Amazon Transcribe is an automatic speech recognition (ASR) service that makes it easy for developers to add speech-to-text capability to applications. We’re excited to announce the availability of a new feature called Channel Identification, which allows users to process multi-channel audio files and retrieve a single transcript annotated with respective channel labels.
Contact centers, in particular, stand to benefit tremendously by using channel identification. Phone conversations between callers and agents are typically recorded on separate channels and merged into a single audio file. Using this new feature, contact centers can process the single audio using Amazon Transcribe, which will intelligently transcribe the speech recorded on each channel, and then produce a final transcript with channel labels. Word-level timestamping for each channel’s output will enable contact centers to recreate a coherent exchange between the caller and agent.
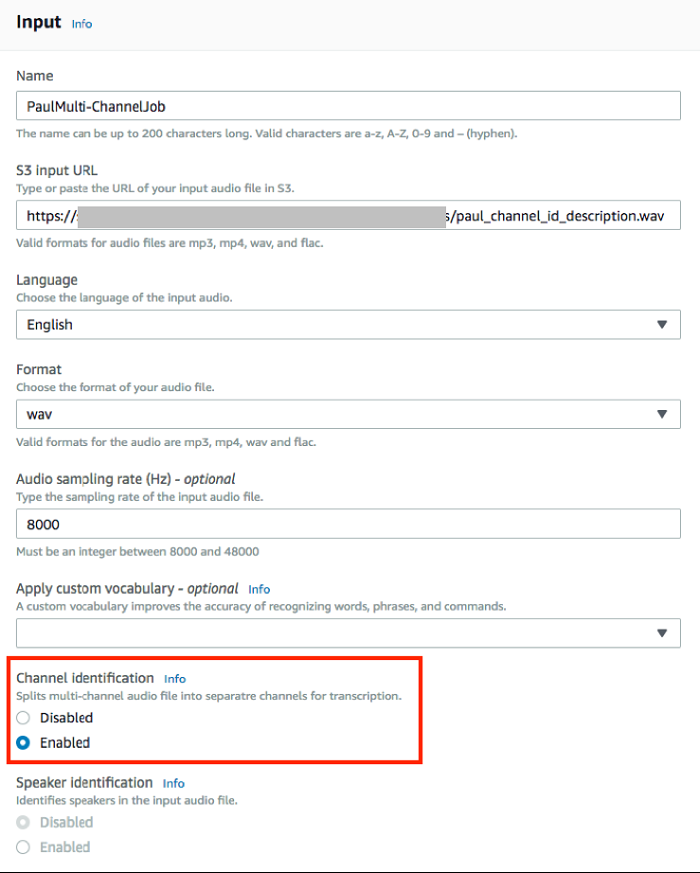
You can work with channel identification using either the Amazon Transcribe console or using the AWS CLI. In the console, simply enable the parameter Channel Identification.
In the CLI, simply call StartTranscriptionJob and set the Channel Identification parameter to true. Here’s a sample Python script that starts a transcription job with channel identification enabled:
from __future__ import print_function
import time
import boto3
import json
import requests
# given an array of items (JSON output from Amazon Transcribe, get the transcript as a string)
def get_transcript_text(items):
transcript_text = ""
for item in items:
if (item['type'] == 'pronunciation'):
transcript_text += " {0}".format(item['alternatives'][0]["content"])
else:
transcript_text += "{0}".format(item['alternatives'][0]["content"])
return transcript_text
transcribe = boto3.client('transcribe')
job_name = "demo-qldh-106"
job_uri = "s3://mast-mast-3/private/labs/transcribe-speech/aus-qldh/0b3debff-fedc-4bee-91e5-3faa3727ee80.wav"
transcribe.start_transcription_job(
TranscriptionJobName=job_name,
Media={'MediaFileUri': job_uri},
MediaFormat='wav',
LanguageCode='en-US',
Settings={'ChannelIdentification': True}
)
print("{0}: Started job {1} ...".format(time.ctime(), job_name))
while True:
status = transcribe.get_transcription_job(TranscriptionJobName=job_name)
if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']:
break
print("{0}: Still going ({1}) ... ".format(time.ctime(), status['TranscriptionJob']['TranscriptionJobStatus']))
time.sleep(30)
print("{0}: It's done ({1}).".format(time.ctime(), status['TranscriptionJob']['TranscriptionJobStatus']))
# if we completed successfully, then get the full text of the transcript
if (status['TranscriptionJob']['TranscriptionJobStatus'] == 'COMPLETED'):
transcript_uri = status['TranscriptionJob']['Transcript']['TranscriptFileUri']
# get the transcript JSON
transcript = json.loads((requests.get(transcript_uri)).text)
print("Transcript:")
# we could check the number_of_channels to be sure, but we'll just assume two channels for this example
# get the left channel transcript as a blob of text
print(get_transcript_text(transcript['results']['channel_labels']['channels'][0]['items']))
# get the right channel transcript as a blob of text
print(get_transcript_text(transcript['results']['channel_labels']['channels'][1]['items']))
else:
print("Job status is {0}".format(status['TranscriptionJob']['TranscriptionJobStatus']))
The output transcript will demonstrate two text blocks indicated by channel labels. In the Amazon Transcribe console, choose the Channel Identification tab to get a brief preview:

The following is a sample output transcript in JSON format. It shows the merged transcript in the transcript section, and under channels array, you can find the transcript items for each channel.
{
"jobName": "job id",
"accountId": "account id",
"results": {
"transcripts": [
{
"transcript": "When you try ... It seems to ..."
}
],
"channel_labels": {
"channels": [
{
"channel_label": "ch_0",
"items": [
{
"start_time": "12.282",
"end_time": "12.592",
"alternatives": [
{
"confidence": "1.0000",
"content": "When"
}
],
"type": "pronunciation"
},
{
"start_time": "12.592",
"end_time": "12.692",
"alternatives": [
{
"confidence": "0.8787",
"content": "you"
}
],
"type": "pronunciation"
},
{
"start_time": "12.702",
"end_time": "13.252",
"alternatives": [
{
"confidence": "0.8318",
"content": "try"
}
],
"type": "pronunciation"
},
Transcription abbreviated
]
},
{
"channel_label": "ch_1",
"items": [
{
"start_time": "12.379",
"end_time": "12.589",
"alternatives": [
{
"confidence": "0.5645",
"content": "It"
}
],
"type": "pronunciation"
},
{
"start_time": "12.599",
"end_time": "12.659",
"alternatives": [
{
"confidence": "0.2907",
"content": "seems"
}
],
"type": "pronunciation"
},
{
"start_time": "12.669",
"end_time": "13.029",
"alternatives": [
{
"confidence": "0.2497",
"content": "to"
}
],
"type": "pronunciation"
},
Transcription abbreviated
]
}
}
By default, this feature will process two channels. You can request support for additional channels (up to 5). Refer to this documentation for more details.
Channel Identification is available in all AWS Regions where Amazon Transcribe is available at no additional cost. For more information, visit this documentation page.
About the Author
 Paul Zhao is a Sr. Product Manager at AWS machine learning solutions. He manages the Amazon Transcribe service. Outside of work Paul is a motorcycle enthusiast and avid woodworker.
Paul Zhao is a Sr. Product Manager at AWS machine learning solutions. He manages the Amazon Transcribe service. Outside of work Paul is a motorcycle enthusiast and avid woodworker.

Bhaskar Bagchi is a Software Development Engineer at AWS Machine Learning. In his spare time, he likes to play board games and sing.