AWS Compute Blog
Category: Best Practices

Implementing up-to-date images with automated EC2 Image Builder pipelines
This blog post is written by Devin Gordon, Senior Solutions Architect, WWPS, and Brad Watson, Senior Solutions Architect, WWPS. Amazon EC2 Image Builder is a service designed to simplify the creation and deployment of customized Virtual Machine (VM) and container images on AWS or on-premises. The posts Automate OS Image Build Pipelines with EC2 Image […]
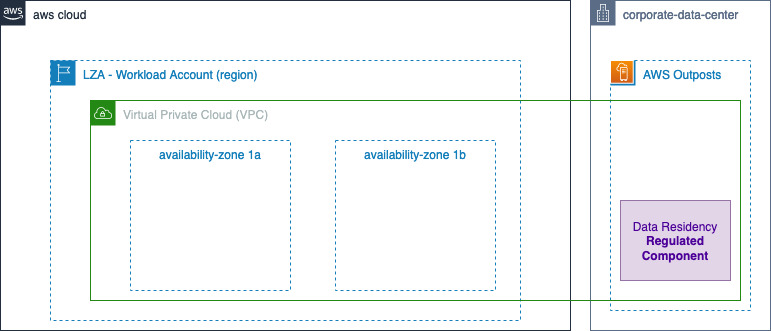
Architecting for data residency with AWS Outposts rack and landing zone guardrails
This blog post was written by Abeer Naffa’, Sr. Solutions Architect, Solutions Builder AWS, David Filiatrault, Principal Security Consultant, AWS and Jared Thompson, Hybrid Edge SA Specialist, AWS. In this post, we will explore how organizations can use AWS Control Tower landing zone and AWS Organizations custom guardrails to enable compliance with data residency requirements […]

How to create custom health checks for your Amazon EC2 Auto Scaling Fleet
This blog post is written by Gaurav Verma, Cloud Infrastructure Architect, Professional Services AWS. Amazon EC2 Auto Scaling helps you maintain application availability and lets you automatically add or remove Amazon Elastic Compute Cloud (Amazon EC2) instances according to the conditions that you define. You can use dynamic and predictive scaling to scale-out and scale-in […]
Scaling an ASG using target tracking with a dynamic SQS target
This blog post is written by Wassim Benhallam, Sr Cloud Application Architect AWS WWCO ProServe, and Rajesh Kesaraju, Sr. Specialist Solution Architect, EC2 Flexible Compute. Scaling an Amazon EC2 Auto Scaling group based on Amazon Simple Queue Service (Amazon SQS) is a commonly used design pattern in decoupled applications. For example, an EC2 Auto Scaling […]
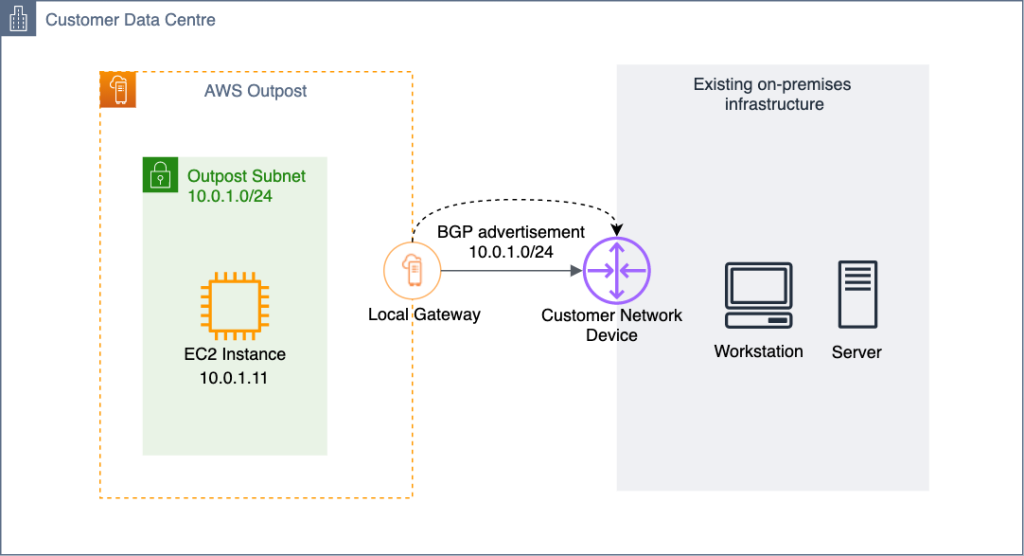
How to choose between CoIP and Direct VPC routing modes on AWS Outposts rack
This blog post is written by Sumit Menaria, Senior Hybrid Solutions Architect AWS WWSO Core Services. AWS Outposts Rack is a fully-managed service that extends AWS infrastructure, services, APIs, and tools to customer premises. By providing local access to AWS managed infrastructure and services, Outposts rack enables customers to build and run applications on premises […]

Adopt Recommendations and Monitor Predictive Scaling for Optimal Compute Capacity
This post is written by Ankur Sethi, Sr. Product Manager, EC2, and Kinnar Sen, Sr. Specialist Solution Architect, AWS Compute. Amazon EC2 Auto Scaling helps customers optimize their Amazon EC2 capacity by dynamically responding to varying demand. Based on customer feedback, we enhanced the scaling experience with the launch of predictive scaling policies. Predictive scaling […]
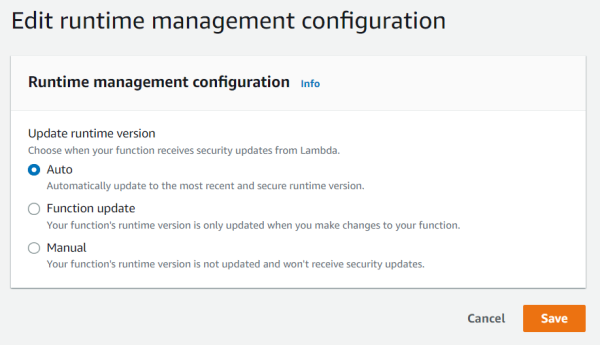
Introducing AWS Lambda runtime management controls
This blog post is written by Jonathan Tuliani, Principal Product Manager. Today, AWS Lambda is announcing runtime management controls which provide more visibility and control over when Lambda applies runtime updates to your functions. Lambda is also changing how it rolls out automatic runtime updates to your functions. Together, these changes provide more flexibility in […]

Building Sustainable, Efficient, and Cost-Optimized Applications on AWS
This blog post is written by Isha Dua Sr. Solutions Architect AWS, Ananth Kommuri Solutions Architect AWS, Dr. Sam Mokhtari Sr. Sustainability Lead SA WA for AWS, and Adam Boeglin, Principal Specialist EC2 Sustainability. Today, more than ever, sustainability and cost-savings are top of mind for nearly every organization. Research has shown that AWS’ infrastructure […]
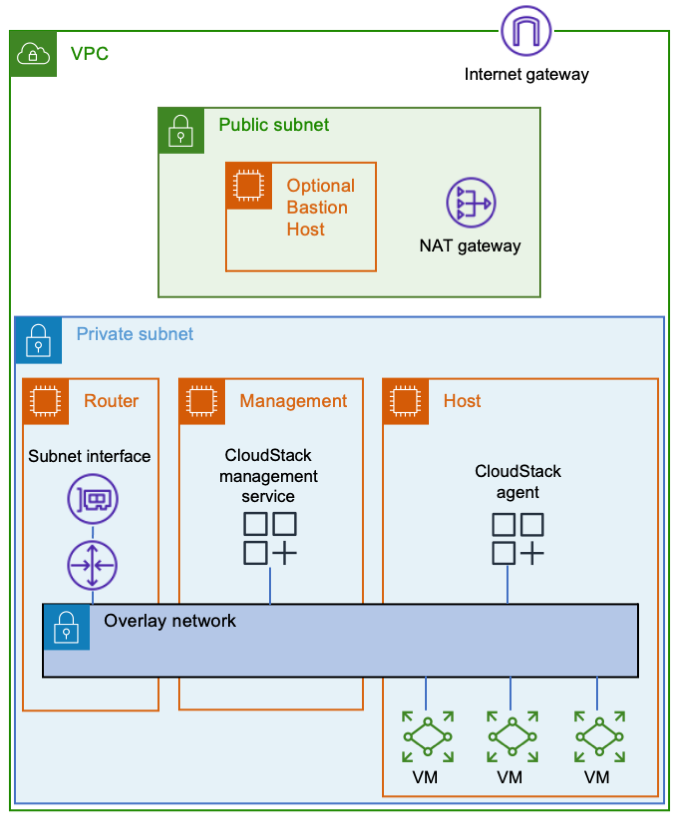
Building a Cloud in the Cloud: Running Apache CloudStack on Amazon EC2, Part 2
This blog is written by Mark Rogers, SDE II – Customer Engineering AWS. In part 1, I showed you how to run Apache CloudStack with KVM on a single Amazon Elastic Compute Cloud (Amazon EC2) instance. That simple setup is great for experimentation and light workloads. In this post, things will get a lot more […]

Building a Cloud in the Cloud: Running Apache CloudStack on Amazon EC2, Part 1
This blog is written by Mark Rogers, SDE II – Customer Engineering AWS. How do you put a cloud inside another cloud? Some features that make Amazon Elastic Compute Cloud (Amazon EC2) secure and wonderful also make running CloudStack difficult. The biggest obstacle is that AWS and CloudStack both want to manage network resources. Therefore, we must […]