AWS Big Data Blog
Query hierarchical data models within Amazon Redshift
In a hierarchical database model, information is stored in a tree-like structure or parent-child structure, where each record can have a single parent but many children. Hierarchical databases are useful when you need to represent data in a tree-like hierarchy. The perfect example of a hierarchical data model is the navigation file and folders or sitemap of a website. Another common example that’s widely used is a company organization chart or staffing information where employees are linked with each other via employee-manager relationship.
Some relational databases provide functionality to support hierarchical data model via common table expressions (CTEs). Recursive CTE syntax and semantics are defined as part of ANSI SQL to query a hierarchical data model in relational database management systems.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud data warehouse that supports the hierarchical database model through ANSI compliant recursive CTE, which allows you to query hierarchical data stored in parent-child relationships. Recursive CTE support is a newly introduced feature in Amazon Redshift from April 2021.
In this post, we present a simple hierarchical data model and write queries to show how easy it is to retrieve information from this model using recursive CTEs in Amazon Redshift.
Common use cases of hierarchical data models
The Amazon Redshift’s hierarchical data model is supported by recursive common table expressions. The hierarchical data model is built upon a parent-child relationship within the same table or view. The model represents a tree-like structure, where each record has a single parent. Although a parent can have one or more child records, each child can have only single parent. For example, most companies have a hierarchical structure when it comes to their org chart. Under an org chart, you have a CEO at the root of the tree and staffing structure underneath the root. You can traverse the hierarchy from bottom-up or top-down to discover all employees under a manager. Another example of a hierarchical data model is components and subcomponents of an engine. To query a hierarchical dataset, databases provide special query constructs, usually with recursive CTEs.
Common Table Expressions
Amazon Redshift provides the WITH statement, which allows us to construct auxiliary statements (CTEs) for use in a SQL query. CTEs are like temporary tables that exist only while running the query.
ANSII CTEs is a great technique to simplify complex queries by breaking the query into simple individual pieces. Using CTEs with a WITH clause results in a more readable and maintainable query versus using subqueries. The following is a simple query to illustrate how to write a CTE:
In the preceding query, the outer_products block is constructed using a WITH clause. You can use this block within subqueries, join conditions, or any other SQL constructs, just like any table. Without this block, complex queries involve code replication multiple times, which increases complexity and readability.
Recursive Common Table Expressions
A recursive common table expression is a CTE that references itself. The SQL WITH construct, using a CTE, is useful for other functions than just recursive queries, but recursive CTEs are very effective in querying a hierarchical data model. Without the support for recursive CTEs, it’s very hard to query hierarchical data in a relational database. For example, without recursive CTEs, procedural code is needed along with temporary tables to query hierarchical data represented in a relational model. The approach is not very elegant and is also error-prone. A recursive CTE is usually needed when querying hierarchical data such as organization charts where one employee reports to a manager, or a multi-level bill of materials when a product consists of many components, and each component also consists of many subcomponents.
The following is an example of a recursive CTE to generate a sequence of numbers. The recursive part nums is being used in the inner query that references the outer CTE, which is defined as RECURSIVE nums(n).
Org chart use case
Let’s look at an organization chart where employees are related to each other in a staffing data model.
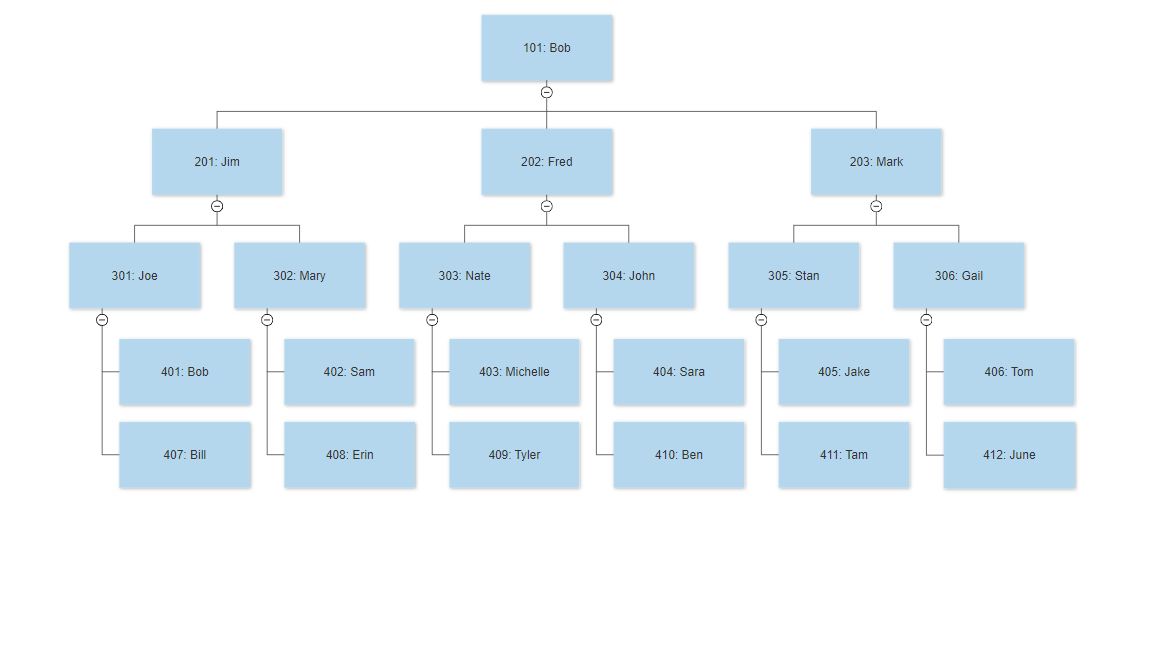
The following queries run on a table called employees, which contains the employee ID, employee name, and manager of the employee.
Let’s look at how to return the number of employees that directly or indirectly report to Bob.
Because this data is hierarchical in nature, we run a hierarchical query:
Let’s break down the preceding query and look at individual pieces that construct the components of a hierarchal query.
In general, a recursive CTE is a UNION ALL subquery with three parts within the WITH clause:
- Anchor member – The first part is a SELECT query that doesn’t have recursive reference to
cte_name. It returns the base result of the CTE, which is the initial set of the recursion. This initial query is often called the initial member, seed member, or anchor member. In the preceding query,bob_orgiscte_name, and the first SELECT query is the anchor member. - Recursive member – The second query after UNION ALL is a recursive query that references the CTE, called the recursive member. The recursive member is unioned with the anchor member (the initial seed) using the set operator UNION ALL. UNION ALL must be performed for the recursive CTEs. In the preceding example, the second query is the recursive query, and it references the CTE
bob_org. - Termination condition – This condition must be specified in the recursive member (the second query after UNION ALL). The termination condition is usually provided via a WHERE clause or JOIN operation. In the preceding example, the termination condition is provided via a WHERE clause using
e.manager = b.id.
Let’s use the same org chart to get all the subordinates of the manager with ID 302:
The first SELECT query (the anchor member) returns the base result, which is the employee with ID 302:
Next, the recursive member returns all the members underneath the tree rooted at employee ID 302 as well as the root, which is ID 302:
When we start at the seed level, recursive queries can traverse a hierarchical tree in an elegant manner. This is not easily possible without hierarchical support, which is achieved by recursive CTEs.
Display “hierarchical path” via recursive CTE
Displaying hierarchy levels and a hierarchical path along with the data is also often desired in these types of use cases. You can easily achieve this by using a recursive CTE with the following approach.
Let’s modify the preceding query to display the hierarchical path and levels:
In the preceding query, it’s very important to use CAST with the appropriate data type to define the maximum width of the result column. The main reason for using CAST is to define the column length for the resultant column. The result column data type and its length is determined by the initialization branch, namely the anchor member or first SELECT. In this example, if the employee_id column is of varchar(400) type but its actual content is much smaller, for example, 20 bytes, CAST isn’t needed when there are 10 hierarchical levels. This is because the recursive CTE’s result column path would be varchar(400), which is wide enough to hold the result data. However, if the employee_id data type is varchar(30) and the actual data length is 20 bytes, the result column path of the recursive CTE is longer than 30 bytes only after two levels of hierarchy. To accommodate 10 levels of hierarchy, CAST(employee_id as varchar(400)) is needed here. This defines the data type and size of the result column. In this case, the result column path maximum data size is 400 bytes, which is long enough to accommodate the result data. Therefore, we highly recommend using explicit CAST to define the data type and size of the result column in a recursive CTE.
The result of the preceding query is as follows:
Because both employees 402 and 408 are one level below Mary (302), their level is 1 plus Mary’s level. Also, it should be noted that the path column now indicates the hierarchical path rooted at the seed level, which was 302 in our scenario.
With these recursive CTE queries, it’s extremely easy to query hierarchical data within Amazon Redshift. No more complicated stored procedures or temporary tables are needed to query hierarchical data in Redshift.
Recursive CTE troubleshooting: Top-down vs. bottom up
You can use both top-down and bottom-up approaches via recursive CTE to traverse the hierarchical structure. In the preceding example, we presented a top-down approach. To traverse bottom-up, you should specify the starting point in the first part of the query. Then the second query needs to join the recursive component using the parent ID.
In both top-down and bottom-up strategies, you must clearly specify the termination condition. You might run into cyclic conditions, which could cause buffer overflow if termination conditions aren’t specified correctly. This could cause an infinite loop, causing Recursive CTE out of working buffers errors in Amazon Redshift. Therefore, you must add a condition to stop the recursion, which prevents infinite loops.
Summary
This post discussed the usage and benefits of the new capability in Amazon Redshift that provides support for querying hierarchical data models via recursive CTEs. This functionality can also provide tremendous benefits when combined with the SUPER data type, which provides support for querying semi-structured data like JSON. Try it out and share your experience.
About the Author
 Nadim Rana is a Data Warehouse and MPP Architect at Amazon Web Services. He is a big data enthusiast and collaborates with customers around the globe to achieve success and meet their data warehousing and data lake architecture needs.
Nadim Rana is a Data Warehouse and MPP Architect at Amazon Web Services. He is a big data enthusiast and collaborates with customers around the globe to achieve success and meet their data warehousing and data lake architecture needs.