AWS Big Data Blog
Author: Mohit Saxena
Optimize memory management in AWS Glue
In this post, we discuss a number of techniques to enable efficient memory management for Apache Spark applications when reading data from Amazon S3 and compatible databases using a JDBC connector. We describe how Glue ETL jobs can utilize the partitioning information available from AWS Glue Data Catalog to prune large datasets, manage large number of small files, and use JDBC optimizations for partitioned reads and batch record fetch from databases. You can use some or all of these techniques to help ensure your ETL jobs perform well.

Simplify data pipelines with AWS Glue automatic code generation and Workflows
In this post, we discuss how to leverage the automatic code generation process in AWS Glue ETL to simplify common data manipulation tasks, such as data type conversion and flattening complex structures. We also explore using AWS Glue Workflows to build and orchestrate data pipelines of varying complexity. Lastly, we look at how you can leverage the power of SQL, with the use of AWS Glue ETL and Glue Data Catalog, to query and transform your data.

Load data incrementally and optimized Parquet writer with AWS Glue
October 2022: This post was reviewed for accuracy. AWS Glue provides a serverless environment to prepare (extract and transform) and load large amounts of datasets from a variety of sources for analytics and data processing with Apache Spark ETL jobs. The first post of the series, Best practices to scale Apache Spark jobs and partition […]

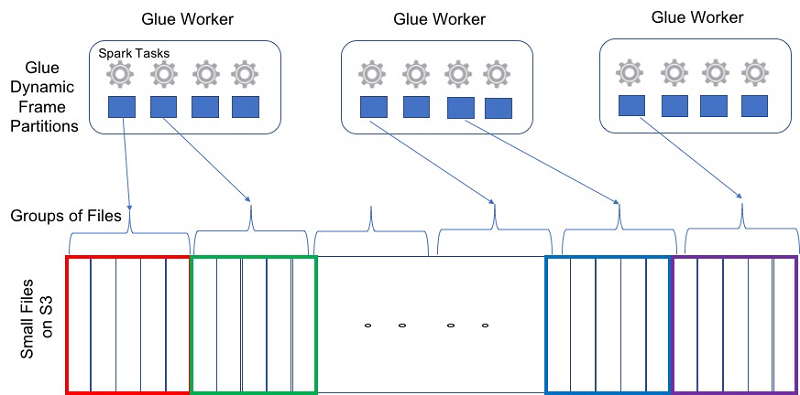
Best practices to scale Apache Spark jobs and partition data with AWS Glue
The first post of this series discusses two key AWS Glue capabilities to manage the scaling of data processing jobs. The first allows you to horizontally scale out Apache Spark applications for large splittable datasets. The second allows you to vertically scale up memory-intensive Apache Spark applications with the help of new AWS Glue worker types. The post also shows how to use AWS Glue to scale Apache Spark applications with a large number of small files commonly ingested from streaming applications using Amazon Kinesis Data Firehose. Finally, the post shows how AWS Glue jobs can use the partitioning structure for large datasets in Amazon S3 to provide faster execution times for Apache Spark applications.