AWS Big Data Blog
The best new features for data analysts in Amazon Redshift in 2020
This is a guest post by Helen Anderson, data analyst and AWS Data Hero
Every year, the Amazon Redshift team launches new and exciting features, and 2020 was no exception. New features to improve the data warehouse service and add interoperability with other AWS services were rolling out all year.
I am part of a team that for the past 3 years has used Amazon Redshift to store source tables from systems around the organization and usage data from our software as a service (SaaS) product. Amazon Redshift is our one source of truth. We use it to prepare operational reports that support the business and for ad hoc queries when numbers are needed quickly.
When AWS re:Invent comes around, I look forward to the new features, enhancements, and functionality that make things easier for analysts. If you haven’t tried Amazon Redshift in a while, or even if you’re a longtime user, these new capabilities are designed with analysts in mind to make it easier to analyze data at scale.
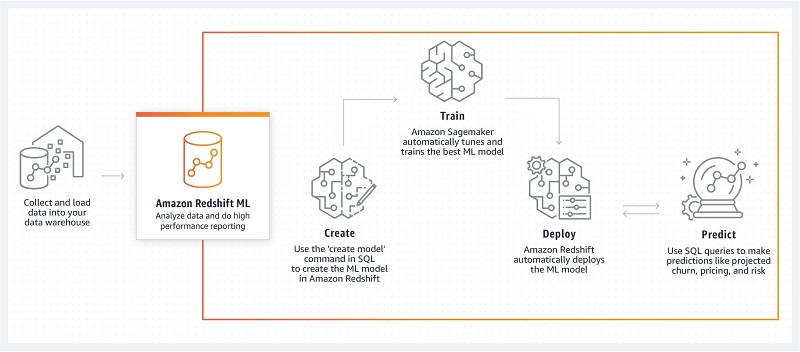
Amazon Redshift ML
The newly launched preview of Amazon Redshift ML lets data analysts use Amazon SageMaker over datasets in Amazon Redshift to solve business problems without the need for a data scientist to create custom models.
As a data analyst myself, this is one of the most interesting announcements to come out in re:Invent 2020. Analysts generally use SQL to query data and present insights, but they don’t often do data science too. Now there is no need to wait for a data scientist or learn a new language to create predictive models.
For information about what you need to get started with Amazon Redshift ML, see Create, train, and deploy machine learning models in Amazon Redshift using SQL with Amazon Redshift ML.
Federated queries
As analysts, we often have to join datasets that aren’t in the same format and sometimes aren’t ready for use in the same place. By using federated queries to access data in other databases or Amazon Simple Storage Service (Amazon S3), you don’t need to wait for a data engineer or ETL process to move data around.
re:Invent 2019 featured some interesting talks from Amazon Redshift customers who were tackling this problem. Now that federated queries over operational databases like Amazon RDS for PostgreSQL and Amazon Aurora PostgreSQL are generally available and querying Amazon RDS for MySQL and Amazon Aurora MySQL is in preview, I’m excited to hear more.
For a step-by-step example to help you get started, see Build a Simplified ETL and Live Data Query Solution Using Redshift Federated Query.
SUPER data type
Another problem we face as analysts is that the data we need isn’t always in rows and columns. The new SUPER data type makes JSON data easy to use natively in Amazon Redshift with PartiQL.
PartiQL is an extension that helps analysts get up and running quickly with structured and semistructured data so you can unnest and query using JOINs and aggregates. This is really exciting for those who deal with data coming from applications that store data in JSON or unstructured formats.
For use cases and a quickstart, see Ingesting and querying semistructured data in Amazon Redshift (preview).
Partner console integration
The preview of the native console integration with partners announced at AWS re:Invent 2020 will also make data analysis quicker and easier. Although analysts might not be doing the ETL work themselves, this new release makes it easier to move data from platforms like Salesforce, Google Analytics, and Facebook Ads into Amazon Redshift.
Matillion, Sisense, Segment, Etleap, and Fivetran are launch partners, with other partners coming soon. If you’re an Amazon Redshift partner and would like to integrate into the console, contact redshift-partners@amazon.com.
RA3 nodes with managed storage
Previously, when you added Amazon Redshift nodes to a cluster, both storage and compute were scaled up. This all changed with the 2019 announcement of RA3 nodes, which upgrade storage and compute independently.
In 2020, the Amazon Redshift team introduced RA3.xlplus nodes, which offer even more compute sizing options to address a broader set of workload requirements.
AQUA for Amazon Redshift
As analysts, we want our queries to run quickly so we can spend more time empowering the users of our insights and less time watching data slowly return. AQUA, the Advanced Query Accelerator for Amazon Redshift tackles this problem at an infrastructure level by bringing the stored data closer to the compute power
This hardware-accelerated cache enables Amazon Redshift to run up to 10 times faster as it scales out and processes data in parallel across many nodes. Each node accelerates compression, encryption, and data processing tasks like scans, aggregates, and filtering. Analysts should still try their best to write efficient code, but the power of AQUA will speed up the return of results considerably.
AQUA is available on Amazon Redshift RA3 instances at no additional cost. To get started with AQUA, sign up for the preview.
The following diagram shows Amazon Redshift architecture with an AQUA layer.

Figure 1: Amazon Redshift architecture with AQUA layer
Automated performance tuning
For analysts who haven’t used sort and distribution keys, the learning curve can be steep. A table created with the wrong keys can mean results take much longer to return.
Automatic table optimization tackles this problem by using machine learning to select the best keys and tune the physical design of tables. Letting Amazon Redshift determine how to improve cluster performance reduces manual effort.
Summary
These are just some of the Amazon Redshift announcements made in 2020 to help analysts get query results faster. Some of these features help you get access to the data you need, whether it’s in Amazon Redshift or somewhere else. Others are under-the-hood enhancements that make things run smoothly with less manual effort.
For more information about these announcements and a complete list of new features, see What’s New in Amazon Redshift.
About the Author
Helen Anderson is a Data Analyst based in Wellington, New Zealand. She is well known in the data community for writing beginner-friendly blog posts, teaching, and mentoring those who are new to tech. As a woman in tech and a career switcher, Helen is particularly interested in inspiring those who are underrepresented in the industry.