AWS Big Data Blog
Best practices for consuming Amazon Kinesis Data Streams using AWS Lambda
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more.
December 2022: This post was reviewed for accuracy.
Many organizations are processing and analyzing clickstream data in real time from customer-facing applications to look for new business opportunities and identify security incidents in real time. A common practice is to consolidate and enrich logs from applications and servers in real time to proactively identify and resolve failure scenarios and significantly reduce application downtime. Internet of things (IOT) is also driving more adoption for real-time data processing. For example, a connected factory, connected cars, and smart spaces enable seamless sharing of information between people, machines, and sensors.
To help ingest real-time data or streaming data at large scales, you can use Amazon Kinesis Data Streams. Kinesis Data Streams can continuously capture gigabytes of data per second from hundreds of thousands of sources. The data collected is available in milliseconds, enabling real-time analytics. You can use an AWS Lambda function to process records in a Kinesis data stream.
This post discusses common use cases for Lambda stream processing and describes how to optimize the integration between Kinesis Data Streams and Lambda at high throughput with low system overhead and processing latencies.
Using Lambda to process a Kinesis data stream
Before diving into best practices, we discuss good use cases for Lambda stream processing and anti-patterns.
When to use Lambda for Kinesis data stream processing
Lambda integrates natively with Kinesis Data Streams. The polling, checkpointing, and error handling complexities are abstracted when you use this native integration. This allows the Lambda function code to focus on business logic processing. For example, one application can take in IP addresses from the streaming records and enrich them with geographic fields. Another application can take in all system logs from the stream and filter out non-critical ones. Another common use case is to take in text-based system logs and transform them into JSON format.
One key pattern the previous examples share is that the transformation works on a per-record basis. You can still receive batches of records, but the transformation of the records happens individually.
When not to use Lambda for Kinesis data stream processing
By default, Lambda invocates one instance per Kinesis shard. Lambda invokes your function as soon as it has gathered a full batch, or until the batch window expires, as shown in the following diagram.

This means each Lambda invocation only holds records from one shard, so each Lambda invocation is ephemeral and there can be arbitrarily small batch windows for any invocation. Therefore, the following use cases are challenging for Lambda stream processing:
- Correlation of events of different shards
- Stateful stream processing, such as windowed aggregations
- Buffering large volumes of streaming data before writing elsewhere
For the first two use cases, consider using Amazon Kinesis Data Analytics. Kinesis Data Analytics allows you to transform and analyze streaming data in real time. You can build sophisticated streaming applications with Apache Flink. Apache Flink is an open-source framework and engine for processing data streams. Kinesis Data Analytics takes care of everything required to run streaming applications continuously, and scales automatically to match the volume and throughput of your incoming data.
For the third use case, consider using Amazon Kinesis Data Firehose. Kinesis Data Firehose is the easiest way to reliably load streaming data into data lakes, data stores, and analytics services. It can capture, transform, and deliver streaming data to Amazon Simple Storage Service (Amazon S3), Amazon Redshift, Amazon OpenSearch Service, generic HTTP endpoints, and service providers like Datadog, New Relic, MongoDB, and Splunk. Kinesis Data Firehose enables you to transform your data with Lambda before it’s loaded to data stores.
Developing a Lambda consumer with shared throughput or dedicated throughput
You can use Lambda in two different ways to consume data stream records: you can map a Lambda function to a shared-throughput consumer (standard iterator), or to a dedicated-throughput consumer with enhanced fan-out (EFO).
For standard iterators, Lambda service polls each shard in your stream one time per second for records using HTTP protocol. By default, Lambda invokes your function as soon as records are available in the stream. The invocated instances shares read throughput with other consumers of the shard. Each shard in a data stream provides 2 MB/second of read throughput. You can increase stream throughput by adding more shards. When it comes to latency, the Kinesis Data Streams GetRecords API has a five reads per second per shard limit. This means you can achieve 200-millisecond data retrieval latency for one consumer. With more consumer applications, propagation delay increases. For example, with five consumer applications, each can only retrieve records one time per second and each can retrieve less than 400 Kbps.
To minimize latency and maximize read throughput, you can create a data stream consumer with enhanced fan-out. An EFO consumer gets an isolated connection to the stream that provides a 2 MB/second outbound throughput. It doesn’t impact other applications reading from the stream. Stream consumers use HTTP/2 to push records to Lambda over a long-lived connection. Records can be delivered from producers to consumers in 70 milliseconds or better (a 65% improvement) in typical scenarios.
When to use shared throughput vs. dedicated throughput (EFO)
It’s advisable to use standard consumers when there are fewer (less than three) consuming applications and your use cases aren’t sensitive to latency. EFO is better for use cases that require low latency (70 milliseconds or better) for message delivery to consumer; this is achieved by automatic provisioning of an EFO pipe per consumer, which guarantees low latency irrespective of the number of consumers linked to the shard. EFO has cost dimensions associated with it; there is additional hourly charge per EFO consumer and charge for per GB of EFO data retrievals cost.
Monitoring ongoing stream processing
Kinesis Data Streams and Amazon CloudWatch are integrated so you can collect, view, and analyze CloudWatch metrics for your streaming application. It’s a best practice to make monitoring a priority to head off small problems before they become big ones. In this section, we discuss some key metrics to monitor.
Enhanced shard-level metrics
It’s a best practice to enable shard-level metrics with Kinesis Data Streams. As the name suggests, Kinesis Data Streams sends additional shard-level metrics to CloudWatch every minute. This can help you pinpoint failing consumers for a specific record or shards and identify hot shards. Enhanced shard-level metrics comes with additional cost. For information about pricing, see Amazon CloudWatch pricing.
IteratorAge
Make sure you keep a close eye on the IteratorAge (GetRecords.IteratorAgeMilliseconds) metric. Age is the difference between the current time and when the last record of the GetRecords call was written to the stream. If this value spikes, data processing from the stream is delayed. If the iterator age gets beyond your retention period, the expired records are permanently lost. Use CloudWatch alarms on the Maximum statistic to alert you before this loss is a risk.
The following screenshot shows a visualization of GetRecords.IteratorAgeMilliseconds.

In a single-source, multiple-consumer use case, each Lambda consumer reports its own IteratorAge metric. This helps identify the problematic consumer for further analysis.
You can find common causes and resolutions later in this post.
ReadProvisionedThroughputExceeded
The ReadProvisionedThroughputExceeded metric shows the count of GetRecords calls that have been throttled during a given time period. Use this metric to determine if your reads are being throttled due to exceeding your read throughput limits. If the Average statistic has a value other than 0, some of your consumers are throttled. You can add shards to the stream to increase throughput or use an EFO consumer to trigger your Lambda function.
Being aware of poison messages
A Lambda function is invoked for a batch of records from a shard and it checkpoints upon the success of each batch, so either a batch is processed successfully or entire batch is retried until processing is successful or records fall off the stream based on retention period. A poison message causes the failure of a batch process. It can create two possible scenarios: duplicates in the results, or delayed data processing and loss of data.
The following diagram illustrates when a poison message causes duplicates in the results. If there are 300 records in the data stream and batch size is 200, the Lambda instance is invoked to process the first 200 records. If processing fails at the eighty-third record, the entire batch is tried again, which can cause duplicates in the target for first 82 records depending on the target application.

The following diagram illustrates the problem of delayed data processing and data loss. If there are 300 records in the data stream and the batch size is 200, a Lambda instance is invoked to process the first 200 records until these records expire. This causes these records to be lost, and processing data in the queue is delayed significantly.

Addressing poison messages
There are two ways to handle failures gracefully. The first option is to implement logic in the Lambda function code to catch exceptions and log for offline analysis and return success to process the next batch. Exceptions can be logged to Amazon Simple Queue Service (Amazon SQS), CloudWatch Logs, Amazon S3, or other services.
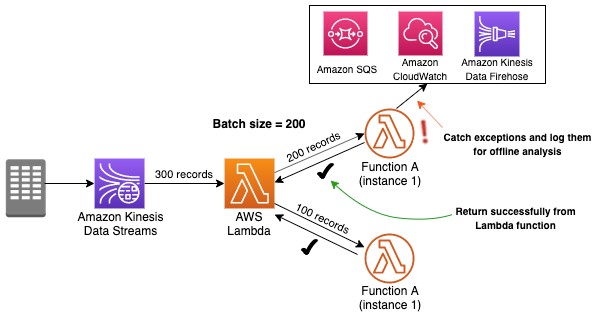
The second (and recommended) option is to configure the following retry and failure behaviors settings with Lambda as the consumer for Kinesis Data Streams:
- On-failure destination – Automatically send records to an SQS queue or Amazon Simple Notification Service (Amazon SNS) topic
- Retry attempts – Control the maximum retries per batch
- Maximum age of record – Control the maximum age of records to process
- Split batch on error – Split every retry batch size to a narrow batch size that is retried to automatically home in on poison messages
Optimizing for performance
In this section, we discuss common causes for Lambda not being able to keep up with Kinesis Data Streams and how to fix it.
Lambda is hitting concurrency limit
Lambda has reached the maximum number of parallel runs within the account, which means that Lambda can’t instantiate additional instances of the function. To identify this, set up CloudWatch alarms on the Throttles metrics exposed by the function. To resolve this issue, consider assigning reserved concurrency to a particular function.
Lambda is throttled on egress throughput of a data stream
This can happen if there are more consumers for a data stream and not enough read provisioned throughput available. To identify this, monitor the ReadProvisionedThroughputExceeded metric and set up a CloudWatch alarm. One or more of the following options can help resolve this issue:
- Add more shards and scale the data stream
- Reduce the batch window to process messages more frequently
- Use a consumer with enhanced fan-out
Business logic in Lambda is taking too long
To address this issue, consider increasing memory assigned to the function or add shards to the data stream to increase parallelism.
Another approach is to enable concurrent Lambda invocations by configuring Parallelization Factor, a feature that allows more than one simultaneous Lambda invocation per shard. Lambda can process up to 10 batches in each shard simultaneously. Each parallelized batch contains messages with the same partition key. This means the record processing order is still maintained at the partition-key level. The following diagram illustrates this architecture.

For more information, see New AWS Lambda scaling controls for Kinesis and DynamoDB event sources.
Optimizing for cost
Kinesis Data Stream has the following cost components:
- Shard hours
- PUT payload units (charged for 25 KB per PUT into a data stream)
- Extended data retention
- Enhanced fan-out
One of the key components you can optimize is PUT payload limits. As mentioned earlier, you’re charged for each event you put in a data stream in 25 KB increments, so if you’re sending small messages, it’s advisable to aggregate messages to optimize cost. One of the ways to aggregate multiple small records into a large record is to use Kinesis Producer Library (KPL) aggregation.
The following is an example of a use case with and without record aggregation:
- Without aggregation:
- 1,000 records per second, with record size of 512 bytes each
- Cost is $47.74 per month in
us-east-1Region (with $36.79 PUT payload units)
- With aggregation:
- 10 records per second, with records size of 50 kb each
- Cost is $11.69 per month in
us-east-1Region (with $0.74 PUT payload units)
Another component to optimize is to increase batch windows, which fine-tunes Lambda invocation for cost-optimization.
Conclusion
In this post, we covered the following aspects of Kinesis Data Streams processing with Lambda:
- Suitable use cases for Lambda stream processing
- Shared throughput consumers vs. dedicated-throughput consumers (enhanced fan-out)
- Monitoring
- Error handling
- Performance tuning
- Cost-optimization
To learn more about Amazon Kinesis, see Getting Started with Amazon Kinesis. If you have questions or suggestions, please leave a comment.
About the Authors
 Dylan Qu is an AWS solutions architect responsible for providing architectural guidance across the full AWS stack with a focus on Data Analytics, AI/ML and DevOps.
Dylan Qu is an AWS solutions architect responsible for providing architectural guidance across the full AWS stack with a focus on Data Analytics, AI/ML and DevOps.
 Vishwa Gupta is a Data and ML Engineer with AWS Professional Services Intelligence Practice. He helps customers implement big data and analytics solutions. Outside of work, he enjoys spending time with family, traveling, and playing badminton.
Vishwa Gupta is a Data and ML Engineer with AWS Professional Services Intelligence Practice. He helps customers implement big data and analytics solutions. Outside of work, he enjoys spending time with family, traveling, and playing badminton.