Artificial Intelligence

Author: Peter Chung
Peter Chung is a Solutions Architect for AWS. He is passionate about helping customers uncover insights from their data. He has been building solutions to help organizations make data-driven decisions in both the public and private sectors. He holds all AWS certifications and two GCP certifications.

How TransPerfect Improved Translation Quality and Efficiency Using Amazon Bedrock
This post describes how the AWS Customer Channel Technology – Localization Team worked with TransPerfect to integrate Amazon Bedrock into the GlobalLink translation management system, a cloud-based solution designed to help organizations manage their multilingual content and translation workflows. Organizations use TransPerfect’s solution to rapidly create and deploy content at scale in multiple languages using AI.

Announcing Amazon S3 access point support for Amazon SageMaker Data Wrangler
In this post, we walk you through importing data from, and exporting data to, an S3 access point in SageMaker Data Wrangler.

Accelerate business outcomes with 70% performance improvements to data processing, training, and inference with Amazon SageMaker Canvas
Amazon SageMaker Canvas is a visual interface that enables business analysts to generate accurate machine learning (ML) predictions on their own, without requiring any ML experience or having to write a single line of code. SageMaker Canvas’s intuitive user interface lets business analysts browse and access disparate data sources in the cloud or on premises, […]

Unified data preparation and model training with Amazon SageMaker Data Wrangler and Amazon SageMaker Autopilot – Part 1
September 2023: This post was reviewed and updated for accuracy. Data fuels machine learning (ML); the quality of data has a direct impact on the quality of ML models. Therefore, improving data quality and employing the right feature engineering techniques are critical to creating accurate ML models. ML practitioners often tediously iterate on feature engineering, […]

Easily create and store features in Amazon SageMaker without code
Data scientists and machine learning (ML) engineers often prepare their data before building ML models. Data preparation typically includes data preprocessing and feature engineering. You preprocess data by transforming data into the right shape and quality for training, and you engineer features by selecting, transforming, and creating variables when building a predictive model. Amazon SageMaker […]

Build a risk management machine learning workflow on Amazon SageMaker with no code
Since the global financial crisis, risk management has taken a major role in shaping decision-making for banks, including predicting loan status for potential customers. This is often a data-intensive exercise that requires machine learning (ML). However, not all organizations have the data science resources and expertise to build a risk management ML workflow. Amazon SageMaker […]
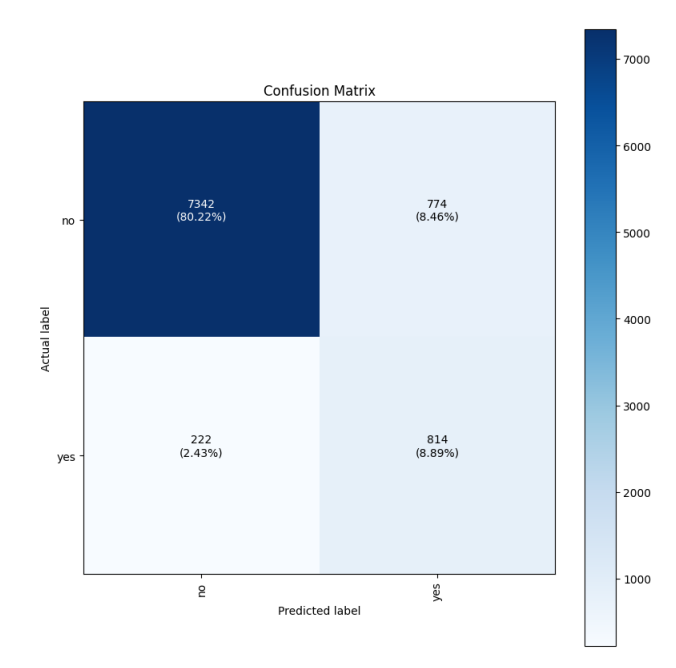
Automatically generate model evaluation metrics using SageMaker Autopilot Model Quality Reports
Amazon SageMaker Autopilot helps you complete an end-to-end machine learning (ML) workflow by automating the steps of feature engineering, training, tuning, and deploying an ML model for inference. You provide SageMaker Autopilot with a tabular data set and a target attribute to predict. Then, SageMaker Autopilot automatically explores your data, trains, tunes, ranks and finds […]

Create a cross-account machine learning training and deployment environment with AWS Code Pipeline
A continuous integration and continuous delivery (CI/CD) pipeline helps you automate steps in your machine learning (ML) applications such as data ingestion, data preparation, feature engineering, modeling training, and model deployment. A pipeline across multiple AWS accounts improves security, agility, and resilience because an AWS account provides a natural security and access boundary for your […]