AWS Big Data Blog
Create a serverless event-driven workflow to ingest and process Microsoft data with AWS Glue and Amazon EventBridge
Microsoft SharePoint is a document management system for storing files, organizing documents, and sharing and editing documents in collaboration with others. Your organization may want to ingest SharePoint data into your data lake, combine the SharePoint data with other data that’s available in the data lake, and use it for reporting and analytics purposes. AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, machine learning, and application development. AWS Glue provides all the capabilities needed for data integration so that you can start analyzing your data and putting it to use in minutes instead of months.
Organizations often manage their data on SharePoint in the form of files and lists, and you can use this data for easier discovery, better auditing, and compliance. SharePoint as a data source is not a typical relational database and the data is mostly semi structured, which is why it’s often difficult to join the SharePoint data with other relational data sources. This post shows how to ingest and process SharePoint lists and files with AWS Glue and Amazon EventBridge, which enables you to join other data that is available in your data lake. We use SharePoint REST APIs with a standard open data protocol (OData) syntax. OData advocates a standard way of implementing REST APIs that allows for SQL-like querying capabilities. OData helps you focus on your business logic while building RESTful APIs without having to worry about the various approaches to define request and response headers, query options, and so on.
AWS Glue event-driven workflows
Unlike a traditional relational database, SharePoint data may or may not change frequently, and it’s difficult to predict the frequency at which your SharePoint server generates new data, which makes it difficult to plan and schedule data processing pipelines efficiently. Running data processing frequently can be expensive, whereas scheduling pipelines to run infrequently can deliver cold data. Similarly, triggering pipelines from an external process can increase complexity, cost, and job startup time.
AWS Glue supports event-driven workflows, a capability that lets developers start AWS Glue workflows based on events delivered by EventBridge. The main reason to choose EventBridge in this architecture is because it allows you to process events, update the target tables, and make information available to consume in near-real time. Because frequency of data change in SharePoint is unpredictable, using EventBridge to capture events as they arrive enables you to run the data processing pipeline only when new data is available.
To get started, you simply create a new AWS Glue trigger of type EVENT and place it as the first trigger in your workflow. You can optionally specify a batching condition. Without event batching, the AWS Glue workflow is triggered every time an EventBridge rule matches, which may result in multiple concurrent workflows running. AWS Glue protects you by setting default limits that restrict the number of concurrent runs of a workflow. You can increase the required limits by opening a support case. Event batching allows you to configure the number of events to buffer or the maximum elapsed time before firing the particular trigger. When the batching condition is met, a workflow run is started. For example, you can trigger your workflow when 100 files are uploaded in Amazon Simple Storage Service (Amazon S3) or 5 minutes after the first upload. We recommend configuring event batching to avoid too many concurrent workflows, and optimize resource usage and cost.
To illustrate this solution better, consider the following use case for a wine manufacturing and distribution company that operates across multiple countries. They currently host all their transactional system’s data on a data lake in Amazon S3. They also use SharePoint lists to capture feedback and comments on wine quality and composition from their suppliers and other stakeholders. The supply chain team wants to join their transactional data with the wine quality comments in SharePoint data to improve their wine quality and manage their production issues better. They want to capture those comments from the SharePoint server within an hour and publish that data to a wine quality dashboard in Amazon QuickSight. With an event-driven approach to ingest and process their SharePoint data, the supply chain team can consume the data in less than an hour.
Overview of solution
In this post, we walk through a solution to set up an AWS Glue job to ingest SharePoint lists and files into an S3 bucket and an AWS Glue workflow that listens to S3 PutObject data events captured by AWS CloudTrail. This workflow is configured with an event-based trigger to run when an AWS Glue ingest job adds new files into the S3 bucket. The following diagram illustrates the architecture.
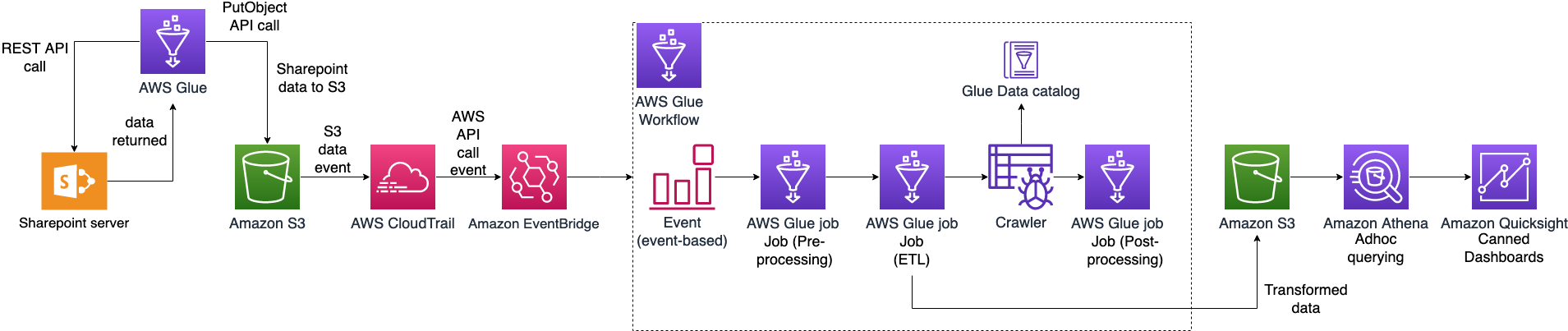
To make it simple to deploy, we captured the entire solution in an AWS CloudFormation template that enables you to automatically ingest SharePoint data into Amazon S3. SharePoint uses ClientID and TenantID credentials for authentication and uses Oauth2 for authorization.
The template helps you perform the following steps:
- Create an AWS Glue Python shell job to make the REST API call to the SharePoint server and ingest files or lists into Amazon S3.
- Create an AWS Glue workflow with a starting trigger of EVENT type.
- Configure CloudTrail to log data events, such as PutObject API calls to CloudTrail.
- Create a rule in EventBridge to forward the PutObject API events to AWS Glue when they’re emitted by CloudTrail.
- Add an AWS Glue event-driven workflow as a target to the EventBridge rule. The workflow gets triggered when the SharePoint ingest AWS Glue job adds new files to the S3 bucket.
Prerequisites
For this walkthrough, you should have the following prerequisites:
- An AWS account
- SharePoint server 2013 or later
Configure SharePoint server authentication details
Before launching the CloudFormation stack, you need to set up your SharePoint server authentication details, namely, TenantID, Tenant, ClientID, ClientSecret, and the SharePoint URL in AWS Systems Manager Parameter Store of the account you’re deploying in. This makes sure that no authentication details are stored in the code and they’re fetched in real time from Parameter Store when the solution is running.
To create your AWS Systems Manager parameters, complete the following steps:
- On the Systems Manager console, under Application Management in the navigation pane, choose Parameter Store.

- Choose Create Parameter.
- For Name, enter the parameter name
/DATALAKE/GlueIngest/SharePoint/tenant. - Leave the type as string.
- Enter your SharePoint tenant detail into the value field.
- Choose Create parameter.
- Repeat these steps to create the following parameters:
/DataLake/GlueIngest/SharePoint/tenant/DataLake/GlueIngest/SharePoint/tenant_id/DataLake/GlueIngest/SharePoint/client_id/list/DataLake/GlueIngest/SharePoint/client_secret/list/DataLake/GlueIngest/SharePoint/client_id/file/DataLake/GlueIngest/SharePoint/client_secret/file/DataLake/GlueIngest/SharePoint/url/list/DataLake/GlueIngest/SharePoint/url/file
Deploy the solution with AWS CloudFormation
For a quick start of this solution, you can deploy the provided CloudFormation stack. This creates all the required resources in your account.
The CloudFormation template generates the following resources:
- S3 bucket – Stores data, CloudTrail logs, job scripts, and any temporary files generated during the AWS Glue extract, transform, and load (ETL) job run.
- CloudTrail trail with S3 data events enabled – Enables EventBridge to receive
PutObjectAPI call data in a specific bucket. - AWS Glue Job – A Python shell job that fetches the data from the SharePoint server.
- AWS Glue workflow – A data processing pipeline that is comprised of a crawler, jobs, and triggers. This workflow converts uploaded data files into Apache Parquet format.
- AWS Glue database – The AWS Glue Data Catalog database that holds the tables created in this walkthrough.
- AWS Glue table – The Data Catalog table representing the Parquet files being converted by the workflow.
- AWS Lambda function – The AWS Lambda function is used as an AWS CloudFormation custom resource to copy job scripts from an AWS Glue-managed GitHub repository and an AWS Big Data blog S3 bucket to your S3 bucket.
- IAM roles and policies – We use the following AWS Identity and Access Management (IAM) roles:
- LambdaExecutionRole – Runs the Lambda function that has permission to upload the job scripts to the S3 bucket.
- GlueServiceRole – Runs the AWS Glue job that has permission to download the script, read data from the source, and write data to the destination after conversion.
- EventBridgeGlueExecutionRole – Has permissions to invoke the
NotifyEventAPI for an AWS Glue workflow. - IngestGlueRole – Runs the AWS Glue job that has permission to ingest data into the S3 bucket.
To launch the CloudFormation stack, complete the following steps:
- Sign in to the AWS CloudFormation console.
- Choose Launch Stack:

- Choose Next.
- For pS3BucketName, enter the unique name of your new S3 bucket.
- Leave pWorkflowName and pDatabaseName as the default.
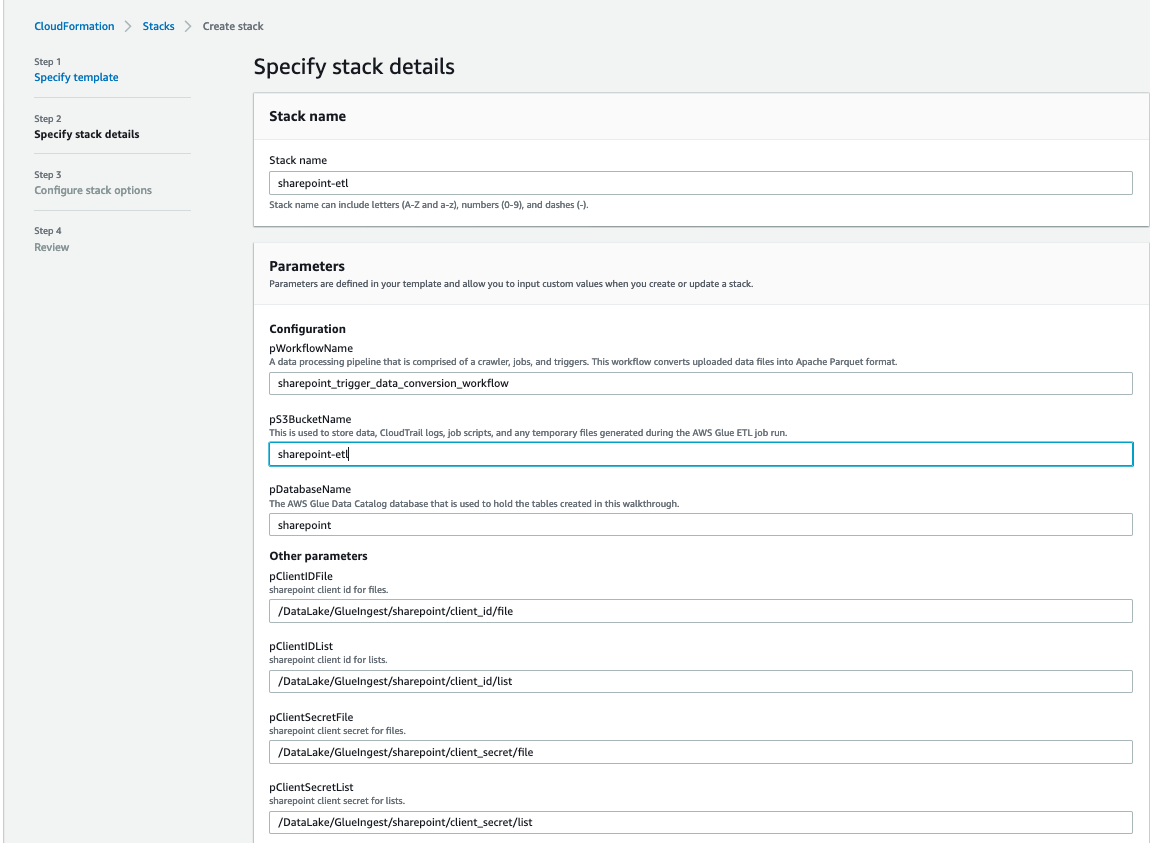
- For pDatasetName, enter the SharePoint list name or file name you want to ingest.
- Choose Next.
- On the next page, choose Next.
- Review the details on the final page and select I acknowledge that AWS CloudFormation might create IAM resources.
- Choose Create.
It takes a few minutes for the stack creation to complete; you can follow the progress on the Events tab.
You can run the ingest AWS Glue job either on a schedule or on demand. As the job successfully finishes and ingests data into the raw prefix of the S3 bucket, the AWS Glue workflow runs and transforms the ingested raw CSV files into Parquet files and loads them into the transformed prefix.
Review the EventBridge rule
The CloudFormation template created an EventBridge rule to forward S3 PutObject API events to AWS Glue. Let’s review the configuration of the EventBridge rule:
- On the EventBridge console, under Events, choose Rules.
- Choose the rule
s3_file_upload_trigger_rule-<CloudFormation-stack-name>. - Review the information in the Event pattern section.
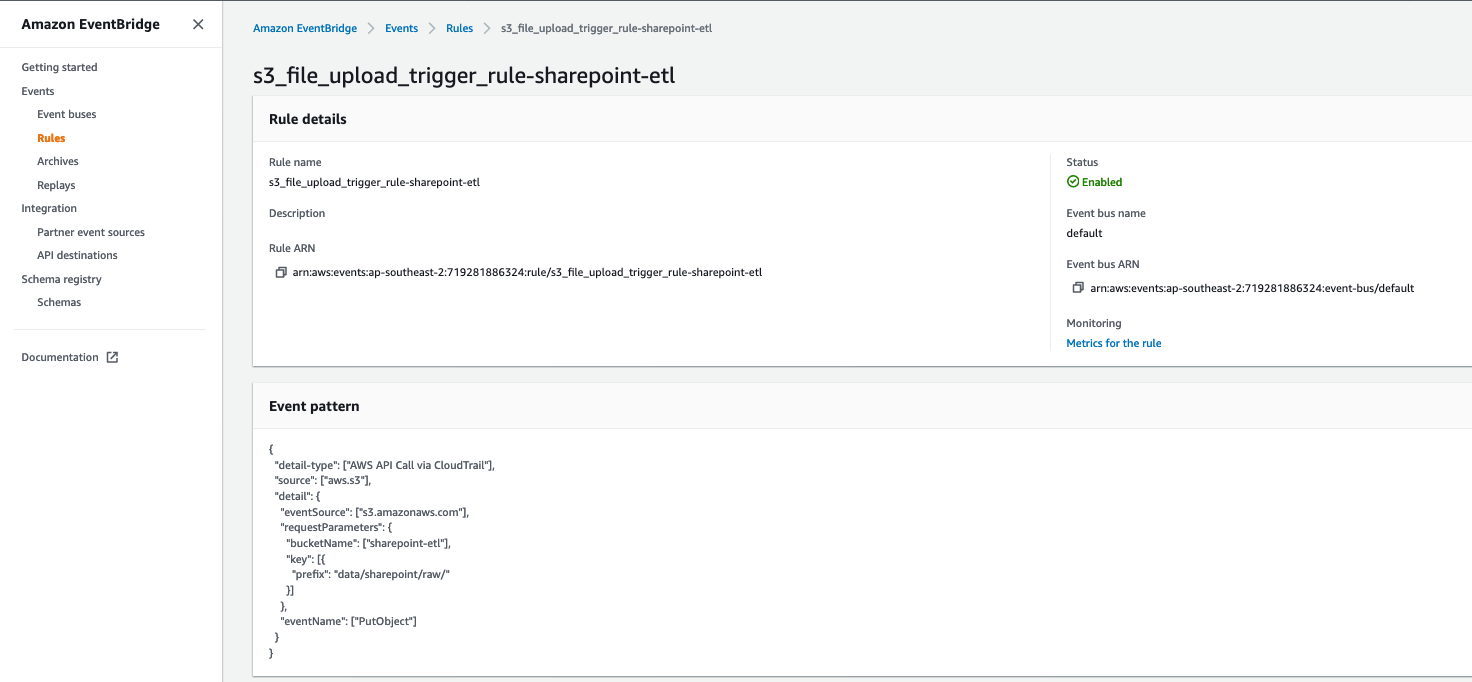
The event pattern shows that this rule is triggered when an S3 object is uploaded to s3://<bucket_name>/data/SharePoint/tablename_raw/. CloudTrail captures the PutObject API calls made and relays them as events to EventBridge.
- In the Targets section, you can verify that this EventBridge rule is configured with an AWS Glue workflow as a target.

Run the ingest AWS Glue job and verify the AWS Glue workflow is triggered successfully
To test the workflow, we run the ingest-glue-job-SharePoint-file job using the following steps:
- On the AWS Glue console, select the
ingest-glue-job-SharePoint-filejob.

- On the Action menu, choose Run job.
- Choose the History tab and wait until the job succeeds.
You can now see the CSV files in the raw prefix of your S3 bucket.
Now the workflow should be triggered.
- On the AWS Glue console, validate that your workflow is in the
RUNNINGstate.

- Choose the workflow to view the run details.
- On the History tab of the workflow, choose the current or most recent workflow run.
- Choose View run details.

When the workflow run status changes to Completed, let’s check the converted files in your S3 bucket.
- Switch to the Amazon S3 console, and navigate to your bucket.
You can see the Parquet files under s3://<bucket_name>/data/SharePoint/tablename_transformed/.
Congratulations! Your workflow ran successfully based on S3 events triggered by uploading files to your bucket. You can verify everything works as expected by running a query against the generated table using Amazon Athena.
Sample wine dataset
Let’s analyze a sample red wine dataset. The following screenshot shows a SharePoint list that contains various readings that relate to the characteristics of the wine and an associated wine category. This is populated by various wine tasters from multiple countries.
The following screenshot shows a supplier dataset from the data lake with wine categories ordered per supplier.
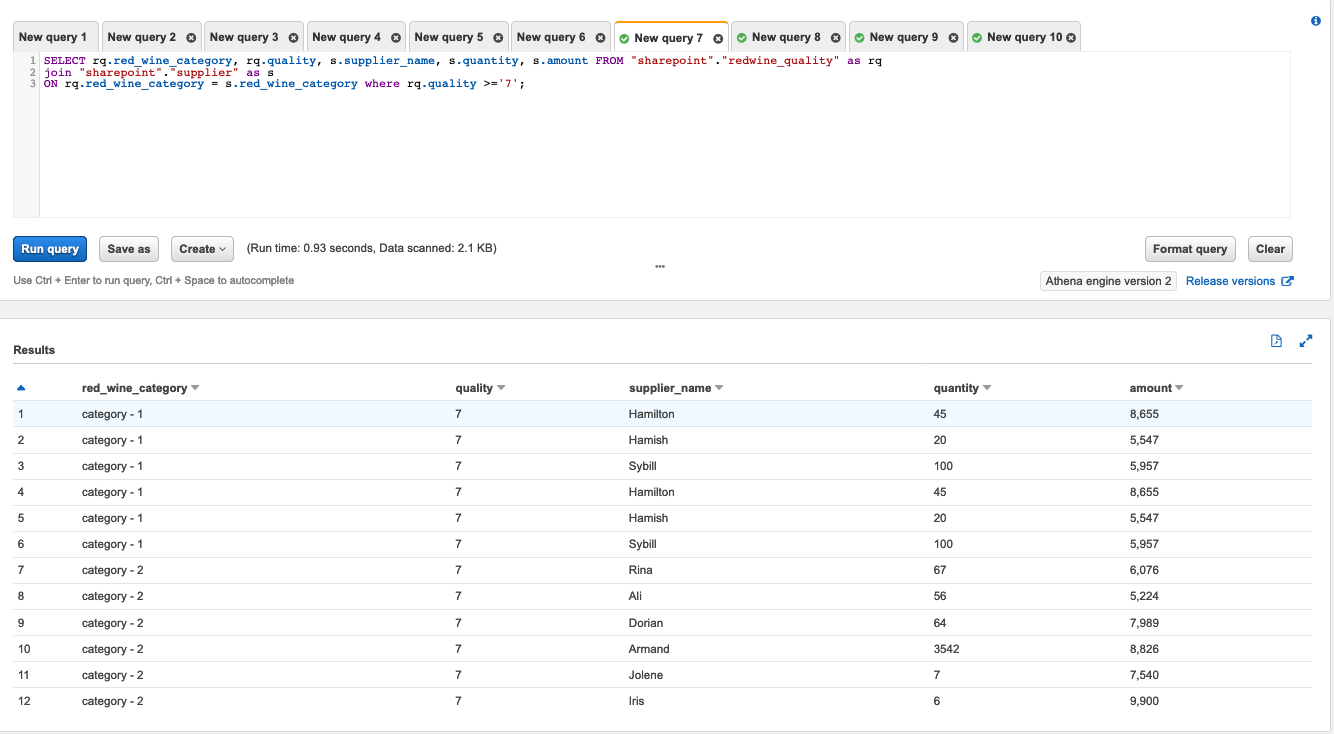
We process the red wine dataset using this solution and use Athena to query the red wine data and supplier data where wine quality is greater than or equal to 7.
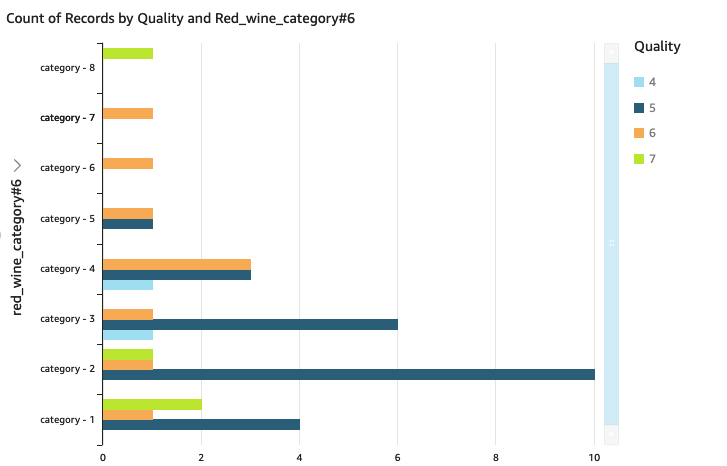
We can visualize the processed dataset using QuickSight.
Clean up
To avoid incurring unnecessary charges, you can use the AWS CloudFormation console to delete the stack that you deployed. This removes all the resources you created when deploying the solution.
Conclusion
Event-driven architectures provide access to near-real-time information and help you make business decisions on fresh data. In this post, we demonstrated how to ingest and process SharePoint data using AWS serverless services like AWS Glue and EventBridge. We saw how to configure a rule in EventBridge to forward events to AWS Glue. You can use this pattern for your analytical use cases, such as joining SharePoint data with other data in your lake to generate insights, or auditing SharePoint data and compliance requirements.
About the Author
 Venkata Sistla is a Big Data & Analytics Consultant on the AWS Professional Services team. He specializes in building data processing capabilities and helping customers remove constraints that prevent them from leveraging their data to develop business insights.
Venkata Sistla is a Big Data & Analytics Consultant on the AWS Professional Services team. He specializes in building data processing capabilities and helping customers remove constraints that prevent them from leveraging their data to develop business insights.