AWS Big Data Blog
Author: Behram Irani

Query data in Amazon OpenSearch Service using SQL from Amazon Athena
Amazon Athena is an interactive serverless query service to query data from Amazon Simple Storage Service (Amazon S3) in standard SQL. Amazon OpenSearch Service is a fully managed, open-source, distributed search and analytics suite derived from Elasticsearch, allowing you to run OpenSearch Service or Elasticsearch clusters at scale without having to manage hardware provisioning, software […]
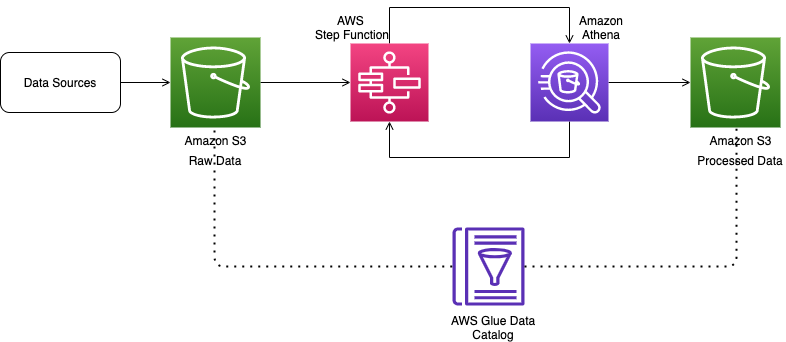
Build and orchestrate ETL pipelines using Amazon Athena and AWS Step Functions
Extract, transform, and load (ETL) is the process of reading source data, applying transformation rules to this data, and loading it into the target structures. ETL is performed for various reasons. Sometimes ETL helps align source data to target data structures, whereas other times ETL is done to derive business value by cleansing, standardizing, combining, […]
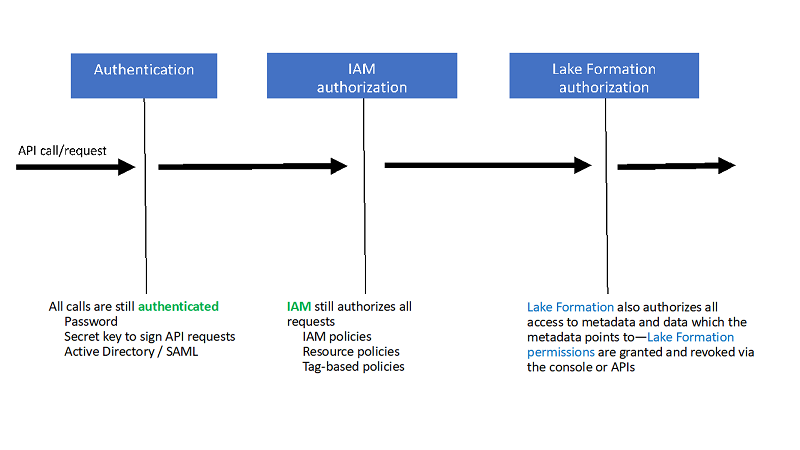
Enable fine-grained data access in Zeppelin Notebook with AWS Lake Formation
This post explores how you can use AWS Lake Formation integration with Amazon EMR (still in beta) to implement fine-grained column-level access controls while using Spark in a Zeppelin Notebook. My previous post Extract Salesforce.com data using AWS Glue and analyzing with Amazon Athena showed you a simple use case for extracting any Salesforce object data using AWS Glue and Apache Spark, saving it to Amazon Simple Storage Service (Amazon S3), cataloging the data using the Data Catalog in Glue, and querying it using Amazon Athena.
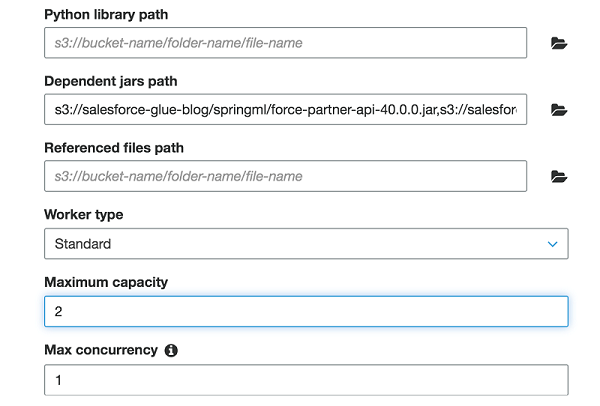
Extract Salesforce.com data using AWS Glue and analyzing with Amazon Athena
In this post, I show you how to use AWS Glue to extract data from a Salesforce.com account object and save it to Amazon S3. You then use Amazon Athena to generate a report by joining the account object data from Salesforce.com with the orders data from a separate order management system.