AWS Big Data Blog
How Wind Mobility built a serverless data architecture
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more.

Guest post by Pablo Giner, Head of BI, Wind Mobility.
Over the past few years, urban micro-mobility has become a trending topic. With the contamination indexes hitting historic highs, cities and companies worldwide have been introducing regulations and working on a wide spectrum of solutions to alleviate the situation.
We at Wind Mobility strive to make commuters’ life more sustainable and convenient by bringing short distance urban transportation to cities worldwide.
At Wind Mobility, we scale our services at the same pace as our users demand them, and we do it in an economically and environmentally viable way. We optimize our fleet distribution to avoid overcrowding cities with more scooters than those that are actually going to be used, and we position them just meters away from where our users need them and at the time of the day when they want them.
How do we do that? By optimizing our operations to their fullest. To do so, we need to be very well informed about our users’ behavior under varying conditions and understand our fleet’s potential.
Scalability and flexibility for rapid growth
We knew that before we could solve this challenge, we needed to collect data from many different sources, such as user interactions with our application, user demand, IoT signals from our scooters, and operational metrics. To analyze the numerous datasets collected and extract actionable insights, we needed to build a data lake. While the high-level goal was clear, the scope was less so. We were working hard to scale our operation as we continued to launch new markets. The rapid growth and expansion made it very difficult to predict the volume of data we would need to consume. We were also launching new microservices to support our growth, which resulted in more data sources to ingest. We needed an architecture that allowed us to be agile and quickly adopt to meet our growth. It became clear that a serverless architecture was best positioned to meet those needs, so we started to design our 100% serverless infrastructure.
The first challenge was ingesting and storing data from our scooters in the field, events from our mobile app, operational metrics, and partner APIs. We use AWS Lambda to capture changes in our operational databases and mobile app and push the events to Amazon Kinesis Data Streams, which allows us to take action in real time. We also use Amazon Kinesis Data Firehose to write the data to Amazon Simple Storage Service (Amazon S3), which we use for analytics.
After we were in Amazon S3 and adequately partitioned as per its most common use cases (we partition by date, region, and business line, depending on the data source), we had to find a way to query this data for both data profiling (understanding structure, content, and interrelationships) and ad hoc analysis. For that we chose AWS Glue crawlers to catalog our data and Amazon Athena to read from the AWS Glue Data Catalog and run queries. However, ad hoc analysis and data profiling are relatively sporadic tasks in our team, because most of the data processing computing hours are actually dedicated to transforming the multiple data sources into our data warehouse, consolidating the raw data, modeling it, adding new attributes, and picking the data elements, which constitute 95% of our analytics and predictive needs.
This is where all the heavy lifting takes place. We parse through millions of scooter and user events generated daily (over 300 events per second) to extract actionable insight. We selected AWS Glue to perform this task. Our primary ETL job reads the newly added raw event data from Amazon S3, processes it using Apache Spark, and writes the results to our Amazon Redshift data warehouse. AWS Glue plays a critical role in our ability to scale on demand. After careful evaluation and testing, we concluded that AWS Glue ETL jobs meet all our needs and free us from procuring and managing infrastructure.
Architecture overview
The following diagram represents our current data architecture, showing two serverless data collection, processing, and reporting pipelines:
- Operational databases from Amazon Relational Database Service (Amazon RDS) and MongoDB
- IoT and application events, followed by Athena for data profiling and Amazon Redshift for reporting

Our data is curated and transformed multiple times a day using an automated pipeline running on AWS Glue. The team can now focus on analyzing the data and building machine learning (ML) applications.
We chose Amazon QuickSight as our business intelligence tool to help us visualize and better understand our operational KPIs. Additionally, we use Amazon Elastic Container Registry (Amazon ECR) to store our Docker images containing our custom ML algorithms and Amazon Elastic Container Service (Amazon ECS) where we train, evaluate, and host our ML models. We schedule our models to be trained and evaluated multiple times a day. Taking as input curated data about demand, conversion, and flow of scooters, we run the models to help us optimize fleet utilization for a particular city at any given time.
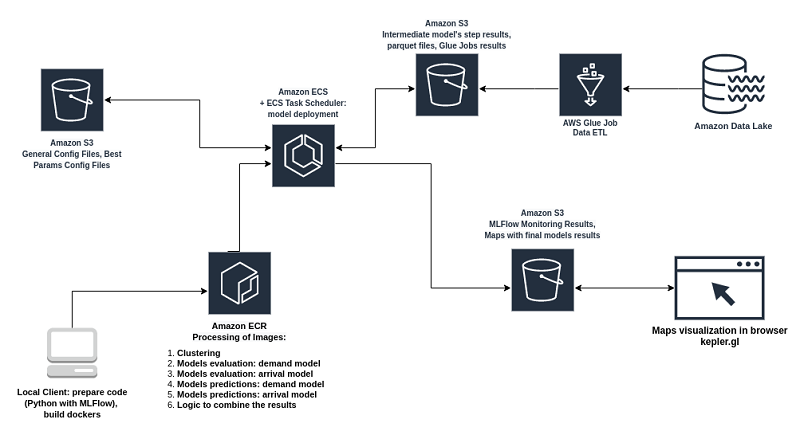
The following diagram represents how data from the data lake is incorporated into our ML training, testing, and serving system. First, our developers work in the application code and commit their changes, which are built into new Docker images by our CI/CD pipeline and stored in the Amazon ECR registry. These images are pushed into Amazon ECS and tested in DEV and UAT environments before moving to PROD (where they are triggered by the Amazon ECS task scheduler). During their execution, the Amazon ECS tasks (some train the demand and usage forecasting models, some produce the daily and hourly predictions, and others optimize the fleet distribution to satisfy the forecast) read their configuration and pull data from Amazon S3 (which has been previously produced by scheduled AWS Glue jobs), finally storing their results back into Amazon S3. Executions of these pipelines are tracked via MLFlow (in a dedicated Amazon Elastic Compute Cloud (Amazon EC2) server) and the final result indicating the fleet operations required is fit into a Kepler map, which is then consumed by the operators on the field.
Conclusion
We at Wind Mobility place data at the forefront of our operations. For that, we need our data infrastructure to be as flexible as the industry and the context we operate in, which is why we chose serverless. Over the course of a year, we have built a data lake, a data warehouse, a BI suite, and a variety of (production) data science applications. All of that with a very small team.
Also, within the last 12 months, we have scaled up several of our data pipelines by a factor of 10, without slowing our momentum or redesigning any part of our architecture. When it came to double our fleet in 1 week and increase the frequency at which we capture data from scooters by a factor of 10, our serverless data architecture scaled with no issues. This allowed us to focus on adding value by simplifying our operation, reacting to changes quickly, and delighting our users.
We have measured our success in multiple dimensions:
- Speed – Serverless is faster to deploy and expand; we believe we have reduced our time to market for the entire infrastructure by a factor of 2
- Visibility – We have 360 degree visibility of our operations worldwide, accessible by our city managers, finance team, and management board
- Optimized fleet deployment – We know, at any minute of the day, the number of scooters that our customers need over the next few hours, which reduces unsatisfied demand by more than 50%
If you face a similar challenge, our advice is clear: go fully serverless and use the spectrum of solutions available from AWS.
Follow us and discover more about Wind Mobility on Facebook, Instagram and LinkedIn.
About the Author
 Pablo Giner is Head of BI at Wind Mobility. Pablo’s background is in wheels (motorcycle racing > vehicle engineering > collision insurance > eScooters sharing…) and for the last few years he has specialized in forming and developing data teams. At Wind Mobility, he leads the data function (data engineering + analytics + data science), and the project he is most proud of is what they call smart fleet rebalancing, an AI backed solution to reposition their fleet in real-time. “In God we trust. All others must bring data.” – W. Edward Deming
Pablo Giner is Head of BI at Wind Mobility. Pablo’s background is in wheels (motorcycle racing > vehicle engineering > collision insurance > eScooters sharing…) and for the last few years he has specialized in forming and developing data teams. At Wind Mobility, he leads the data function (data engineering + analytics + data science), and the project he is most proud of is what they call smart fleet rebalancing, an AI backed solution to reposition their fleet in real-time. “In God we trust. All others must bring data.” – W. Edward Deming