AWS Big Data Blog

Author: Randy DeFauw
Randy DeFauw is a Sr. Principal Solutions Architect at AWS. He has over 20 years of experience in technology, starting with his university work on autonomous vehicles. He has worked with and for users ranging from startups to Fortune 50 companies, launching Big Data and Machine Learning applications. He holds an MSEE and an MBA, serves as a board advisor to K-12 STEM education initiatives, and has spoken at leading conferences including Strata and GlueCon. He is the co-author of the book SageMaker Best Practices.

Build a RAG data ingestion pipeline for large-scale ML workloads
For building any generative AI application, enriching the large language models (LLMs) with new data is imperative. This is where the Retrieval Augmented Generation (RAG) technique comes in. RAG is a machine learning (ML) architecture that uses external documents (like Wikipedia) to augment its knowledge and achieve state-of-the-art results on knowledge-intensive tasks. For ingesting these […]
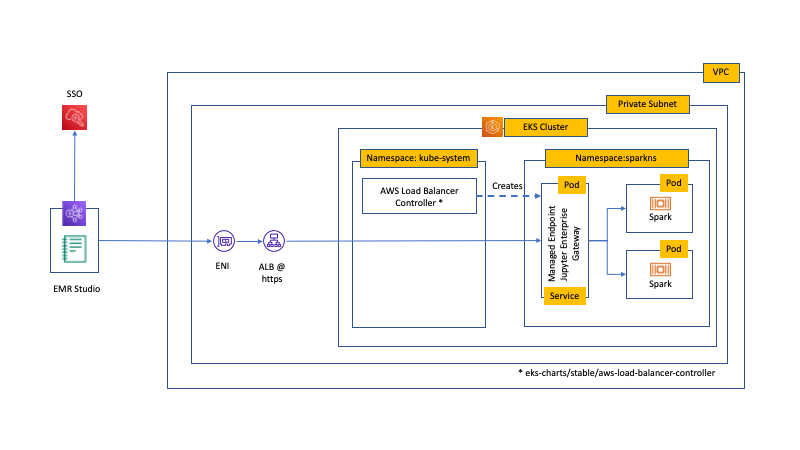
Configure Amazon EMR Studio and Amazon EKS to run notebooks with Amazon EMR on EKS
Amazon EMR on Amazon EKS provides a deployment option for Amazon EMR that allows you to run analytics workloads on Amazon Elastic Kubernetes Service (Amazon EKS). This is an attractive option because it allows you to run applications on a common pool of resources without having to provision infrastructure. In addition, you can use Amazon […]