AWS Big Data Blog
Author: Udit Mehrotra
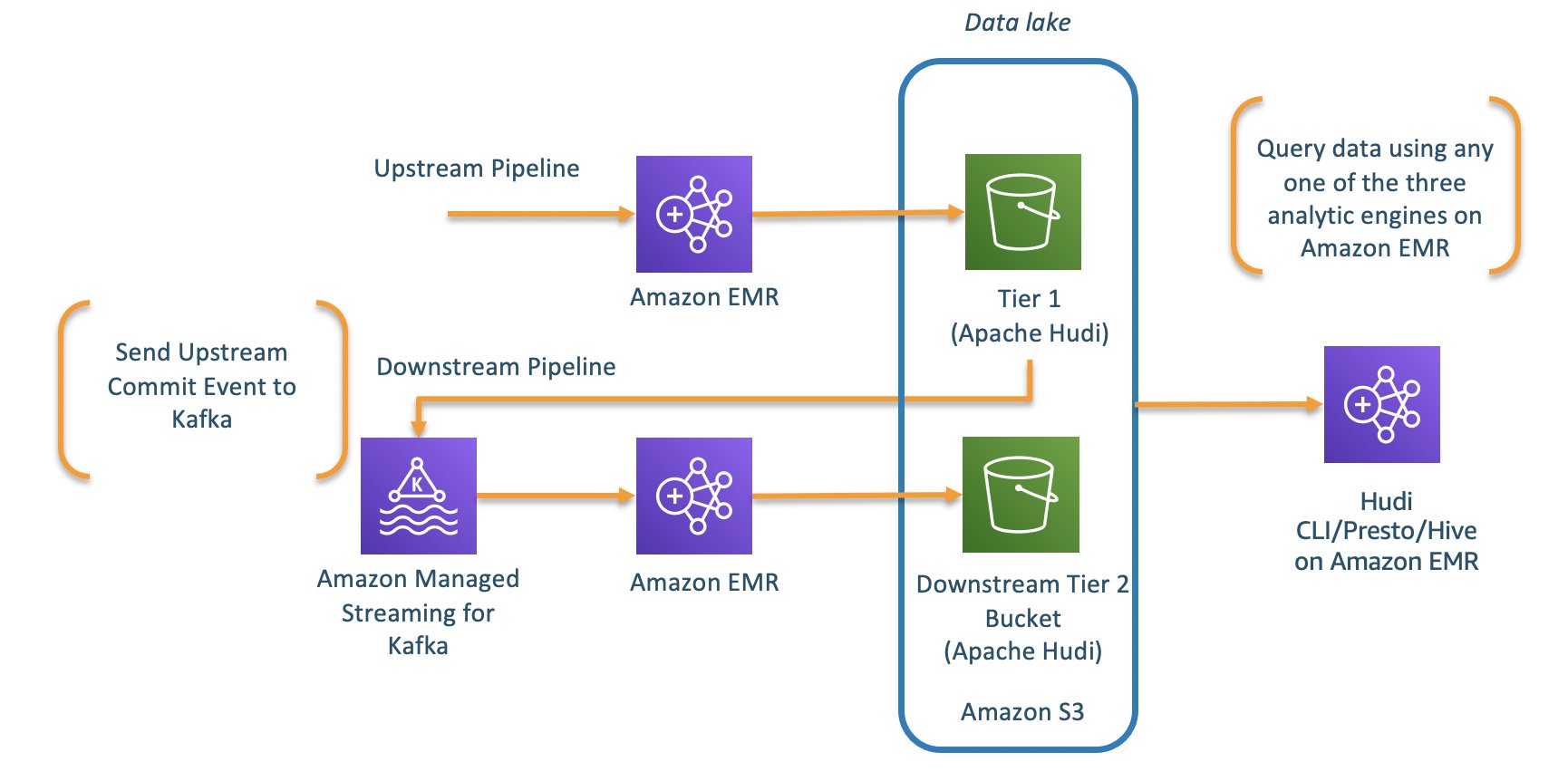
New features from Apache Hudi 0.7.0 and 0.8.0 available on Amazon EMR
Apache Hudi is an open-source transactional data lake framework that greatly simplifies incremental data processing and data pipeline development by providing record-level insert, update, and delete capabilities. This record-level capability is helpful if you’re building your data lakes on Amazon Simple Storage Service (Amazon S3) or Hadoop Distributed File System (HDFS). You can use it […]
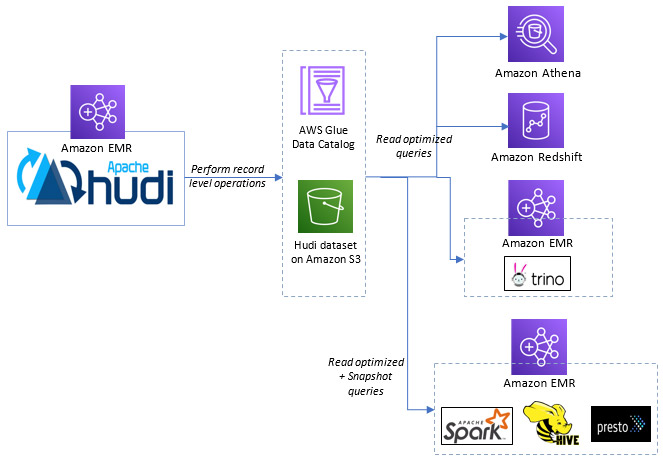
New features from Apache Hudi available in Amazon EMR
Apache Hudi is an open-source data management framework used to simplify incremental data processing and data pipeline development by providing record-level insert, update and delete capabilities. This record-level capability is helpful if you’re building your data lakes on Amazon S3 or HDFS. You can use it to comply with data privacy regulations and simplify data […]

Spark enhancements for elasticity and resiliency on Amazon EMR
This blog post provides an overview of the issues with how open-source Spark handles node loss and the improvements in Amazon EMR to address the issues.