AWS for Industries
How to improve FRTB’s Internal Model Approach implementation using Apache Spark and Amazon EMR
The Fundamental Review of the Trading Book (FRTB) is a set of proposals by the Basel Committee on Banking Supervision for market risk capital calculation for banks. This new set of rules (often referred to as “Basel IV”) is intended to create a more resilient market and capture risk adequately for stressed market conditions. It was initially published in January 2016 and revised in January 2019. The current go live date for FRTB is Jan 1, 2023.
FRTB proposes two types of approaches to calculate capital for a bank’s trading book: the Standardized Approach (SA) and the Internal Model Approach (IMA). Consensus across the industry is that IMA has a smaller impact on capital reserves but is more difficult to implement compared to SA. In this post, we deep-dive Amazon EMR for Apache Spark as a scaled, flexible, and cost-effective option to run FRTB IMA.
Why look to the cloud for IMA?
In order to comply with IMA requirements, a bank’s End of Day (EOD) market risk systems need to match its front office reports with 95% or greater accuracy. In order to achieve >95% accuracy, these platforms must construct curves across more instruments. Risk systems will need to model additional market shocks and map all risk factors across trading systems. All these processes require much greater EOD calculation capacity. Finally, since IMA must happen for each desk, there will be significant increase in the amount of data being produced, analyzed, and reported.
Specifically, IMA centralized calculation requires much larger compute capacity (often 3 to 5 times or more) for a few hours during each business day. Legacy infrastructure is hard-pressed to deliver this increase whereas the cloud is ideal for processing massive, but fluctuating amounts of data against tight deadlines.
On-premises grids present three notable challenges:
- Since almost all portfolio revaluations need significant compute power for the quantitative models, banks that require additional capacity to support FRTB incur a large upfront capital expense to stand up new on-premises grids.
- Most on-premises grids have fixed or standard hardware types, which limit the flexibility banks have to run quantitative models with widely different characteristics for IMA.
- Because FRTB calculations have to complete in a few hours, the compute capacity provisioned for them often has no users during the rest of the day, leading to significant under-utilization.
AWS offers compute, storage, and database tools and services that allow banks to right-size compute as well as store files and objects at scale and with speed. The ability to easily and quickly right-size compute for risk and stress testing on AWS is secure and cost-effective. Financial institutions can mix and match more than 200 instance types for different workloads and access virtually unlimited storage.
This post investigates the use of Amazon EMR as a platform for FRTB IMA calculations. The specific Amazon EMR architecture used is shown in the following diagram

Architecture diagram: Sequence of steps
- On-premises End of the Day trigger starts extract process for position, market, model, and static data.
- Data extract process uploads position, market, model, and static data to Amazon S3.
- Amazon EMR for Apache Spark cluster is created. Worker nodes map FSx for Lustre to S3 bucket (from step 2). Worker nodes also connect to the time series database.
- IMA batch driver (a web service or AWS Lambda process) is called. Batch driver creates compute tasks and submit tasks to Spark Master.
- Spark workers upload historical market data to the time series database. Workers start processing compute tasks.
- Workers save PnL to FSx Lustre directory. Once Spark jobs complete, Amazon FSx directory is exported to Amazon S3.
- PnLs are loaded from Amazon S3 to Amazon Redshift. Amazon Redshift generates aggregation PnL for business units, desks, and legal entities as well as computes Expected Shortfalls.
- Amazon QuickSight loads datasets and display reports.
In this “data-centric” high performance computing (HPC) approach, each portfolio/book is mapped to a separate Amazon EMR node, the required calculations run in parallel on these nodes, and then, the individual PnL results aggregate for the book to compute PnL as well as Expected Shortfall. Note that if one were using Monte Carlo simulation-based models (not the example used explored in this post), one would first generate the simulation paths for the underlying process (e.g., Equity Index SPX price) and then, price all the derivatives (e.g., options) on each Amazon EMR node using these simulated prices.
Solution highlights
Amazon EMR is the industry-leading cloud big data platform for processing vast amounts of data using open source tools such as Apache Spark, Apache Hive, Apache HBase, Apache Flink, Apache Hudi, and Presto. With Amazon EMR, you can run petabyte-scale analysis at less than half of the cost of traditional on-premises solutions and over 3x faster than standard Apache Spark. For short-running jobs, you can spin up and spin down clusters and pay per second for the instances used. For long-running workloads, you can create highly available clusters that automatically scale to meet demand.
Amazon Elastic Compute Cloud (Amazon EC2) provides a diverse selection of 200+ instance types optimized to fit different use cases. This flexibility means that you can choose based on your performance, cost, and availability needs. For example, since batches need to finish within a set number of hours for regulatory report generation, an organization may choose to use Amazon EC2 Reserved Instances (RIs) to run FRTB in production. For development and testing, however, the same organization may choose to optimize compute cost via the use of various Amazon EC2 Spot Instances.
For this purpose of this post, we selected Amazon EC2 m5.24xlarge for the master instance. It is a recommended best practice to use RIs or On-Demand Instances for the Amazon EMR master instance. For worker nodes (Spark executors), we optimized compute cost via the use of Amazon EC2 Spot Instance pricing and instance counts 100 and 200.
Finally, we recommend configuring an Amazon EMR instance fleet to leverage the wide variety of provisioning.
Amazon S3 (Amazon S3) is an object storage service that offers industry-leading scalability, data availability, security, and performance. Amazon S3 is designed for 99.999999999% (11 9’s) of durability and offers virtually unlimited storage capacity with integrated security features that support risk data storage.
FSx for Lustre is the world’s most popular high-performance file system. It is fully managed and integrated with Amazon S3 and optimized for fast processing of workloads such as machine learning, HPC, and financial modeling. When linked to an S3 bucket, an FSx for Lustre file system transparently presents Amazon S3 objects as files and allows you to write changed data back to Amazon S3.
Compared to the Hadoop Distributed File System (HDFS) as a shared file system, Amazon FSx performs better for many small files (e.g., position PnLs array) write. Another advantage of Amazon FSx is that it supports the Portable Operating System Interface (POSIX), so any pricing library/vendor model needs only to adhere to the POSIX standard without any refactoring.
Solution models details
For our proof-of-concept (POC) application, we chose two methodologies for computing an option’s price to demonstrate how the two calculations compare:
- Classic Black Scholes model is widely used and well understood despite known limitations when computing prices of American-style options.

- Longstaff Schwartz (LS) model uses Geometric Brownian Motion (GBM) to simulate stock price for every month till 5 years (60 month points). This makes the model more accurate and much more CPU-intensive.
- The number of Monte Carlo Paths was set to 10,000.
- In a real production scenario, some implementations might run with 20,000 or 100,000 paths, which will increase CPU time.
- The calculation is as follows:

-
-
- St Simulated price at t
- r risk free rate at t
- σ volatility at t(Non Stochastic)
- wt Brownian Motion
- We used the 2nd form of GBM to simulate stock price.
- We used 2 factor basis function for exercise decision.
-
![]()
-
- yt Is the intrinsic value → min (Strike -St, 0)
- From the 10,000 Monte Carlo paths, we took only the paths for which yt is NOT 0
Relative to the LS model, we expected a much shorter runtime for the Black Scholes approach due to its closed form (i.e., a mathematical expression expressed using a finite number of standard operations).
Solution results
We estimated the runtimes of the same portfolio composed of a fast model (Black Scholes) compared to an (as expected) slower model (LS) for 2 million positions. The following table summarizes these results for different instances types and virtual CPU (vCPU) combinations.
| Instance Type | vCPU/Instance | Instance Count | Black Scholes | Longstaff Schwartz |
| c4.8xlarge | 36 | 100 | 50 sec | 640 sec |
| c4.8xlarge | 36 | 200 | 28 sec | 435 sec |
| c5.9xlarge | 36 | 100 | 20 sec | 600 sec |
| c5.9xlarge | 36 | 200 | 14 sec | 400 sec |
| c5.24xlarge | 96 | 100 | 47 sec | 440 sec |
| c5.24xlarge | 96 | 200 | 27 sec | 280 sec |
| c5.24xlarge | 96 | 40 | 30 sec | 760 sec |
| c5n.xlarge | 4 | 100 | 50 sec | 1740 sec |
| c5n.18xlarge | 72 | 20 | 53 sec | 2560 sec |
The following two plots are drawn using data from the preceding table. In each case, the x-axis represents the total vCPU (vCPU/Instance * Instance Count) and the y-axis represents runtime.
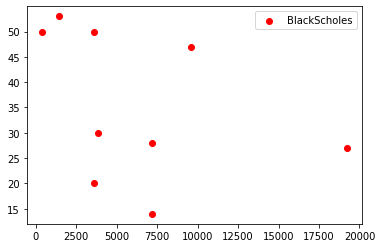

From these plots we can infer the following. For the LS algorithm, runtime can be seen to decrease (an exponential decay rather than linear) with increasing vCPUs but is not linear. In stark contrast, for the shorter-running Black Scholes models, there is no discernable trend with addition of vCPUs – the spread of results is possibly a function of the diverse set of instance type selected. This supposition is supported by noting that for the same total vCPUs, there are multiple runtime points. Examining the table indicates these are for different instance types, revealing that a newer instance family took less time.
Time and cost analysis
The previous section presented the calculation runtimes for various instance types and vCPU to run 2 million positions.
Here, we give a time estimate for running the entire FRTB compute for 1 day using C5.24xlarge – 200 instances as a reference for the time estimate. We are selecting the LS model – as the model is much more CPU-intensive, the time estimate will be closer to the maximum time (as in real FRTB run) with 2 million derivative positions that need Monte Carlo-type simulations.
For LS, runtime was 280 seconds or approximately, 5 minutes. For one year’s worth of historical data (around 250 trading days) and 4 risk factors (e.g., equity option, base valuation, partial valuation for equity, interest rate, and volatility surface), the total number of compute needed for each position is 250*4 = 1000 valuations/position.
From above, total time with the chosen cluster size = 5 minutes*1000 minutes or approximately, 85 hours. This is way too long to run a batch, so we need to choose a larger number of compute clusters.
If we set our target time to finish the FRTB batch to 5 hours, we then need 85 hours/5 hours = 17 clusters (each cluster with C5.24xlarge, 200 instances) will bring down the time from 85 to 5 hours. Each cluster could run independently (e.g., by desk, business unit, or region).
As indicated in the above table, runtime is significantly lower when running Black Scholes models. As a result, based on the type of positions in a portfolio and model complexities (compute wise), runtime and cost will vary.
Helpful resources: Amazon EC2 instance pricing and Amazon EMR pricing
AWS benefits
-
Multi-workload grids vs single workload grids
Organizations typically use a common grid for different workloads on-premises, which can lead to long backlogs. In addition, most on-premises grids have fixed or standard hardware types, which limit flexibility. On AWS, customers can leverage each grid optimized for the specific workload.


-
Over-provisioning due to “long tail” tasks
Financial instruments pricing and risk batches often have many short-running tasks and few long-running tasks – a scenario commonly referred to as the “long tail.” In the long tail period, grid capacity is not fully utilized. On AWS, customers can provision compute resources dynamically, which enables them to have a small grid for long-running tasks.
| On-Premises | vs. | On AWS |
 |
|
|
| Another aspect of different type of grid for different workloads is to reduce the “long tail” often observed in pricing grids. Since an on-premises grid is generally shared across different types of quantitative models, long-running tasks often take much longer to finish than the rest of the batch. This results in under-utilization of the grid. | On AWS, multiple clusters can be provisioned where each cluster is optimized and sized for a specific type of workload.
|


-
24×7 provisioning for peaks that last only a few hours
In typical pricing and risk grids, most of the batches run for only a couple of hours in a day.
| On-Premises | Vs. | On AWS |
 |
 |
|
| On-premises grid capacity is pre-provisioned, meaning grid capacity is not used when no batch is running. | Normally, End of Day batches run for few hours in a day, which is another reason why AWS is ideal for running grid. In AWS, customers can use just-in-time capacity. Grid capacity is procured only during the hours FRTB batches are running. After the run is complete, clusters can be shut down. | |
| Since on-premises grid capacity is fixed, there is almost no capacity to re-run a batch in case an issue is discovered (e.g., input data) during the middle of the batch run.
|
Due to the elasticity of AWS resources, re-running a batch is easily achievable. In general, each desk can compute risk measures (Expected Shortfall/VaR) without waiting for other desks to finish their compute. |
-
High bar on security
AWS understands the unique security, regulatory, and compliance obligations financial institutions face on a global scale. From infrastructure to automation, financial institutions have all the tools and resources they need to create a compliant and secure environment on AWS. AWS offers the largest global footprint with 76 Availability Zones (AZs) across 24 launched Regions.
This network is architected to protect customer information, identities, applications, and devices. AWS helps customers meet core security and compliance requirements such as data locality, protection, and confidentiality with our comprehensive services and features. Customers can run Amazon EMR in their own virtual private cloud (VPC), so the cluster is isolated from other applications in other VPCs. Amazon EMR supports data encryption at rest and in transit. Traffic between Amazon S3 and cluster nodes can be encrypted using Transport Layer Security (TSL). Data at rest in Amazon S3 can be encrypted using server-side or customer-side encryption.
We strongly recommend that customer run their Amazon EMR clusters on the private subnet-chosen VPC to prevent the cluster from being accessible from the Internet. Amazon S3 data is accessed by a VPC endpoint, which ensures no data leaves the AWS network.
| On-Premises | vs. | On AWS |
 |
 |
-
Less resource-intensive to run than on-premises grids
Finally, managing large on-premises grids is resource-intensive. On top of hardware procurement, ongoing maintenance, and patching add up in terms of cost, time, and effort. AWS offers various types of cost and time optimization. AWS Managed Services operates AWS infrastructure on behalf of customers, automating common activities such as change requests, monitoring, patch management, security, and backup services.
Helpful resource: AWS Total Cost of Ownership Calculators
Conclusion
As we optimized the design, we noted several key observations:
- There is an optimized cluster size for each model and workload type. Creating very large clusters does not reduce time linearly.
- Yarn (Resource Manager) optimizes the cluster well. Manually setting the number of executors and core executors does not significantly change the runtime.
- Keeping the number of partitions equal to two to four times the number of virtual cores. There was little difference in runtime observed between different partition sizes.
- Future tuning eliminates the long-running tail for further optimizations. Save each position’s compute time and next run repartition position data so that all partitions take almost the same time.
As financial institutions are preparing to run FRTB, AWS provides a qualitative way to address their business need. By leveraging AWS elasticity and velocity, they can more quickly respond to new and complex regulatory requirements. Our reference implementation demonstrates how financial institutions can take advantage of AWS compute, storage, and other services.