Artificial Intelligence
Author: Flora Wang
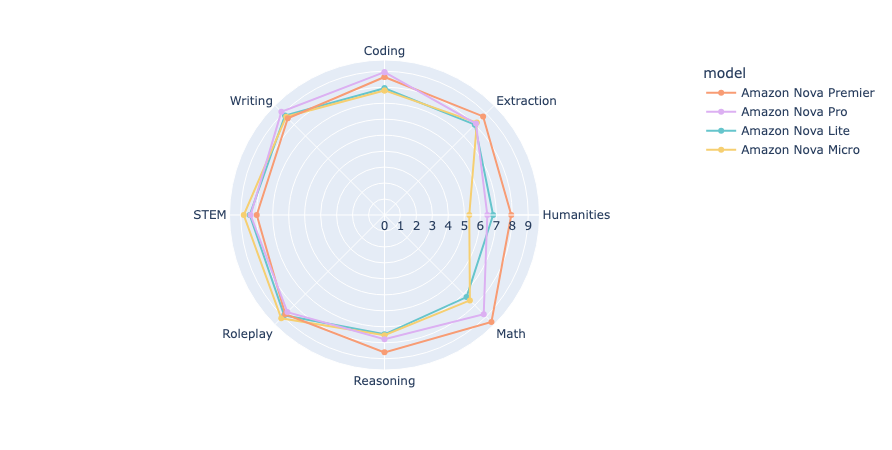
Benchmarking Amazon Nova: A comprehensive analysis through MT-Bench and Arena-Hard-Auto
The repositories for MT-Bench and Arena-Hard were originally developed using OpenAI’s GPT API, primarily employing GPT-4 as the judge. Our team has expanded its functionality by integrating it with the Amazon Bedrock API to enable using Anthropic’s Claude Sonnet on Amazon as judge. In this post, we use both MT-Bench and Arena-Hard to benchmark Amazon Nova models by comparing them to other leading LLMs available through Amazon Bedrock.
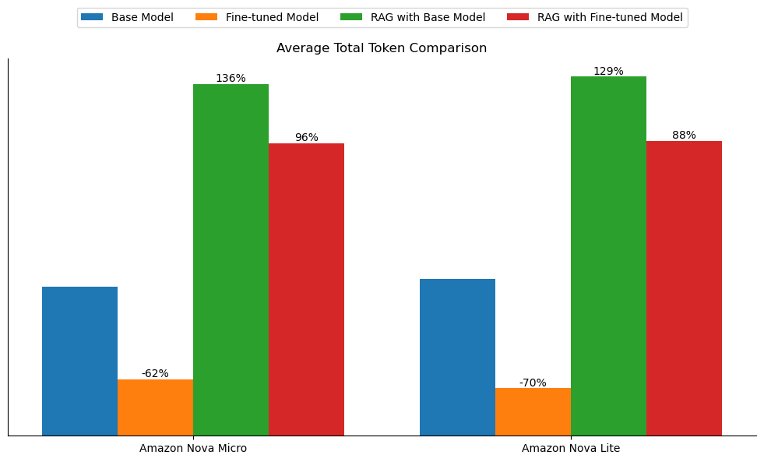
Model customization, RAG, or both: A case study with Amazon Nova
The introduction of Amazon Nova models represent a significant advancement in the field of AI, offering new opportunities for large language model (LLM) optimization. In this post, we demonstrate how to effectively perform model customization and RAG with Amazon Nova models as a baseline. We conducted a comprehensive comparison study between model customization and RAG using the latest Amazon Nova models, and share these valuable insights.