AWS Big Data Blog
Top 8 Best Practices for High-Performance ETL Processing Using Amazon Redshift
New: Read Amazon Redshift continues its price-performance leadership to learn what analytic workload trends we’re seeing from Amazon Redshift customers, new capabilities we have launched to improve Redshift’s price-performance, and the results from the latest benchmarks.
An ETL (Extract, Transform, Load) process enables you to load data from source systems into your data warehouse. This is typically executed as a batch or near-real-time ingest process to keep the data warehouse current and provide up-to-date analytical data to end users.
Amazon Redshift is a fast, petabyte-scale data warehouse that enables you easily to make data-driven decisions. With Amazon Redshift, you can get insights into your big data in a cost-effective fashion using standard SQL. You can set up any type of data model, from star and snowflake schemas, to simple de-normalized tables for running any analytical queries.
To operate a robust ETL platform and deliver data to Amazon Redshift in a timely manner, design your ETL processes to take account of Amazon Redshift’s architecture. When migrating from a legacy data warehouse to Amazon Redshift, it is tempting to adopt a lift-and-shift approach, but this can result in performance and scale issues long term. This post guides you through the following best practices for ensuring optimal, consistent runtimes for your ETL processes:
- COPY data from multiple, evenly sized files.
- Use workload management to improve ETL runtimes.
- Perform table maintenance regularly.
- Perform multiple steps in a single transaction.
- Loading data in bulk.
- Use UNLOAD to extract large result sets.
- Use Amazon Redshift Spectrum for ad hoc ETL processing.
- Monitor daily ETL health using diagnostic queries.
1. COPY data from multiple, evenly sized files
Amazon Redshift is an MPP (massively parallel processing) database, where all the compute nodes divide and parallelize the work of ingesting data. Each node is further subdivided into slices, with each slice having one or more dedicated cores, equally dividing the processing capacity. The number of slices per node depends on the node type of the cluster. For example, each DS2.XLARGE compute node has two slices, whereas each DS2.8XLARGE compute node has 16 slices.
When you load data into Amazon Redshift, you should aim to have each slice do an equal amount of work. When you load the data from a single large file or from files split into uneven sizes, some slices do more work than others. As a result, the process runs only as fast as the slowest, or most heavily loaded, slice. In the example shown below, a single large file is loaded into a two-node cluster, resulting in only one of the nodes, “Compute-0”, performing all the data ingestion:

When splitting your data files, ensure that they are of approximately equal size – between 1 MB and 1 GB after compression. The number of files should be a multiple of the number of slices in your cluster. Also, I strongly recommend that you individually compress the load files using gzip, lzop, or bzip2 to efficiently load large datasets.
When loading multiple files into a single table, use a single COPY command for the table, rather than multiple COPY commands. Amazon Redshift automatically parallelizes the data ingestion. Using a single COPY command to bulk load data into a table ensures optimal use of cluster resources, and quickest possible throughput.
2. Use workload management to improve ETL runtimes
Use Amazon Redshift’s workload management (WLM) to define multiple queues dedicated to different workloads (for example, ETL versus reporting) and to manage the runtimes of queries. As you migrate more workloads into Amazon Redshift, your ETL runtimes can become inconsistent if WLM is not appropriately set up.
I recommend limiting the overall concurrency of WLM across all queues to around 15 or less. This WLM guide helps you organize and monitor the different queues for your Amazon Redshift cluster.
When managing different workloads on your Amazon Redshift cluster, consider the following for the queue setup:
- Create a queue dedicated to your ETL processes. Configure this queue with a small number of slots (5 or fewer). Amazon Redshift is designed for analytics queries, rather than transaction processing. The cost of COMMIT is relatively high, and excessive use of COMMIT can result in queries waiting for access to the commit queue. Because ETL is a commit-intensive process, having a separate queue with a small number of slots helps mitigate this issue.
- Claim extra memory available in a queue. When executing an ETL query, you can take advantage of the wlm_query_slot_count to claim the extra memory available in a particular queue. For example, a typical ETL process might involve COPYing raw data into a staging table so that downstream ETL jobs can run transformations that calculate daily, weekly, and monthly aggregates. To speed up the COPY process (so that the downstream tasks can start in parallel sooner), the wlm_query_slot_count can be increased for this step.
- Create a separate queue for reporting queries. Configure query monitoring rules on this queue to further manage long-running and expensive queries.
- Take advantage of the dynamic memory parameters. They swap the memory from your ETL to your reporting queue after the ETL job has completed.
3. Perform table maintenance regularly
Amazon Redshift is a columnar database, which enables fast transformations for aggregating data. Performing regular table maintenance ensures that transformation ETLs are predictable and performant. To get the best performance from your Amazon Redshift database, you must ensure that database tables regularly are VACUUMed and ANALYZEd. The Analyze & Vacuum schema utility helps you automate the table maintenance task and have VACUUM & ANALYZE executed in a regular fashion.
- Use VACUUM to sort tables and remove deleted blocks
During a typical ETL refresh process, tables receive new incoming records using COPY, and unneeded data (cold data) is removed using DELETE. New rows are added to the unsorted region in a table. Deleted rows are simply marked for deletion.
DELETE does not automatically reclaim the space occupied by the deleted rows. Adding and removing large numbers of rows can therefore cause the unsorted region and the number of deleted blocks to grow. This can degrade the performance of queries executed against these tables.
After an ETL process completes, perform VACUUM to ensure that user queries execute in a consistent manner. The complete list of tables that need VACUUMing can be found using the Amazon Redshift Util’s table_info script.
Use the following approaches to ensure that VACCUM is completed in a timely manner:
- Use wlm_query_slot_count to claim all the memory allocated in the ETL WLM queue during the VACUUM process.
- DROP or TRUNCATE intermediate or staging tables, thereby eliminating the need to VACUUM them.
- If your table has a compound sort key with only one sort column, try to load your data in sort key order. This helps reduce or eliminate the need to VACUUM the table.
- Consider using time series This helps reduce the amount of data you need to VACUUM.
- Use ANALYZE to update database statistics
Amazon Redshift uses a cost-based query planner and optimizer using statistics about tables to make good decisions about the query plan for the SQL statements. Regular statistics collection after the ETL completion ensures that user queries run fast, and that daily ETL processes are performant. The Amazon Redshift utility table_info script provides insights into the freshness of the statistics. Keeping the statistics off (pct_stats_off) less than 20% ensures effective query plans for the SQL queries.
4. Perform multiple steps in a single transaction
ETL transformation logic often spans multiple steps. Because commits in Amazon Redshift are expensive, if each ETL step performs a commit, multiple concurrent ETL processes can take a long time to execute.
To minimize the number of commits in a process, the steps in an ETL script should be surrounded by a BEGIN…END statement so that a single commit is performed only after all the transformation logic has been executed. For example, here is an example multi-step ETL script that performs one commit at the end:
5. Loading data in bulk
Amazon Redshift is designed to store and query petabyte-scale datasets. Using Amazon S3 you can stage and accumulate data from multiple source systems before executing a bulk COPY operation. The following methods allow efficient and fast transfer of these bulk datasets into Amazon Redshift:
- Use a manifest file to ingest large datasets that span multiple files. The manifest file is a JSON file that lists all the files to be loaded into Amazon Redshift. Using a manifest file ensures that Amazon Redshift has a consistent view of the data to be loaded from S3, while also ensuring that duplicate files do not result in the same data being loaded more than one time.
- Use temporary staging tables to hold the data for transformation. These tables are automatically dropped after the ETL session is complete. Temporary tables can be created using the CREATE TEMPORARY TABLE syntax, or by issuing a SELECT … INTO #TEMP_TABLE query. Explicitly specifying the CREATE TEMPORARY TABLE statement allows you to control the DISTRIBUTION KEY, SORT KEY, and compression settings to further improve performance.
- User ALTER table APPEND to swap data from the staging tables to the target table. Data in the source table is moved to matching columns in the target table. Column order doesn’t matter. After data is successfully appended to the target table, the source table is empty. ALTER TABLE APPEND is much faster than a similar CREATE TABLE AS or INSERT INTO operation because it doesn’t involve copying or moving data.
6. Use UNLOAD to extract large result sets
Fetching a large number of rows using SELECT is expensive and takes a long time. When a large amount of data is fetched from the Amazon Redshift cluster, the leader node has to hold the data temporarily until the fetches are complete. Further, data is streamed out sequentially, which results in longer elapsed time. As a result, the leader node can become hot, which not only affects the SELECT that is being executed, but also throttles resources for creating execution plans and managing the overall cluster resources. Here is an example of a large SELECT statement. Notice that the leader node is doing most of the work to stream out the rows:
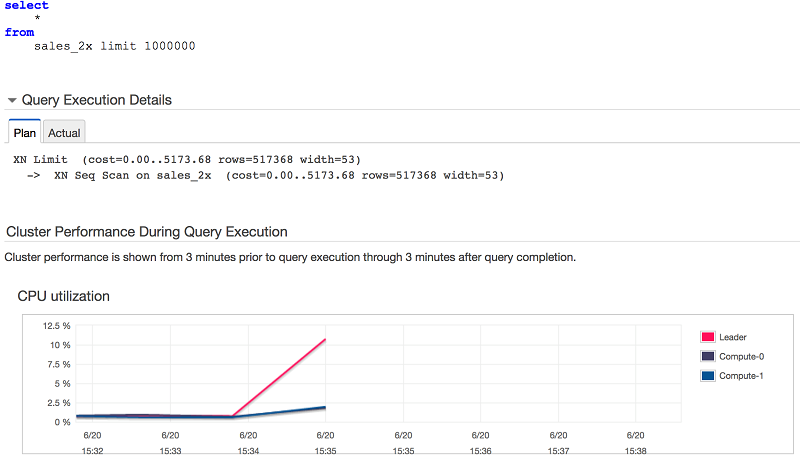
Use UNLOAD to extract large results sets directly to S3. After it’s in S3, the data can be shared with multiple downstream systems. By default, UNLOAD writes data in parallel to multiple files according to the number of slices in the cluster. All the compute nodes participate to quickly offload the data into S3.
If you are extracting data for use with Amazon Redshift Spectrum, you should make use of the MAXFILESIZE parameter, so that you don’t have very large files (files greater than 512 MB in size). Similar to item 1 above, having many evenly sized files ensures that Redshift Spectrum can do the maximum amount of work in parallel.
7. Use Redshift Spectrum for ad hoc ETL processing
Events such as data backfill, promotional activity, and special calendar days can trigger additional data volumes that affect the data refresh times in your Amazon Redshift cluster. To help address these spikes in data volumes and throughput, I recommend staging data in S3. After data is organized in S3, Redshift Spectrum enables you to query it directly using standard SQL. In this way, you gain the benefits of additional capacity without having to resize your cluster.
For tips on getting started with and optimizing the use of Redshift Spectrum, see the previous post, 10 Best Practices for Amazon Redshift Spectrum.
8. Monitor daily ETL health using diagnostic queries
Monitoring the health of your ETL processes on a regular basis helps identify the early onset of performance issues before they have a significant impact on your cluster. The following monitoring scripts can be used to provide insights into the health of your ETL processes:
| Script | Use when… | Solution |
| commit_stats.sql – Commit queue statistics from past days, showing largest queue length and queue time first | DML statements such as INSERT/UPDATE/COPY/DELETE operations take several times longer to execute when multiple of these operations are in progress | Set up separate WLM queues for the ETL process and limit the concurrency to < 5. |
| copy_performance.sql – Copy command statistics for the past days | Daily COPY operations take longer to execute | • Follow the best practices for the COPY command. • Analyze data growth with the incoming datasets and consider cluster resize to meet the expected SLA. |
| table_info.sql – Table skew and unsorted statistics along with storage and key information | Transformation steps take longer to execute | • Set up regular VACCUM jobs to address unsorted rows and claim the deleted blocks so that transformation SQL execute optimally. • Consider a table redesign to avoid data skewness. |
| v_check_transaction_locks.sql – Monitor transaction locks | INSERT/UPDATE/COPY/DELETE operations on particular tables do not respond back in timely manner, compared to when run after the ETL | Multiple DML statements are operating on the same target table at the same moment from different transactions. Set up ETL job dependency so that they execute serially for the same target table. |
| v_get_schema_priv_by_user.sql – Get the schema that the user has access to | Reporting users can view intermediate tables | Set up separate database groups for reporting and ETL users, and grants access to objects using GRANT. |
| v_generate_tbl_ddl.sql – Get the table DDL | You need to create an empty table with same structure as target table for data backfill | Generate DDL using this script for data backfill. |
| v_space_used_per_tbl.sql – monitor space used by individual tables | Amazon Redshift data warehouse space growth is trending upwards more than normal | Analyze the individual tables that are growing at higher rate than normal. Consider data archival using UNLOAD to S3 and Redshift Spectrum for later analysis. Use unscanned_table_summary.sql to find unused table and archive or drop them. |
| top_queries.sql – Return the top 50 time consuming statements aggregated by its text | ETL transformations are taking longer to execute | Analyze the top transformation SQL and use EXPLAIN to find opportunities for tuning the query plan. |
There are several other useful scripts available in the amazon-redshift-utils repository. The AWS Lambda Utility Runner runs a subset of these scripts on a scheduled basis, allowing you to automate much of monitoring of your ETL processes.
Example ETL process
The following ETL process reinforces some of the best practices discussed in this post. Consider the following four-step daily ETL workflow where data from an RDBMS source system is staged in S3 and then loaded into Amazon Redshift. Amazon Redshift is used to calculate daily, weekly, and monthly aggregations, which are then unloaded to S3, where they can be further processed and made available for end-user reporting using a number of different tools, including Redshift Spectrum and Amazon Athena.

Step 1: Extract from the RDBMS source to a S3 bucket
In this ETL process, the data extract job fetches change data every 1 hour and it is staged into multiple hourly files. For example, the staged S3 folder looks like the following:
Organizing the data into multiple, evenly sized files enables the COPY command to ingest this data using all available resources in the Amazon Redshift cluster. Further, the files are compressed (gzipped) to further reduce COPY times.
Step 2: Stage data to the Amazon Redshift table for cleansing
Ingesting the data can be accomplished using a JSON-based manifest file. Using the manifest file ensures that S3 eventual consistency issues can be eliminated and also provides an opportunity to dedupe any files if needed. A sample manifest20170702.json file looks like the following:
The data can be ingested using the following command:
Because the downstream ETL processes depend on this COPY command to complete, the wlm_query_slot_count is used to claim all the memory available to the queue. This helps the COPY command complete as quickly as possible.
Step 3: Transform data to create daily, weekly, and monthly datasets and load into target tables
Data is staged in the “stage_tbl” from where it can be transformed into the daily, weekly, and monthly aggregates and loaded into target tables. The following job illustrates a typical weekly process:
As shown above, multiple steps are combined into one transaction to perform a single commit, reducing contention on the commit queue.
Step 4: Unload the daily dataset to populate the S3 data lake bucket
The transformed results are now UNLOADed into another S3 bucket, where they can be further processed and made available for end-user reporting using a number of different tools, including Redshift Spectrum and Amazon Athena.
Summary
Amazon Redshift lets you easily operate petabyte-scale data warehouses on the cloud. This post summarized the best practices for operating scalable ETL natively within Amazon Redshift. I demonstrated efficient ways to ingest and transform data, along with close monitoring. I also demonstrated the best practices being used in a typical sample ETL workload to transform the data into Amazon Redshift.
If you have questions or suggestions, please comment below.
![]()
Additional Reading
If you found this post useful, be sure to check out Top 10 Performance Tuning Techniques for Amazon Redshift and 10 Best Practices for Amazon Redshift Spectrum
About the Author
 Thiyagarajan Arumugam is a Big Data Solutions Architect at Amazon Web Services and designs customer architectures to process data at scale. Prior to AWS, he built data warehouse solutions at Amazon.com. In his free time, he enjoys all outdoor sports and practices the Indian classical drum mridangam.
Thiyagarajan Arumugam is a Big Data Solutions Architect at Amazon Web Services and designs customer architectures to process data at scale. Prior to AWS, he built data warehouse solutions at Amazon.com. In his free time, he enjoys all outdoor sports and practices the Indian classical drum mridangam.