AWS Big Data Blog
Author: Sakti Mishra

Top analytics announcements of AWS re:Invent 2024
AWS re:Invent 2024, the flagship annual conference, took place December 2–6, 2024, in Las Vegas, bringing together thousands of cloud enthusiasts, innovators, and industry leaders from around the globe. Analytics remained one of the key focus areas this year, with significant updates and innovations aimed at helping businesses harness their data more efficiently and accelerate insights. In this post, we walk you through the top analytics announcements from re:Invent 2024 and explore how these innovations can help you unlock the full potential of your data.

Enforce fine-grained access control on data lake tables using AWS Glue 5.0 integrated with AWS Lake Formation
AWS Glue 5.0 supports fine-grained access control (FGAC) based on your policies defined in AWS Lake Formation. FGAC enables you to granularly control access to your data lake resources at the table, column, and row levels. This post demonstrates how to enforce FGAC on AWS Glue 5.0 through Lake Formation permissions.

Unstructured data management and governance using AWS AI/ML and analytics services
In this post, we discuss how AWS can help you successfully address the challenges of extracting insights from unstructured data. We discuss various design patterns and architectures for extracting and cataloging valuable insights from unstructured data using AWS. Additionally, we show how to use AWS AI/ML services for analyzing unstructured data.

Implement a CDC-based UPSERT in a data lake using Apache Iceberg and AWS Glue
May 2023: This post was reviewed and updated with code to read and write data to Iceberg table using Native iceberg connector, in the Appendix section. As the implementation of data lakes and modern data architecture increases, customers’ expectations around its features also increase, which include ACID transaction, UPSERT, time travel, schema evolution, auto compaction, […]

Orchestrate an Amazon EMR on Amazon EKS Spark job with AWS Step Functions
At re:Invent 2020, we announced the general availability of Amazon EMR on Amazon EKS, a new deployment option for Amazon EMR that allows you to automate the provisioning and management of open-source big data frameworks on Amazon Elastic Kubernetes Service (Amazon EKS). With Amazon EMR on EKS, you can now run Spark applications alongside other […]
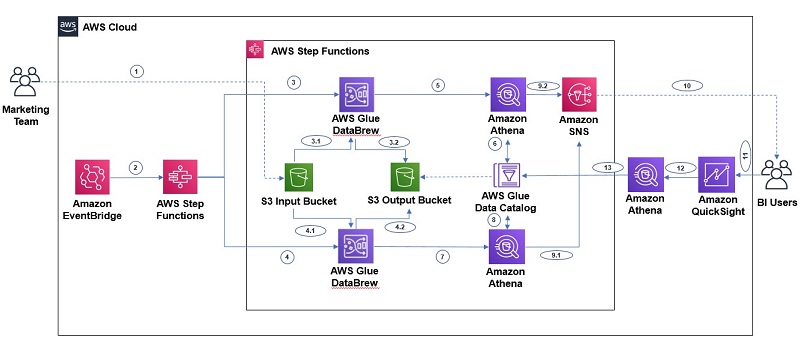
Orchestrating an AWS Glue DataBrew job and Amazon Athena query with AWS Step Functions
As the industry grows with more data volume, big data analytics is becoming a common requirement in data analytics and machine learning (ML) use cases. Also, as we start building complex data engineering or data analytics pipelines, we look for a simpler orchestration mechanism with graphical user interface-based ETL (extract, transform, load) tools. Recently, AWS […]
Stream, transform, and analyze XML data in real time with Amazon Kinesis, AWS Lambda, and Amazon Redshift
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. When we look at […]
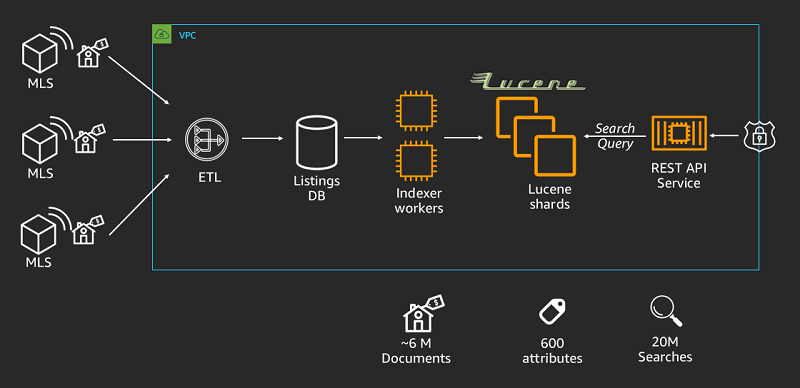
Simplifying and modernizing home search at Compass with Amazon OpenSearch Service
September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details. Amazon OpenSearch Service is a fully managed service that makes it easy for you to deploy, secure, and operate OpenSearch in AWS at scale. It’s a widely popular service and different customers integrate it in their applications for different search […]