AWS Big Data Blog
Author: Ashok Padmanabhan

Optimize industrial IoT analytics with Amazon Data Firehose and Amazon S3 Tables with Apache Iceberg
In this post, we show how to use AWS service integrations to minimize custom code while providing a robust platform for industrial data ingestion, processing, and analytics. By using Amazon S3 Tables and its built-in optimizations, you can maximize query performance and minimize costs without additional infrastructure setup.
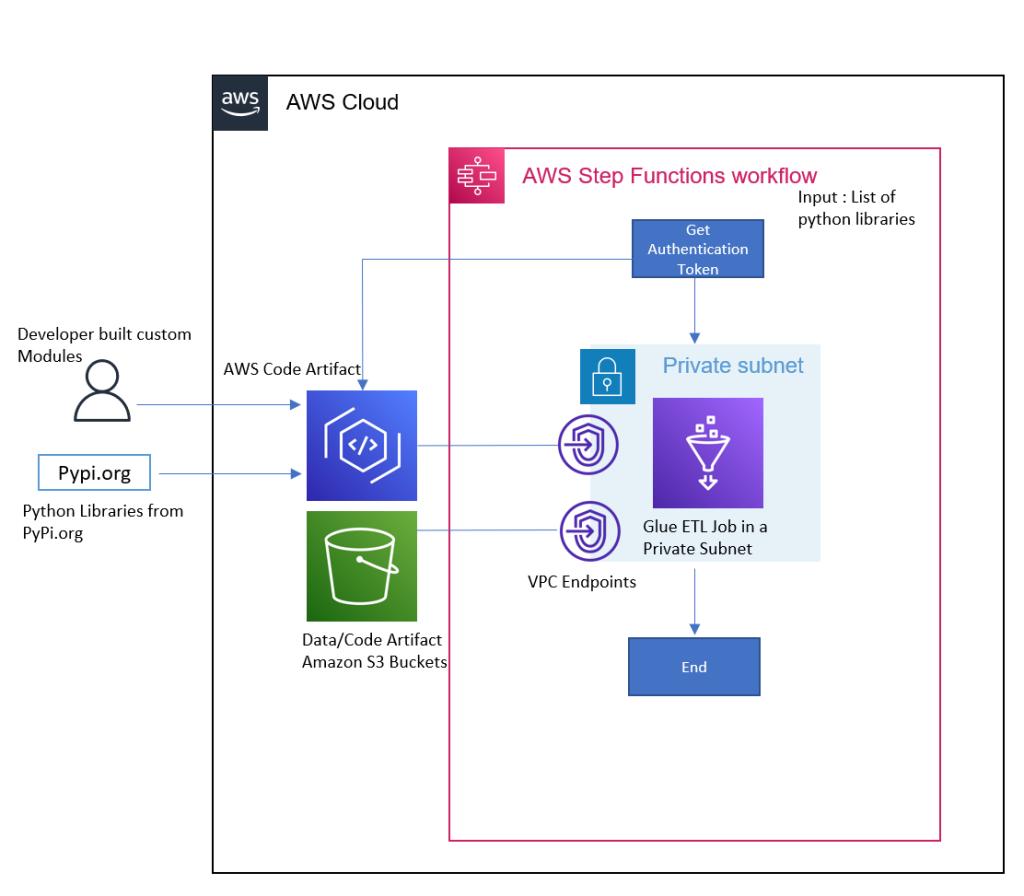
Simplify and optimize Python package management for AWS Glue PySpark jobs with AWS CodeArtifact
Data engineers use various Python packages to meet their data processing requirements while building data pipelines with AWS Glue PySpark Jobs. Languages like Python and Scala are commonly used in data pipeline development. Developers can take advantage of their open-source packages or even customize their own to make it easier and faster to perform use […]