lambda@Edge functions) from each behavior, customize header & cookie forwarding, and so forth. You can also make the association between events and functions (via ARNs that include function versions) while you are editing a behavior:
Available Now
Lambda@Edge is available now and you can start using it today. Pricing is based on the number of times that your functions are invoked and the amount of time that they run (see the Lambda@Edge Pricing page for more info).
— Jeff;
Modified 2/2/2021 – In an effort to ensure a great experience, expired links in this post have been updated or removed from the original post.