AWS Big Data Blog
Build a REST API to enable data consumption from Amazon Redshift
API (Application Programming Interface) is a design pattern used to expose a platform or application to another party. APIs enable programs and applications to communicate with platforms and services, and can be designed to use REST (REpresentational State Transfer) as a software architecture style.
APIs in OLTP (online transaction processing) are called frequently (tens to hundreds of times per second), delivering small payloads (output) in the order of a few bytes to kilobytes. However, OLAP (online analytical processing) has the ratio flipped. OLAP APIs have a low call volume but large payload (100 MB to several GBs). This pattern adds new challenges, like asynchronous processing, managing compute capacity, and scaling.
In this post, we walk through setting up an application API using the Amazon Redshift Data API, AWS Lambda, and Amazon API Gateway. The API performs asynchronous processing of user requests, sends user notifications, saves processed data in Amazon Simple Storage Service (Amazon S3), and returns a presigned URL for the user or application to download the dataset over HTTPS. We also provide an AWS CloudFormation template to help set up resources, available on the GitHub repo.
Solution overview
In our use case, Acme sells flowers on its site acmeflowers.com and collects reviews from customers. The website maintains a self-service inventory, allowing different producers to send flowers and other materials to acmeflowers.com when their supplies are running low.
Acme uses Amazon Redshift as their data warehouse. Near-real-time changes and updates to their inventory flow to Amazon Redshift, showing accurate availability of stock. The table PRODUCT_INVENTORY contains updated data. Acme wants to expose inventory information to partners in a cost-effective, secure way for inventory management process. If Acme’s partners are using Amazon Redshift, cross-account data sharing could be a potential option. If partners aren’t using Amazon Redshift, they could use the solution described in this post.
The following diagram illustrates our solution architecture:

The workflow contains the following steps:
- The client application sends a request to API Gateway and gets a request ID as a response.
- API Gateway calls the request receiver Lambda function.
- The request receiver function performs the following actions:
- Writes the status to an Amazon DynamoDB control table.
- Writes a request to Amazon Simple Queue Service (Amazon SQS).
- A second Lambda function, the request processor, performs following actions:
- Polls Amazon SQS.
- Writes the status back to the DynamoDB table.
- Runs a SQL query on Amazon Redshift.
- Amazon Redshift exports the data to an S3 bucket.
- A third Lambda function, the poller, checks the status of the results in the DynamoDB table.
- The poller function fetches results from Amazon S3.
- The poller function sends a presigned URL to download the file from the S3 bucket to the requestor via Amazon Simple Email Service (Amazon SES).
- The requestor downloads the file using the URL.
The workflow also contains the following steps to check the status of the request at various stages:
- The client application or user sends a request ID to API Gateway that is generated in Step 1.
- API Gateway calls the status check Lambda function.
- The function reads the status from the DynamoDB control table.
- The status is returned to the requestor through API Gateway.
Prerequisites
You need the following prerequisites to deploy the example application:
- An AWS account
- The AWS SAM CLI
- Python 3.9
- Node 17.3
- An AWS Identity and Access Management (IAM) role with appropriate access
- An Amazon Redshift cluster with a database and table
Complete the following prerequisite steps before deploying the sample application:
- Run the following DDL on the Amazon Redshift cluster using the query editor to create the schema and table:
- Configure AWS Secrets Manager to store the Amazon Redshift credentials.
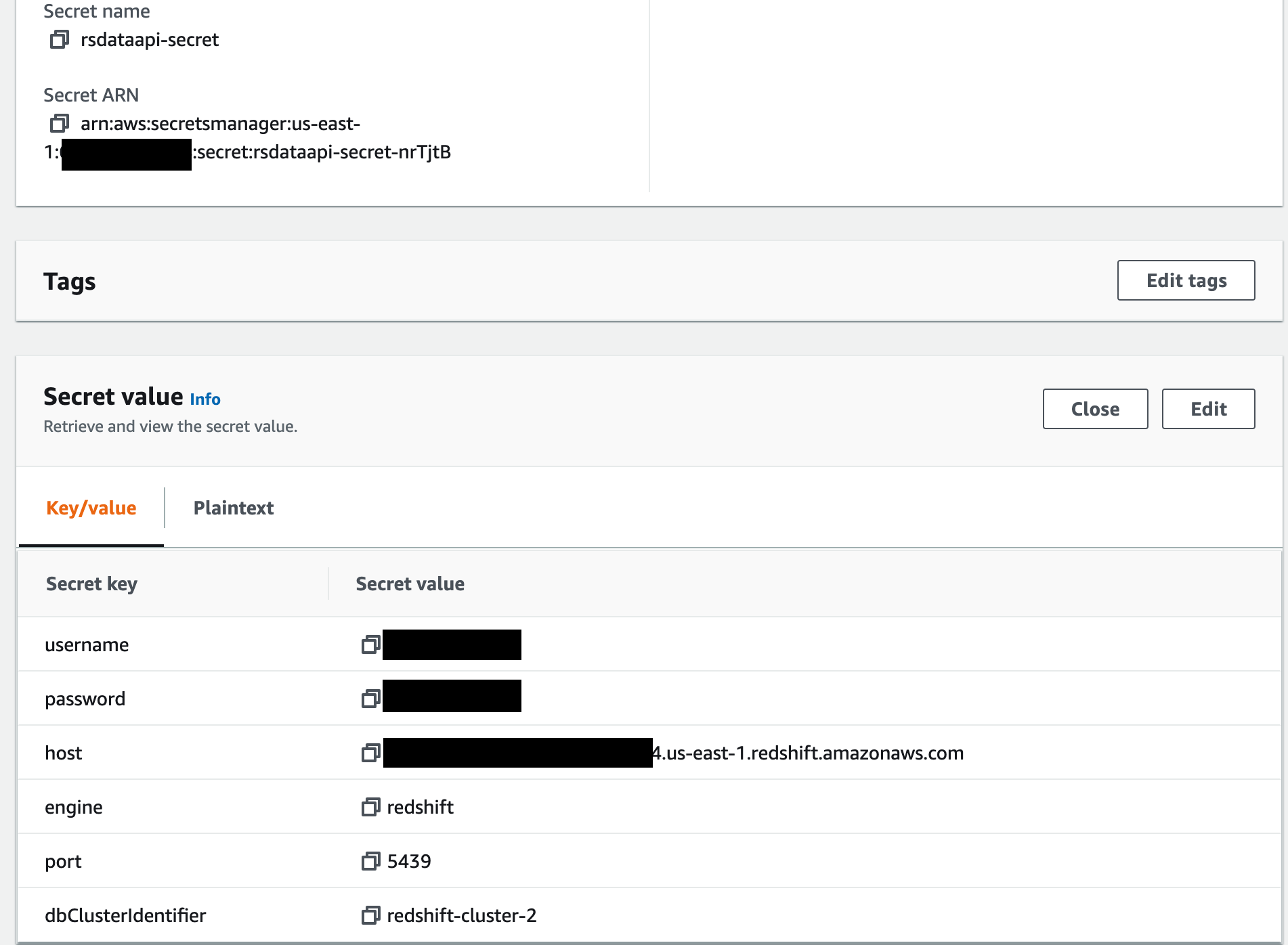
- Configure Amazon SES with an email address or distribution list to send and receive status updates.
Deploy the application
To deploy the application, complete the following steps:
- Clone the repository and download the sample source code to your environment where AWS SAM is installed:
- Change into the project directory containing the
template.yamlfile: - Change the API .yaml file to update your AWS account number and the Region where you’re deploying this solution:
- Build the application using AWS SAM:
- Deploy the application to your account using AWS SAM. Be sure to follow proper Amazon S3 naming conventions, providing globally unique names for S3 buckets:


SAM deploy requires you to provide the following parameters for configuration:
| Parameter | Description |
| RSClusterID | The cluster identifier for your existing Amazon Redshift cluster. |
| RSDataFetchQ | The query to fetch the data from your Amazon Redshift tables (for example, select * from rsdataapi.product_detail where sku= the input passed from the API) |
| RSDataFileS3BucketName | The S3 bucket where the dataset from Amazon S3 is uploaded. |
| RSDatabaseName | The database on your Amazon Redshift cluster. |
| RSS3CopyRoleArn | The IAM role for Amazon Redshift that has access to copy files to and from Amazon Redshift to Amazon S3. This role should be associated with your Amazon Redshift cluster. |
| RSSecret | The Secrets Manager ARN for your Amazon Redshift credentials. |
| RSUser | The user name to connect to the Amazon Redshift cluster. |
| RsFileArchiveBucket | The S3 bucket from where the zipped dataset is downloaded. This should be different than your upload bucket. |
| RsS3CodeRepo | The S3 bucket where the packages or .zip file is stored. |
| RsSingedURLExpTime | The expiry time in seconds for the presigned URL to download the dataset from Amazon S3. |
| RsSourceEmailAddress | The email address of the distribution list for which Amazon SES is configured to use as the source for sending completion status. |
| RsTargetEmailAddress | The email address of the distribution list for which Amazon SES is configured to use as the destination for receiving completion status. |
| RsStatusTableName | The name of the status table for capturing the status of various stages from start to completion of request. |
This template is designed only to show how you can set up an application API using the Amazon Redshift Data API, Lambda, and API Gateway. This setup isn’t intended for production use without modification.
Test the application
You can use Postman or any other application to connect to API Gateway and pass the request to access the dataset from Amazon Redshift. The APIs are authorized via IAM users. Before sending a request, choose your authorization type as AWS SigV4 and enter the values for AccessKey and SecretKey for the IAM user.
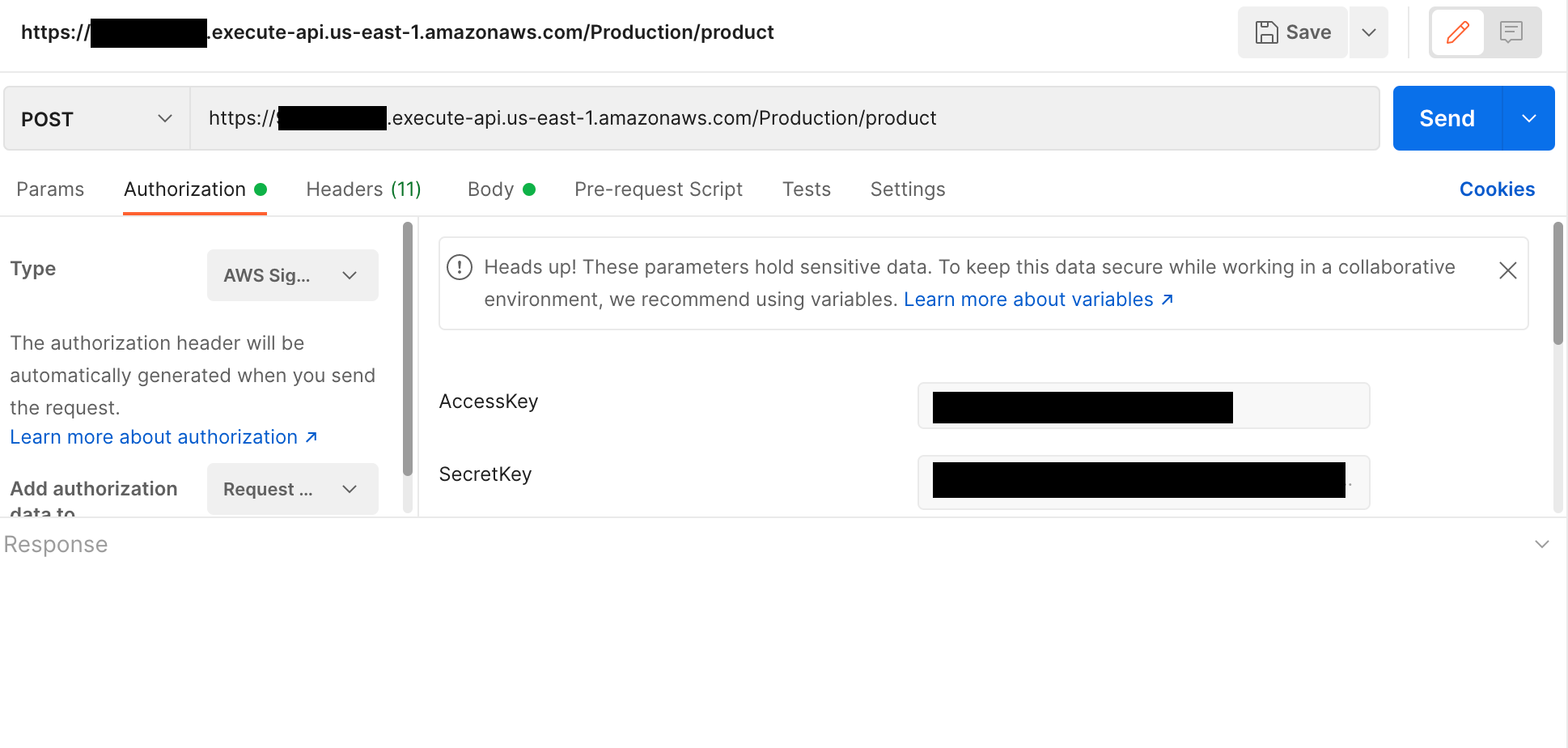
The following screenshot shows a sample request.

The following screenshot shows the email response.

The following screenshot shows sample response with the status of a request. You need to pass the request ID and enter all for status history or latest for latest status.


Clean up
When you’re finished testing this solution, remember to clean up all the AWS resources that you created using AWS SAM.
Delete the upload and download S3 buckets via the Amazon S3 console and then run the following on SAM CLI:
For more information, see sam delete.
Summary
In this post, we showed you how you can set up an application API that uses the Amazon Redshift Data API, Lambda, and API Gateway. The API performs asynchronous processing of user requests, sends user notifications, saves processed data in Amazon S3, and returns a presigned URL for the user or application to download the dataset over HTTPs.
Give this solution a try and share your experience with us!
About the Authors
 Jeetesh Srivastva is a Sr. Manager Specialist Solutions Architect at AWS. He specializes in Amazon Redshift and works with customers to implement scalable solutions using Amazon Redshift and other AWS Analytic services. He has worked to deliver on-premises and cloud-based analytic solutions for customers in banking and finance and hospitality industry verticals.
Jeetesh Srivastva is a Sr. Manager Specialist Solutions Architect at AWS. He specializes in Amazon Redshift and works with customers to implement scalable solutions using Amazon Redshift and other AWS Analytic services. He has worked to deliver on-premises and cloud-based analytic solutions for customers in banking and finance and hospitality industry verticals.
 Ripunjaya Pattnaik is an Enterprise Solutions Architect at AWS. He enjoys problem-solving with his customers and being their advisor. In his free time, he likes to try new sports, play ping pong, and watch movies.
Ripunjaya Pattnaik is an Enterprise Solutions Architect at AWS. He enjoys problem-solving with his customers and being their advisor. In his free time, he likes to try new sports, play ping pong, and watch movies.