AWS Big Data Blog
Scale your Amazon Redshift clusters up and down in minutes to get the performance you need, when you need it
Amazon Redshift is the cloud data warehouse of choice for organizations of all sizes—from fast-growing technology companies such as Turo and Yelp to Fortune 500 companies such as 21st Century Fox and Johnson & Johnson. With quickly expanding use cases, data sizes, and analyst populations, these customers have a critical need for scalable data warehouses.
Since we launched Amazon Redshift, our customers have grown with us. Working closely with them, we have learned how their needs evolve as their data scales. We commonly encounter scenarios like the following for data analytics:
- A US-based retail company runs a large number of scheduled queries and complex BI reports. Their Amazon Redshift usage peaks between 8 AM and 6 PM, when their data scientists and analysts run heavy workloads. At night, they might have an occasional user who queries the data and generates a small report. Consequently, they don’t need the same cluster capacity at night as they do during the day.
- A healthcare consulting company is rapidly growing their Data as a Service (DaaS) business. They want to quickly create a duplicate environment and provide the cluster endpoint to their clients. After the duplicate cluster is created, it needs to be right-sized quickly based on the cost and performance requirements of the client.
- An IoT service provider is on a rapid growth trajectory. Whenever a major event takes place, their sensors send in terabytes of new data that needs to be ingested into Amazon Redshift and analyzed soon after it arrives.
When database administrators (DBAs) don’t have the nimbleness to react to these scenarios, the analysts can experience longer response times for mission-critical workloads. Or, they might be locked out altogether if the data warehouse is down for a resize. The DBAs, in turn, cannot support Service Level Agreements (SLAs) that they have set with their business stakeholders.
With Amazon Redshift, you can already scale quickly in three ways. First, you can query data in your Amazon S3 data lakes in place using Amazon Redshift Spectrum, without needing to load it into the cluster. This flexibility lets you analyze growing data volumes without waiting for extract, transform, and load (ETL) jobs or adding more storage capacity. Second, you can resize your Amazon Redshift clusters by adding more nodes or changing node types in just a few hours. During this time, analysts can continue to run read queries with no downtime. This gives you more agility compared to on-premises data warehouses that take days to scale. Third, you can spin up multiple Amazon Redshift clusters by quickly restoring data from a snapshot. This allows you to add compute resources that might be needed to support high concurrency.
Introducing elastic resize
We’re excited to introduce elastic resize, a new feature that enables you to add or remove nodes in an Amazon Redshift cluster in minutes. This further increases your agility to get better performance and more storage for demanding workloads, and to reduce cost during periods of low demand. You can resize manually from the AWS Management Console or programmatically with a simple API call.
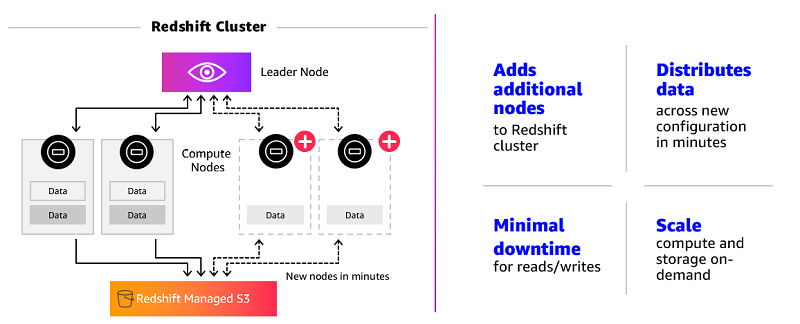
With elastic resize, you can start small and scale up on-demand as your needs grow, as illustrated in the following diagram.
Amazon Redshift customers who have been previewing elastic resize before launch have immediately benefited by the scalability that it unlocks for them. Here is what some of our customers had to say about elastic resize:
|
|
Amazon Prime Video uses advanced data analytics to customize viewing recommendations and measure fan viewing experiences. “Redshift’s new elastic resize feature reduced our operational resizing time from 6 hours down to 15 minutes, allowing us to dynamically scale our infrastructure according to the diverse nature of our workloads and optimizing costs while maximizing performance.” Sergio Diaz Bautista, Data Engineer at Amazon Prime Video |
|
|
Yelp uses Amazon Redshift to analyze mobile app usage data and ad data on customer cohorts, auctions, and ad metrics. “Yelp is at the forefront of using data analytics to drive business decisions and enhance its users’ experience. Using elastic resize, we can confidently optimize for the best performance and keep costs low by configuring the cluster to scale up whenever demand increases beyond the usual variability window and scale down during off-peak hours. The ability to scale our data warehouse containing hundreds of terabytes of data, in minutes, is amazing,” says Shahid Chohan, data architect at Yelp.com |
|
|
“Coupang is disrupting how the world shops on phones. We cannot always predict analytical demand because of evolving business needs and ad hoc analyses that are unexpectedly required. With elastic resize, we can scale compute and storage quickly to finish large ETL jobs faster and serve more users querying the data,” says Hara Ketha, senior manager of data engineering at Coupang. |
|
|
OLX uses Amazon Redshift to power personalization and relevance, run reporting, and generate actionable customer insights. “With OLX, millions of people across the world buy and sell from each other daily. Redshift has been at the core of advanced analytics and big data innovation at OLX. For our ever increasing data needs, we can now add nodes using elastic resize blazingly fast. It’s also easy to size down during periods of low activity in order to save costs. Thank you Redshift!” said Michał Adamkiewicz, data architect for the Europe data team at OLX.com |




How elastic resize works
Elastic resize is fundamentally different from the existing classic resize operation available in Amazon Redshift. Unlike classic resize, which creates a new cluster and transfers data to it, elastic resize modifies the number of nodes in your existing cluster. It enables you to deploy the additional nodes in minutes with minimal disruption to ongoing read or write queries. Hence, you can size up your cluster quickly for faster performance and size down when the job is finished to save cost.
You can still use classic resize when you want to change the node type (for instance, if you are upgrading from DC1 to DC2 nodes). The following stages describe what happens behind the scenes when you trigger elastic resize.
Stage 1: Preparing for resize while the cluster is fully available
At the start of elastic resize, Amazon Redshift first updates the snapshot on Amazon S3 with the most recent data. Today, Amazon Redshift takes an automated snapshot every 8 hours or 5 GB of data change, whichever comes first. In addition, you can also take snapshots manually. Each snapshot is incremental to capture changes that occurred since the last automated or manual snapshot. While the first snapshot is taken, the cluster is fully available for read and write queries.
On the console and via the describe-clusters API operation, the cluster status shows as available, prep-for-resize during this stage. Additionally, an event notification (REDSHIFT-EVENT-3012) lets you know that a request for elastic resize has been received.

Stage 2: Resizing the cluster while the cluster is unavailable
This stage, when the resizing actually happens, takes just a few minutes to finish. As the resize begins, the existing connections are put on hold. No new connections are accepted until the resize finishes, and the cluster is unavailable for querying. Some of the held connections or queries might fail if they were part of ongoing transactions. New nodes are added (for scaling up) or removed (for scaling down) during this period. Another incremental backup is taken to account for any data updates made by users during stage 1.
On the console and using the describe-clusters API operation, the cluster status now shows as resizing. Additionally, an event notification (REDSHIFT-EVENT-3011) lets you know that elastic resize started on the cluster.

Stage 3: Data transferring while the cluster is fully available
After resizing is finished in stage 2, the cluster is fully available for read and write queries. Queries that were being held are queued for execution automatically. During this stage, data is transferred from Amazon S3 to the nodes. Because Amazon Redshift only subtracts or adds nodes, only a fraction of the data needs to be transferred. For example, if you resized a three-node dc2.8xlarge cluster to six nodes, only 50 percent of the data needs to be moved.
We also improved the rate at which we restore data blocks from S3 by 2x, cutting down the time it would have taken to finish stage 3. In addition, this improvement also makes restores from a snapshot faster.
Moreover, Amazon Redshift moves the data intelligently to minimize the impact of data transfer on queries during this stage. The most frequently accessed data blocks are moved first, followed by other blocks based on their access frequency. This results in most incoming queries finding the data blocks that they are trying to access on disk.
On the console and using the describe-clusters API operation, the cluster status now shows as available, transferring data. Additionally, an event notification (REDSHIFT-EVENT-3534) lets you know that elastic resize has finished and the cluster is available for reads and writes.

After the data transfer is finished, the cluster status on the console and via the describe-clusters API operation once again shows as available.
Elastic resize constraints
Before deciding whether elastic resize is appropriate for your use case, consider the following constraints:
- The new node configuration must have enough storage for existing data. Even when you add nodes, your new configuration might not have enough storage because of the way that data is redistributed.
- You can resize only by a factor of 2, up or down, for dc2.large or ds2.xlarge node types. For example, you can resize a four-node cluster up to eight nodes or down to two nodes. This limitation exists to avoid data skew between nodes caused by an uneven distribution of slices.
- For dc2.8xlarge or ds2.8xlarge node types, you can resize up to two times the original node count, or down to one-half the original node count. For example, you can resize a 16-node cluster to any size up to 32 nodes, or any size down to 8 nodes. This limitation exists to avoid data skew between nodes caused by an uneven distribution of slices.
Conclusion
Elastic resize significantly improves your ability to scale your Amazon Redshift clusters on-demand. Together with features such as Amazon Redshift Spectrum, it enables you to independently scale storage and compute so that you can adapt to the evolving analytical needs of your business.
To learn more about elastic resize and understand how you can size your clusters, watch the AWS Online Tech Talk: Best Practices for Scaling Amazon Redshift. You can also refer to the documentation for Resizing Clusters in the Amazon Redshift Cluster Management Guide.
About the Authors
 Ayush Jain is a Product Marketer at Amazon Web Services. He loves growing cloud services and helping customers get more value from the cloud deployments. He has several years of experience in Software Development, Product Management and Product Marketing in developer and data services.
Ayush Jain is a Product Marketer at Amazon Web Services. He loves growing cloud services and helping customers get more value from the cloud deployments. He has several years of experience in Software Development, Product Management and Product Marketing in developer and data services.
 Himanshu Raja is a Senior Product Manager for Amazon Redshift. Himanshu loves solving hard problems with data and cherishes moments when data goes against intuition. In his spare time, Himanshu enjoys cooking Indian food and watching action movies.
Himanshu Raja is a Senior Product Manager for Amazon Redshift. Himanshu loves solving hard problems with data and cherishes moments when data goes against intuition. In his spare time, Himanshu enjoys cooking Indian food and watching action movies.