AWS Big Data Blog
Author: Francisco Oliveira
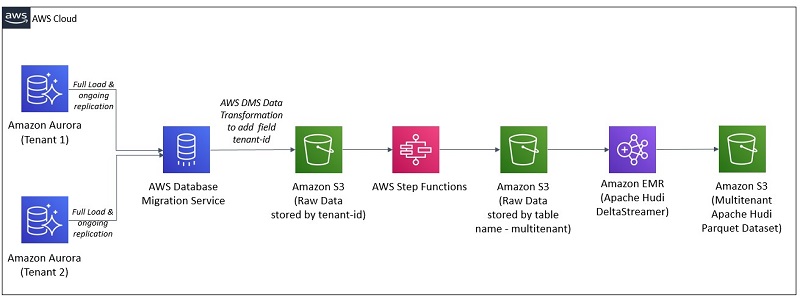
Multi-tenant processing pipelines with AWS DMS, AWS Step Functions, and Apache Hudi on Amazon EMR
Large enterprises often provide software offerings to multiple customers by providing each customer a dedicated and isolated environment (a software offering composed of multiple single-tenant environments). Because the data is in various independent systems, large enterprises are looking for ways to simplify data processing pipelines. To address this, you can create data lakes to bring […]

Orchestrate big data workflows with Apache Airflow, Genie, and Amazon EMR: Part 2
In Part 1 of this post series, you learned how to use Apache Airflow, Genie, and Amazon EMR to manage big data workflows. This post guides you through deploying the AWS CloudFormation templates, configuring Genie, and running an example workflow authored in Apache Airflow.
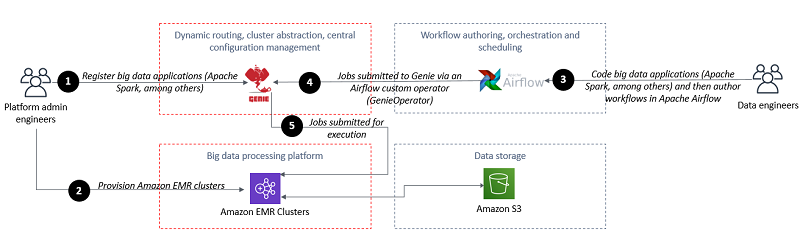
Orchestrate big data workflows with Apache Airflow, Genie, and Amazon EMR: Part 1
This post introduces an architecture that helps centralized platform teams maintain a big data platform to service thousands of concurrent ETL workflows, and simplifies the operational tasks required to accomplish that.

Migrate to Apache HBase on Amazon S3 on Amazon EMR: Guidelines and Best Practices
This whitepaper walks you through the stages of a migration. It also helps you determine when to choose Apache HBase on Amazon S3 on Amazon EMR, plan for platform security, tune Apache HBase and EMRFS to support your application SLA, identify options to migrate and restore your data, and manage your cluster in production.

Submitting User Applications with spark-submit
Francisco Oliveira is a consultant with AWS Professional Services Customers starting their big data journey often ask for guidelines on how to submit user applications to Spark running on Amazon EMR. For example, customers ask for guidelines on how to size memory and compute resources available to their applications and the best resource allocation model […]