AWS Big Data Blog
A serverless operational data lake for retail with AWS Glue, Amazon Kinesis Data Streams, Amazon DynamoDB, and Amazon QuickSight
Do you want to reduce stockouts at stores? Do you want to improve order delivery timelines? Do you want to provide your customers with accurate product availability, down to the millisecond? A retail operational data lake can help you transform the customer experience by providing deeper insights into a variety of operational aspects of your supply chain.
In this post, we demonstrate how to create a serverless operational data lake using AWS services, including AWS Glue, Amazon Kinesis Data Streams, Amazon DynamoDB, Amazon Athena, and Amazon QuickSight.
Retail operations is a critical functional area that gives retailers a competitive edge. An efficient retail operation can optimize the supply chain for a better customer experience and cost reduction. An optimized retail operation can reduce frequent stockouts and delayed shipments, and provide accurate inventory and order details. Today, a retailer’s channels aren’t just store and web—they include mobile apps, chatbots, connected devices, and social media channels. The data is both structured and unstructured. This coupled with multiple fulfillment options like buy online and pick up at store, ship from store, or ship from distribution centers, which increases the complexity of retail operations.
Most retailers use a centralized order management system (OMS) for managing orders, inventory, shipments, payments, and other operational aspects. These legacy OMSs are unable to scale in response to the rapid changes in retail business models. The enterprise applications that are key for efficient and smooth retail operations rely on a central OMS. Applications for ecommerce, warehouse management, call centers, and mobile all require an OMS to get order status, inventory positions of different items, shipment status, and more. Another challenge with legacy OMSs is they’re not designed to handle unstructured data like weather data and IoT data that could impact inventory and order fulfillment. A legacy OMS that can’t scale prohibits you from implementing new business models that could transform your customer experience.
A data lake is a centralized repository that allows you to store all your structured and unstructured data at any scale. An operational data lake addresses this challenge by providing easy access to structured and unstructured operational data in real time from various enterprise systems. You can store your data as is, without having to first structure the data, and run different types of analytics—from dashboards and visualizations to big data processing, real-time analytics, and machine learning (ML)—to guide better decisions. This can ease the burden on OMSs that can instead focus on order orchestration and management.
Solution overview
In this post, we create an end-to-end pipeline to ingest, store, process, analyze, and visualize operational data like orders, inventory, and shipment updates. We use the following AWS services as key components:
- Kinesis Data Streams to ingest all operational data in real time from various systems
- DynamoDB, Amazon Aurora, and Amazon Simple Storage Service (Amazon S3) to store the data
- AWS Glue DataBrew to clean and transform the data
- AWS Glue crawlers to catalog the data
- Athena to query the processed data
- A QuickSight dashboard that provides insights into various operational metrics
The following diagram illustrates the solution architecture.

The data pipeline consists of stages to ingest, store, process, analyze, and finally visualize the data, which we discuss in more detail in the following sections.
Data ingestion
Orders and inventory data is ingested in real time from multiple sources like web applications, mobile apps, and connected devices into Kinesis Data Streams. Kinesis Data Streams is a massively scalable and durable real-time data streaming service. Kinesis Data Streams can continuously capture gigabytes of data per second from hundreds of thousands of sources, such as web applications, database events, inventory transactions, and payment transactions. Frontend systems like ecommerce applications and mobile apps ingest the order data as soon as items are added to a cart or an order is created. The OMS ingests orders when the order status changes. OMSs, stores, and third-party suppliers ingest inventory updates into the data stream.
To simulate orders, an AWS Lambda function is triggered by a scheduled Amazon CloudWatch event every minute to ingest orders to a data stream. This function simulates the typical order management system lifecycle (order created, scheduled, released, shipped, and delivered). Similarly, a second Lambda function is triggered by a CloudWatch event to generate inventory updates. This function simulates different inventory updates such as purchase orders created from systems like the OMS or third-party suppliers. In a production environment, this data would come from frontend applications and a centralized order management system.
Data storage
There are two types of data: hot and cold data. Hot data is consumed by frontend applications like web applications, mobile apps, and connected devices. The following are some example use cases for hot data:
- When a customer is browsing products, the real-time availability of the item must be displayed
- Customers interacting with Alexa to know the status of the order
- A call center agent interacting with a customer needs to know the status of the customer order or its shipment details
The systems, APIs, and devices that consume this data need the data within seconds or milliseconds of the transactions.
Cold data is used for long-term analytics like orders over a period of time, orders by channel, top 10 items by number of orders, or planned vs. available inventory by item, warehouse, or store.
For this solution, we store orders hot data in DynamoDB. DynamoDB is a fully managed NoSQL database that delivers single-digit millisecond performance at any scale. A Lambda function processes records in the Kinesis data stream and stores it in a DynamoDB table.
Inventory hot data is stored in an Amazon Aurora MySQL-Compatible Edition database. Inventory is transactional data that requires high consistency so that customers aren’t over-promised or under-promised when they place orders. Aurora MySQL is fully managed database that is up to five times faster than standard MySQL databases and three times faster than standard PostgreSQL databases. It provides the security, availability, and reliability of commercial databases at a tenth of the cost.
Amazon S3 is object storage built to store and retrieve any amount of data from anywhere. It’s a simple storage service that offers industry-leading durability, availability, performance, security, and virtually unlimited scalability at very low cost. Order and inventory cold data is stored in Amazon S3.
Amazon Kinesis Data Firehose reads the data from the Kinesis data stream and stores it in Amazon S3. Kinesis Data Firehose is the easiest way to load streaming data into data stores and analytics tools. It can capture, transform, and load streaming data into Amazon S3, Amazon Redshift, Amazon OpenSearch Service, and Splunk, enabling near-real-time analytics.
Data processing
The data processing stage involves cleaning, preparing, and transforming the data to help downstream analytics applications easily query the data. Each frontend system might have a different data format. In the data processing stage, data is cleaned and converted into a common canonical form.
For this solution, we use DataBrew to clean and convert orders into a common canonical form. DataBrew is a visual data preparation tool that makes it easy for data analysts and data scientists to prepare data with an interactive, point-and-click visual interface without writing code. DataBrew provides over 250 built-in transformations to combine, pivot, and transpose the data without writing code. The cleaning and transformation steps in DataBrew are called recipes. A scheduled DataBrew job applies the recipes to the data in an S3 bucket and stores the output in a different bucket.
AWS Glue crawlers can access data stores, extract metadata, and create table definitions in the AWS Glue Data Catalog. You can schedule a crawler to crawl the transformed data and create or update the Data Catalog. The AWS Glue Data Catalog is your persistent metadata store. It’s a managed service that lets you store, annotate, and share metadata in the AWS Cloud in the same way you would in an Apache Hive metastore. We use crawlers to populate the Data Catalog with tables.
Data analysis
We can query orders and inventory data from S3 buckets using Athena. Athena is an interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run. Views are created in Athena that can be consumed by business intelligence (BI) services like QuickSight.
Data visualization
We generate dashboards using QuickSight. QuickSight is a scalable, serverless, embeddable BI service powered by ML and built for the cloud. QuickSight lets you easily create and publish interactive BI dashboards that include ML-powered insights.
QuickSight also has features to forecast orders, detect anomalies in the order, and provide ML-powered insights. We can create analyses such as orders over a period of time, orders split by channel, top 10 locations for orders, or order fulfillment timelines (the time it took from order creation to order delivery).
Walkthrough overview
To implement this solution, you complete the following high-level steps:
- Create solution resources using AWS CloudFormation.
- Connect to the inventory database.
- Load the inventory database with tables.
- Create a VPC endpoint using Amazon Virtual Private Cloud (Amazon VPC).
- Create gateway endpoints for Amazon S3 on the default VPC.
- Enable CloudWatch rules via Amazon EventBridge to ingest the data.
- Transform the data using AWS Glue.
- Visualize the data with QuickSight.
Prerequisites
Complete the following prerequisite steps:
- Create AWS account if you don’t have done already.
- Sign up for QuickSight if you’ve never used QuickSight in this account before. To use the forecast ability in QuickSight, sign up for the Enterprise Edition.
Create resources with AWS CloudFormation
To launch the provided CloudFormation template, complete the following steps:
- Choose Launch Stack:

- Choose Next.
- For Stack name, enter a name.
- Provide the following parameters:
- The name of the S3 bucket that holds all the data for the data lake.
- The name of the database that holds the inventory tables.
- The database user name.
- The database password.
- Enter any tags you want to assign to the stack and choose Next.
- Select the acknowledgement check boxes and choose Create stack.
The stack takes 5–10 minutes to complete.
On the AWS CloudFormation console, you can navigate to the stack’s Outputs tab to review the resources you created.

If you open the S3 bucket you created, you can observe its folder structure. The stack creates sample order data for the last 7 days.

Connect to the inventory database
To connect to your database in the query editor, complete the following steps:
- On the Amazon RDS console, choose the Region you deployed the stack in.

- In the navigation pane, choose Query Editor.
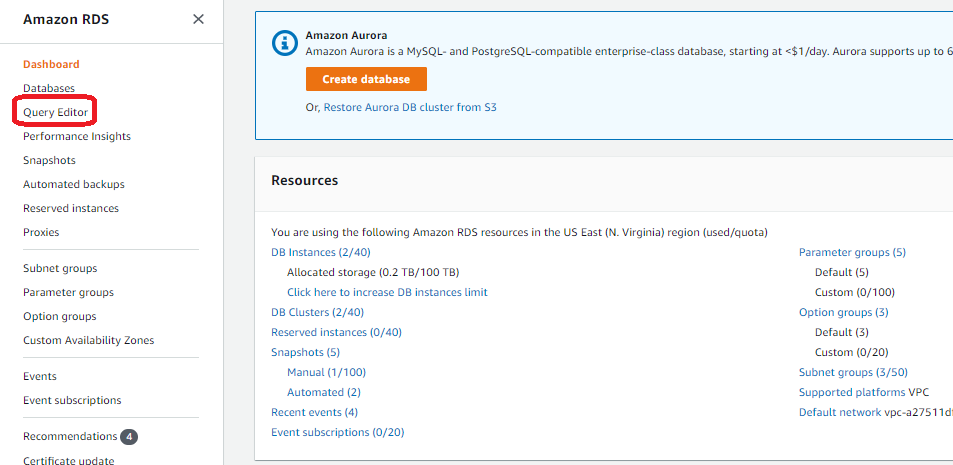
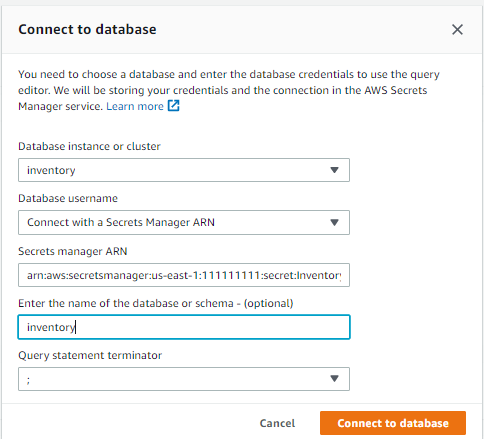
If you haven’t connected to this database before, the Connect to database page opens. - For Database instance or cluster, choose your database.
- For Database username, choose Connect with a Secrets Manager ARN.
The database user name and password provided during stack creation are stored in AWS Secrets Manager. Alternatively, you can choose Add new database credentials and enter the database user name and password you provided when creating the stack. - For Secrets Manager ARN, enter the value for the key
InventorySecretManagerfrom the CloudFormation stack outputs. - Optionally, enter the name of your database.
- Choose Connect to database.
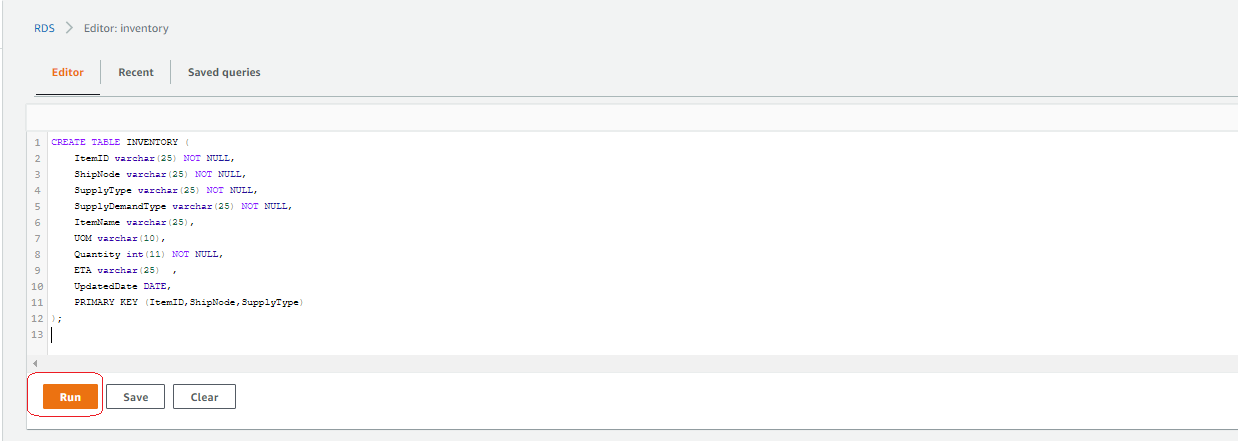
Load the inventory database with tables
Enter the following DDL statement in the query editor and choose Run:
Create a VPC endpoint
To create your VPC endpoint, complete the following steps:
- On the Amazon VPC console, choose VPC Dashboard.
- Choose Endpoints in the navigation pane.
- Choose Create Endpoint.

- For Service category, select AWS services.
- For Service name, search for
rdsand choose the service name ending withrds-data. - For VPC, choose the default VPC.

- Leave the remaining settings at their default and choose Create endpoint.
Create a gateway endpoint for Amazon S3
To create your gateway endpoint, complete the following steps:
- On the Amazon VPC console, choose VPC Dashboard.
- Choose Endpoints in the navigation pane.
- Choose Create Endpoint.
- For Service category, select AWS services.
- For Service name, search for
S3and choose the service name with type Gateway. - For VPC, choose the default VPC.
- For Configure route tables, select the default route table.
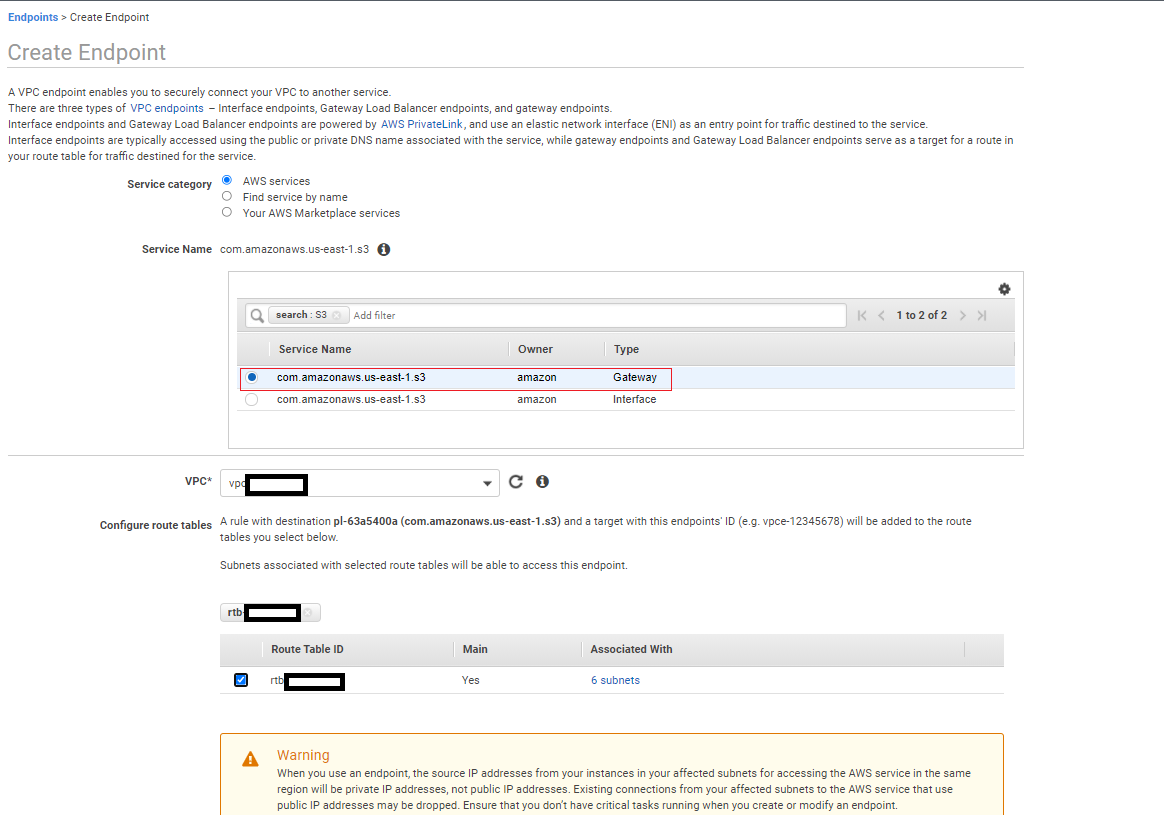
- Leave the remaining settings at their default and choose Create endpoint.
Wait for both the gateway endpoint and VPC endpoint status to change to Available.

Enable CloudWatch rules to ingest the data
We created two CloudWatch rules via the CloudFormation template to ingest the order and inventory data to Kinesis Data Streams. To enable the rules via EventBridge, complete the following steps:
- On the CloudWatch console, under Events in the navigation pane, choose Rules.
- Make sure you’re in the Region where you created the stack.
- Choose Go to Amazon EventBridge.

- Select the rule
Ingest-Inventory-Update-Schedule-Ruleand choose Enable. - Select the rule
Ingest-Order-Schedule-Ruleand choose Enable.

After 5–10 minutes, the Lambda functions start ingesting orders and inventory updates to their respective streams. You can check the S3 buckets orders-landing-zone and inventory-landing-zone to confirm that the data is being populated.
Perform data transformation
Our CloudFormation stack included a DataBrew project, a DataBrew job that runs every 5 minutes, and two AWS Glue crawlers. To perform data transformation using our AWS Glue resources, complete the following steps:
- On the DataBrew console, choose Projects in the navigation pane.
- Choose the project
OrderDataTransform.

You can review the project and its recipe on this page.

- In the navigation pane, choose Jobs.
- Review the job status to confirm it’s complete.

- On the AWS Glue console, choose Crawlers in the navigation pane.
The crawlers crawl the transformed data and update the Data Catalog. - Review the status of the two crawlers, which run every 15 minutes.

- Choose Tables in the navigation pane to view the two tables the crawlers created.
If you don’t see these tables, you can run the crawlers manually to create them.
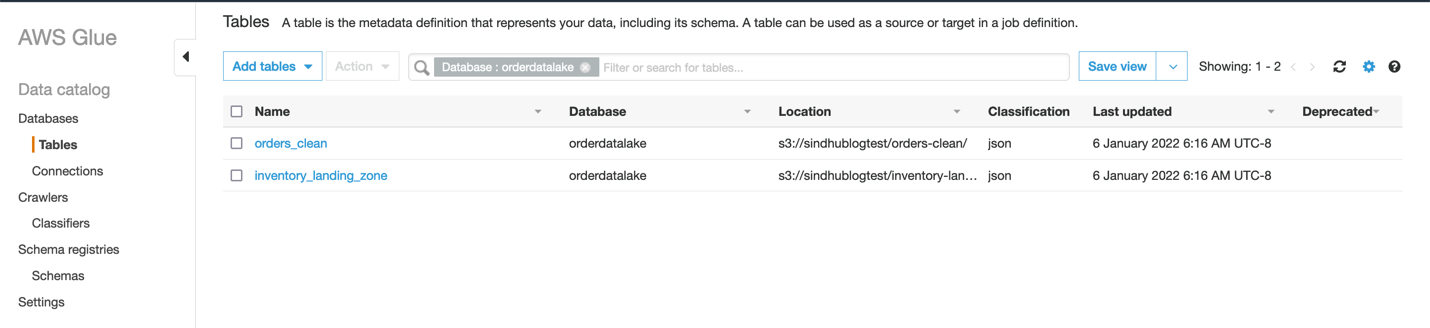
You can query the data in the tables with Athena. - On the Athena console, choose Query editor.
If you haven’t created a query result location, you’re prompted to do that first. - Choose View settings or choose the Settings tab.

- Choose Manage.
- Select the S3 bucket to store the results and choose Choose.

- Choose Query editor in the navigation pane.

- Choose either table (right-click) and choose Preview Table to view the table contents.

Visualize the data
If you have never used QuickSight in this account before, complete the prerequisite step to sign up for QuickSight. To use the ML capabilities of QuickSight (such as forecasting) sign up for the Enterprise Edition using the steps in this documentation.
While signing up for QuickSight, make sure to use the same region where you created the CloudFormation stack.
Grant QuickSight permissions
To visualize your data, you must first grant relevant permissions to QuickSight to access your data.
- On the QuickSight console, on the Admin drop-down menu, choose Manage QuickSight.

- In the navigation pane, choose Security & permissions.
- Under QuickSight access to AWS services, choose Manage.

- Select Amazon Athena.
- Select Amazon S3 to edit QuickSight access to your S3 buckets.
- Select the bucket you specified during stack creation (for this post,
operational-datalake). - Choose Finish.

- Choose Save.
Prepare the datasets
To prepare your datasets, complete the following steps:
- On the QuickSight console, choose Datasets in the navigation pane.
- Choose New dataset.
- Choose Athena.
- For Data source name, enter
retail-analysis. - Choose Validate connection.
- After your connection is validated, choose Create data source.

- For Database, choose
orderdatalake. - For Tables, select
orders_clean. - Choose Edit/Preview data.

- For Query mode, select SPICE.
SPICE (Super-fast, Parallel, In-memory Calculation Engine) is the robust in-memory engine that QuickSight uses.

- Choose the
orderdatetimefield (right-click), choose Change data type, and choose Date.
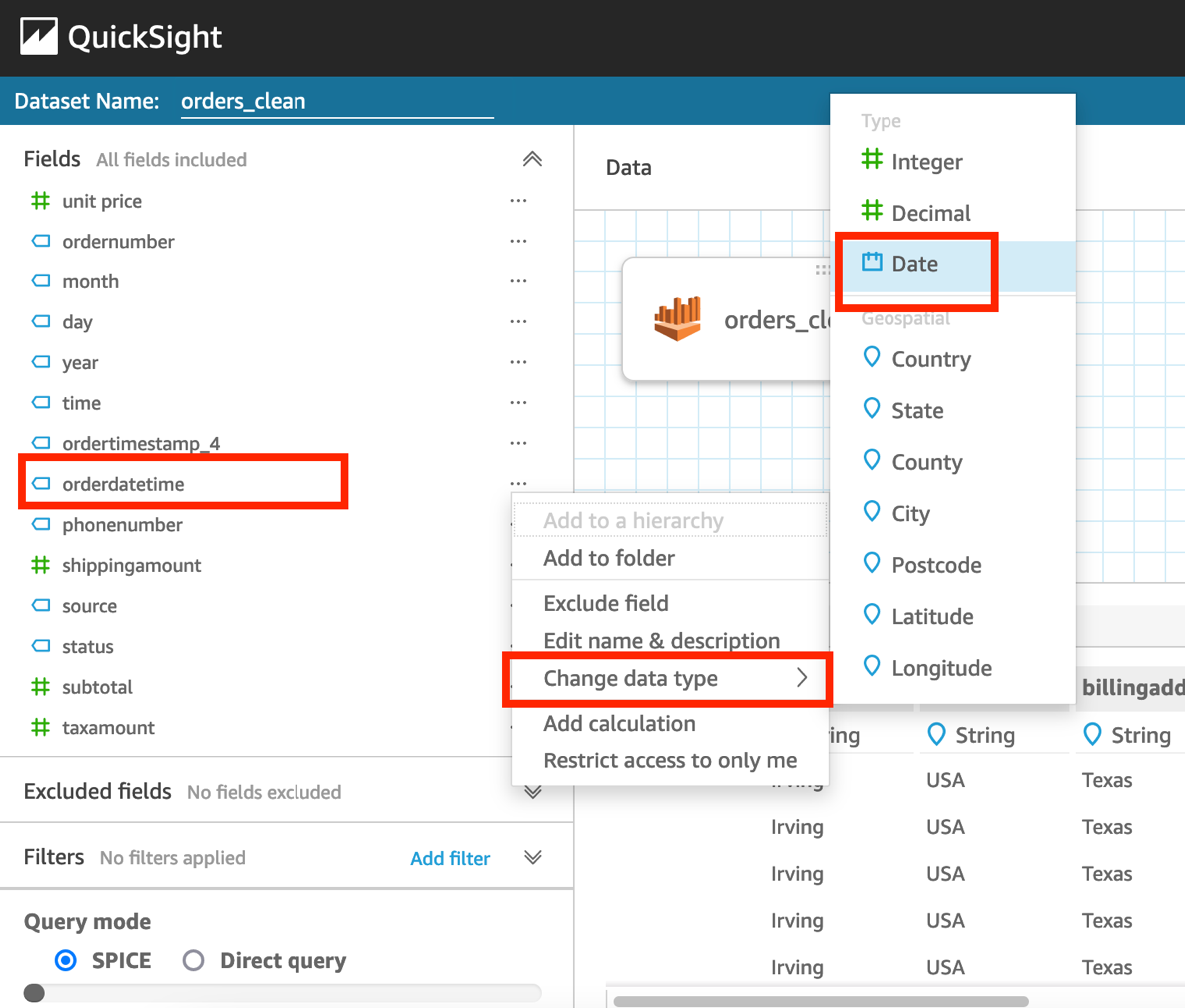
- Enter the date format as
MM/dd/yyyy HH:mm:ss. - Choose Validate and Update.

- Change the data types of the following fields to QuickSight geospatial data types:
- billingaddress.zipcode – Postcode
- billingaddress.city – City
- billingaddress.country – Country
- billingaddress.state – State
- shippingaddress.zipcode – Postcode
- shippingaddress.city – City
- shippingaddress.country – Country
- shippingaddress.state – State
- Choose Save & publish.
- Choose Cancel to exit this page.

Let’s create another dataset for the Athena tableinventory_landing_zone. - Follow steps 1–7 to create a new dataset. For Table selection, choose
inventory_landing_zone. - Choose Edit/Preview data.
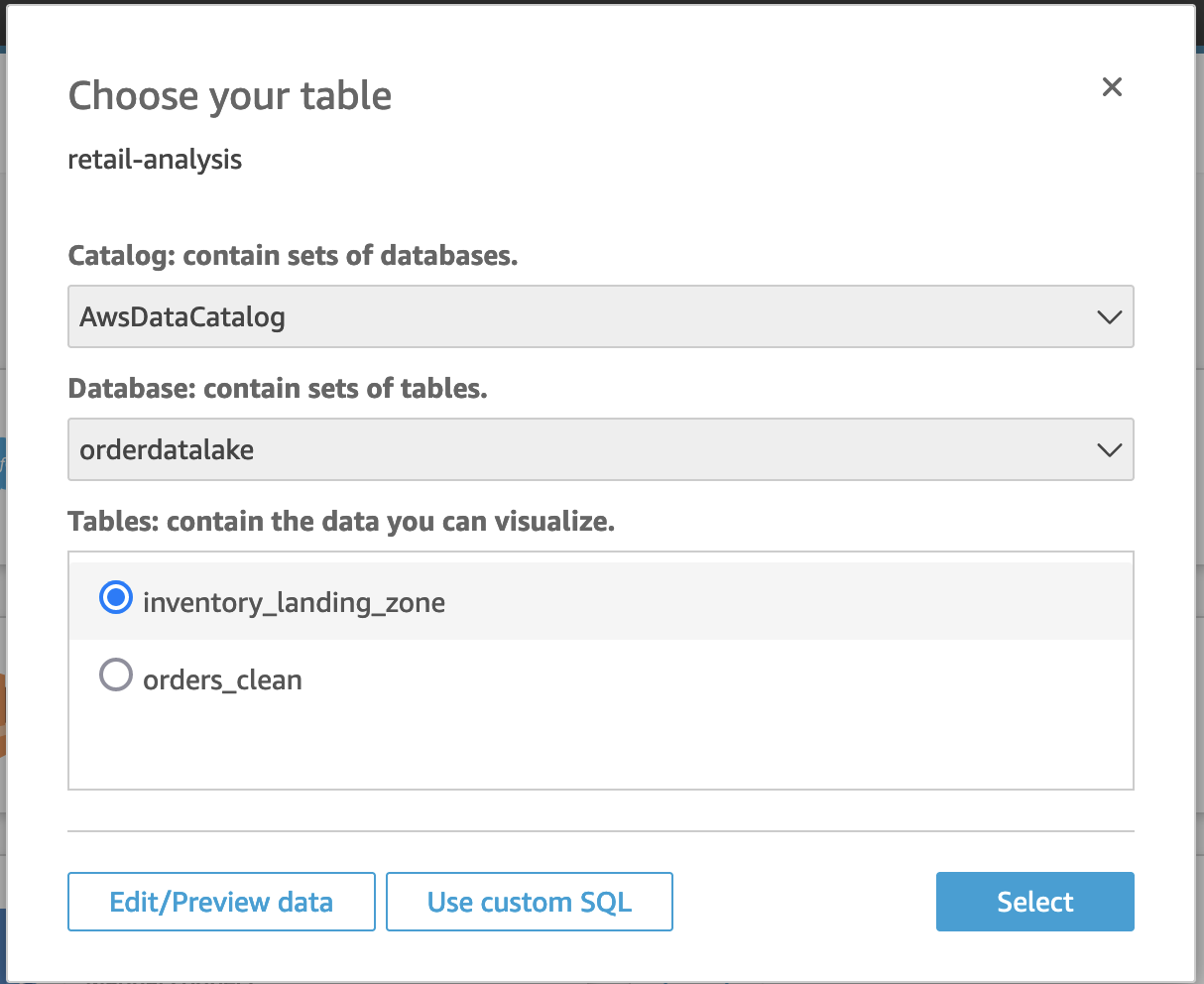
- For Query mode, select SPICE.
- Choose Save & publish.
- Choose Cancel to exit this page.

Both datasets should now be listed on the Datasets page.

- Choose each dataset and choose Refresh now.

- Select Full refresh and choose Refresh.

To set up a scheduled refresh, choose Schedule a refresh and provide your schedule details.

Create an analysis
To create an analysis in QuickSight, complete the following steps:
- On the QuickSight console, choose Analyses in the navigation pane.
- Choose New analysis.
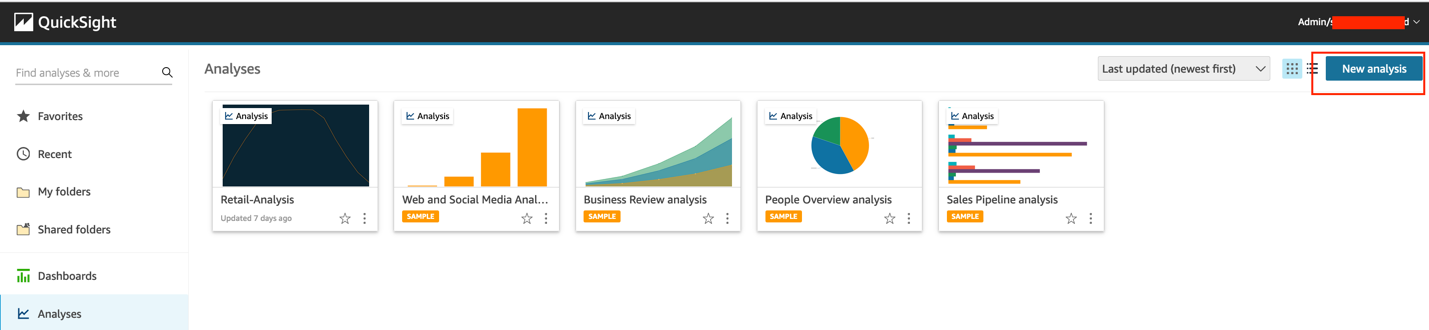
- Choose the
orders_cleandataset.
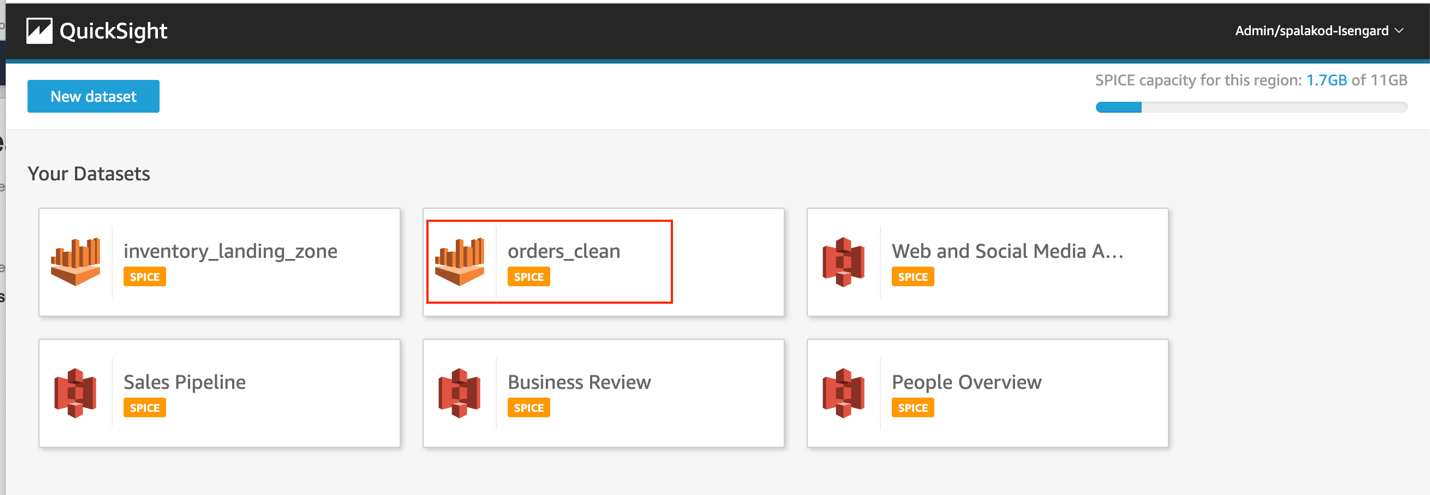
- Choose Create analysis.

- To adjust the theme, choose Themes in the navigation pane, choose your preferred theme, and choose Apply.

- Name the analysis
retail-analysis.
Add visualizations to the analysis
Let’s start creating visualizations. The first visualization shows orders created over time.
- Choose the empty graph on the dashboard and for Visual type¸ choose the line chart.
For more information about visual types, see Visual types in Amazon QuickSight.

- Under Field wells, drag
orderdatetimeto X axis andordernumberto Value. - Set
ordernumberto Aggregate: Count distinct.

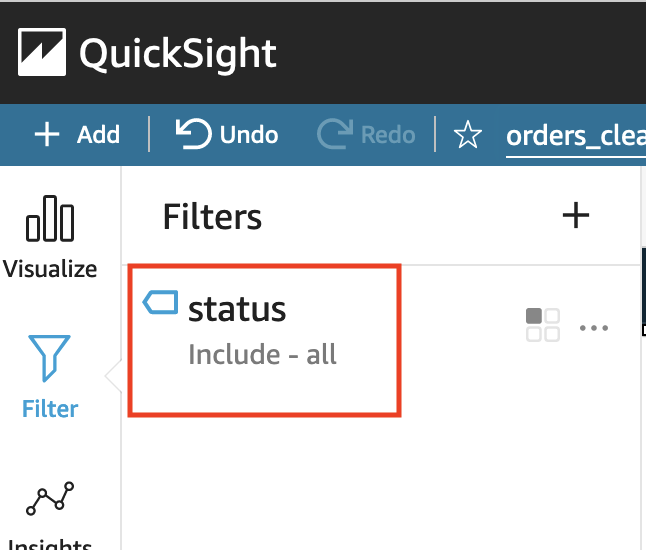
Now we can filter these orders byCreatedstatus. - Choose Filter in the navigation pane and choose Create one.
- Search for and choose status.

- Choose the status filter you just created.

- Select Created from the filter list and choose Apply.

- Choose the graph (right-click) and choose Add forecast.
The forecasting ability is only available in the Enterprise Edition. QuickSight uses a built-in version of the Random Cut Forest (RCF) algorithm. For more information, refer to Understanding the ML algorithm used by Amazon QuickSight.

- Leave the settings as default and choose Apply.
- Rename the visualization to “Orders Created Over Time.”

If the forecast is applied successfully, the visualization shows the expected number of orders as well as upper and lower bounds.

If you get the following error message, allow for the data to accumulate for a few days before adding the forecast.

Let’s create a visualization on orders by location.
- On the Add menu, choose Add visual.

- Choose the points on map visual type.

- Under Field wells, drag
shippingaddress.zipcodeto Geospatial andordernumberto Size. - Change
ordernumberto Aggregate: Count distinct.

You should now see a map indicating the orders by location. - Rename the visualization accordingly.

Next, we create a drill-down visualization on the inventory count. - Choose the pencil icon.

- Choose Add dataset.

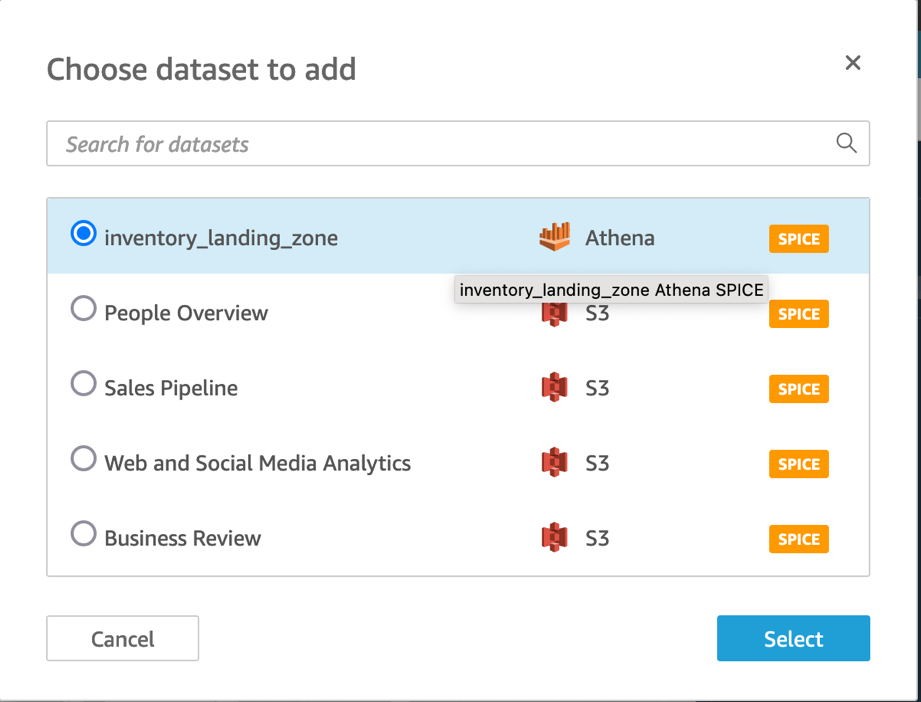
- Select the
inventory_landing_zonedataset and choose Select.

- Choose the
inventory_landing_zonedataset.

- Add the vertical bar chart visual type.

- Under Field wells, drag
itemname,shipnode, andinvtypeto X axis, and quantity to Value. - Make sure that quantity is set to Sum.

The following screenshot shows an example visualization of order inventory.

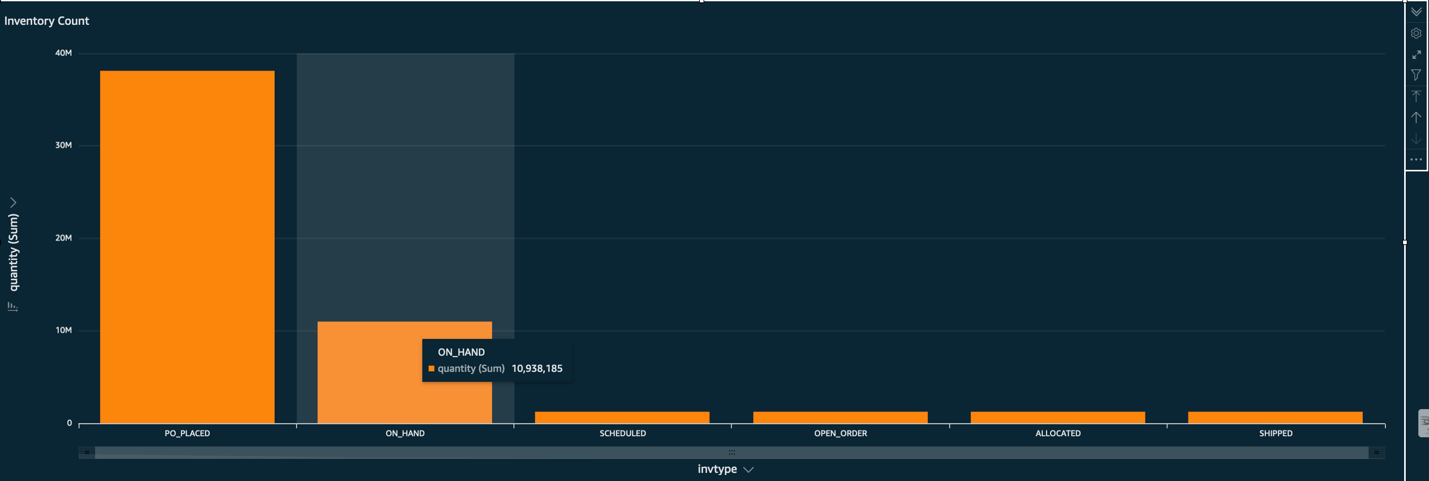
- To determine how many face masks were shipped out from each ship node, choose Face Masks (right-click) and choose Drill down to shipnode.

- You can drill down even further to
invtypeto see how many face masks in a specific ship node are in which status.




The following screenshot shows this drilled-down inventory count.
As a next step, you can create a QuickSight dashboard from the analysis you created. For instructions, refer to Tutorial: Create an Amazon QuickSight dashboard.
Clean up
To avoid any ongoing charges, on the AWS CloudFormation console, select the stack you created and choose Delete. This deletes all the created resources. On the stack’s Events tab, you can track the progress of the deletion, and wait for the stack status to change to DELETE_COMPLETE.
The Amazon EventBridge rules generate orders and inventory data every 15 minutes, to avoid generating huge amount of data, please ensure to delete the stack after testing the blog.
If the deletion of any resources fails, ensure that you delete them manually. For deleting Amazon QuickSight datasets, you can follow these instructions. You can delete the QuickSight Analysis using these steps. For deleting the QuickSight subscription and closing the account, you can follow these instructions.
Conclusion
In this post, we showed you how to use AWS analytics and storage services to build a serverless operational data lake. Kinesis Data Streams lets you ingest large volumes of data, and DataBrew lets you cleanse and transform the data visually. We also showed you how to analyze and visualize the order and inventory data using AWS Glue, Athena, and QuickSight. For more information and resources for data lakes on AWS, visit Analytics on AWS.
About the Authors
 Gandhi Raketla is a Senior Solutions Architect for AWS. He works with AWS customers and partners on cloud adoption, as well as architecting solutions that help customers foster agility and innovation. He specializes in the AWS data analytics domain.
Gandhi Raketla is a Senior Solutions Architect for AWS. He works with AWS customers and partners on cloud adoption, as well as architecting solutions that help customers foster agility and innovation. He specializes in the AWS data analytics domain.
 Sindhura Palakodety is a Solutions Architect at AWS. She is passionate about helping customers build enterprise-scale Well-Architected solutions on the AWS Cloud and specializes in the containers and data analytics domains.
Sindhura Palakodety is a Solutions Architect at AWS. She is passionate about helping customers build enterprise-scale Well-Architected solutions on the AWS Cloud and specializes in the containers and data analytics domains.