AWS Big Data Blog
Author: Karthik Sonti
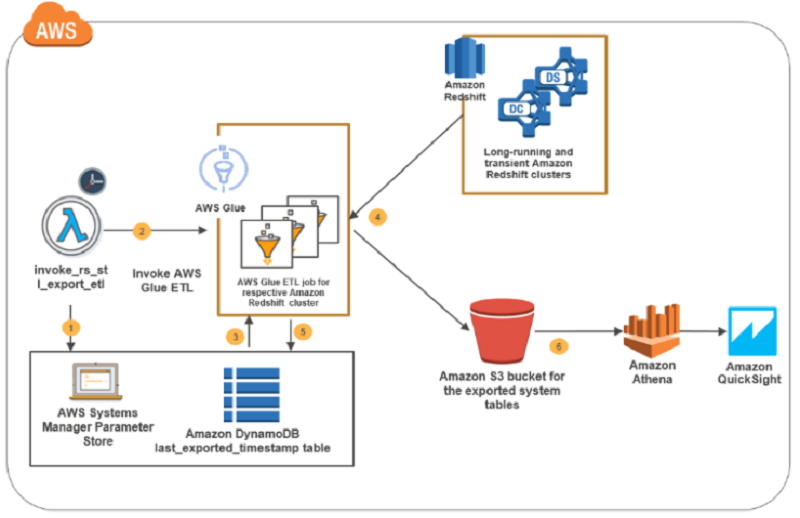
How to retain system tables’ data spanning multiple Amazon Redshift clusters and run cross-cluster diagnostic queries
In this blog post, I present a solution that exports system tables from multiple Amazon Redshift clusters into an Amazon S3 bucket. This solution is serverless, and you can schedule it as frequently as every five minutes. The AWS CloudFormation deployment template that I provide automates the solution setup in your environment. The system tables’ data in the Amazon S3 bucket is partitioned by cluster name and query execution date to enable efficient joins in cross-cluster diagnostic queries.

Building Event-Driven Batch Analytics on AWS
In this post, I walk you through an architectural approach as well as a sample implementation on how to collect, process, and analyze data for event-driven applications in AWS.