AWS Machine Learning Blog
Computer vision-based anomaly detection using Amazon Lookout for Vision and AWS Panorama
July 2023: This post was reviewed for accuracy.
This is the second post in the two-part series on how Tyson Foods Inc., is using computer vision applications at the edge to automate industrial processes inside their meat processing plants. In Part 1, we discussed an inventory counting application at packaging lines built with Amazon SageMaker and AWS Panorama . In this post, we discuss a vision-based anomaly detection solution at the edge for predictive maintenance of industrial equipment.
Operational excellence is a key priority at Tyson Foods. Predictive maintenance is an essential asset for achieving this objective by continuously improving overall equipment effectiveness (OEE). In 2021, Tyson Foods launched a machine learning (ML) based computer vision project to identify failing product carriers during production to prevent them from impacting team member safety, operations, or product quality. When a product carrier breaks or moves into the wrong position, production must be stopped. If it’s not caught in time, it poses a threat to team member safety and machinery. With a manual inspection method, an operator inspects 8,000 pins per line. This is a slow and challenging task because attention to detail is critical. ML practitioners at Tyson Foods have built computer vision models to automate the inspection process and detect anomalies continuously. This process can enable the maintenance team to reduce the cycle time and improve the reliability of inspecting 8,000 pins.
Developing a custom ML model to analyze images and detect anomalies, and making these models run efficiently at the edge is a challenging task. This requires specialized expertise, time, and resources. The entire development cycle may take months to complete. With the approaches mentioned in Part 1 of this series, we completed the project for monitoring the condition of the product carriers at Tyson Foods in record time using AWS Managed Services such as Amazon Lookout for Vision.
Solution overview
The patterns, code, and infrastructure designed for the tray counting use case in Part 1 were readily replicated in the product carrier project. Although at first glance these projects may seem very different, at their core they are made up of the same five components: image capture, labeling, model training, frame deduplication, and inference.
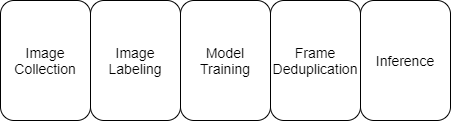
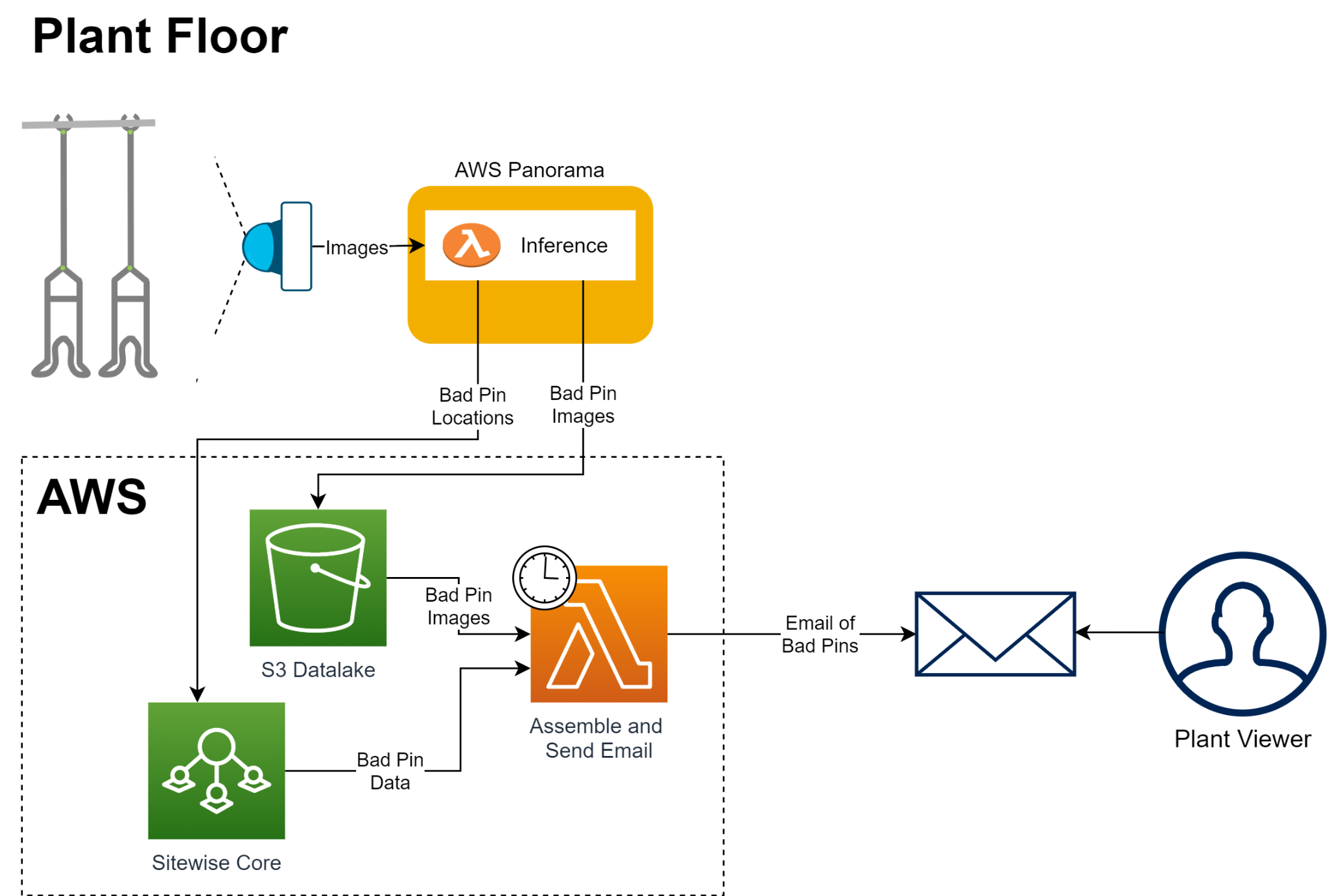
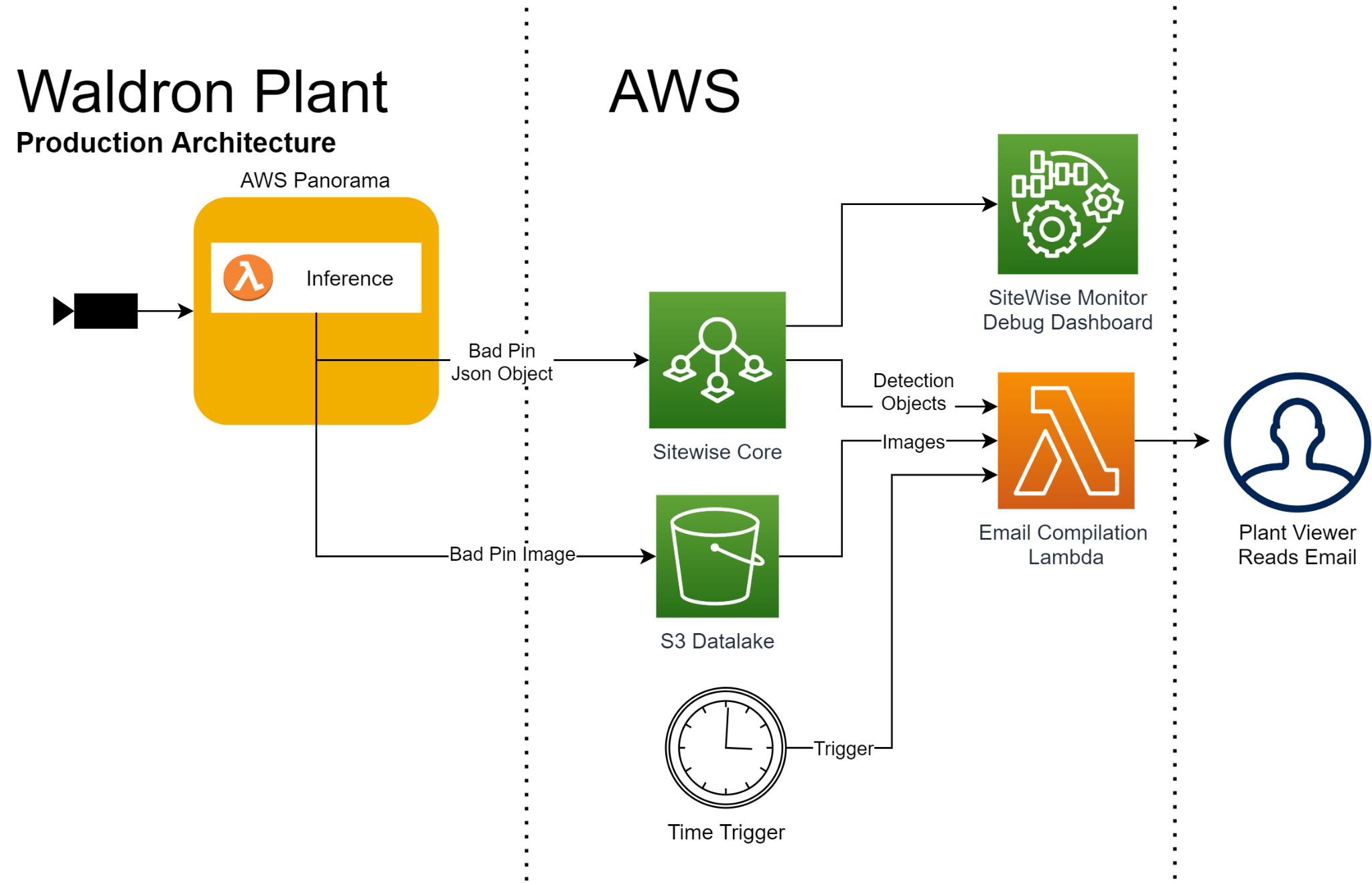
This post demonstrates how to set up a computer vision-based anomaly detection solution for failing product carriers (or similar manufacturing line assembly) using AWS Panorama and Lookout for Vision. The workflow begins with inference via an object detection model on an AWS Panorama device at the edge. The object detection model crops the image and passes the result to the Lookout for Vision anomaly detection model that classifies the pin images. The anomalous pin images and model results are sent to the cloud and available for additional processing.
The following diagram illustrates this architecture.
Prerequisites
To follow along with this post, you need the following:
- An AWS Panorama compatible camera
- An AWS Panorama Appliance
- An AWS account with access to the following services:
- Amazon EventBridge
- AWS Lambda
- Amazon Lookout for Vision
- AWS Panorama
- Amazon Simple Storage Service (Amazon S3)
- AWS IoT SiteWise
Train an object detection model
The first stage of our multi-model inference design is an SSD object detection model trained to detect product carriers and flags. The pins are used to train the anomaly classification model using Lookout for Vision. The flag, referencing the beginning of the product carrier line, helps us track each loop cycle and deduplicate anomaly detections.
The following image is an example inference result from the pin detection SSD model.

Train an anomaly classification model using Lookout for Vision
Lookout for Vision is a fully managed ML service that uses computer vision to help identify visual defects in objects. It allows you to build an anomaly detection model quickly with little-to-no code and requires very little data to start (minimum 20 normal and 10 anomaly images). Training a Lookout for Vision model follows a four-step process:
- Create a Lookout for Vision project.
- Build a product carrier dataset.
- Train and tune the Lookout for Vision model.
- Export the Lookout for Vision model for inference.
In this section, we walk you through Steps 1–3.
Create a Lookout for Vision project
For instructions on creating a Lookout for Vision project, see Creating your project.
Build a product carrier dataset
The dataset for Lookout for Vision has to be square images, JPG or PNG format, minimum pixel size of 64 x 64, and maximum pixel size of 4096 x 4096. To generate a dataset that satisfies the requirements, we had to crop each bounding box and resize them while preserving the original aspect ratio using the following Python code. We add this code to the image capture pipeline described in Part 1 to generate the final 150 x 150 pixel images for Lookout for Vision.
The following are examples of processed product carrier images.
 |
 |
 |
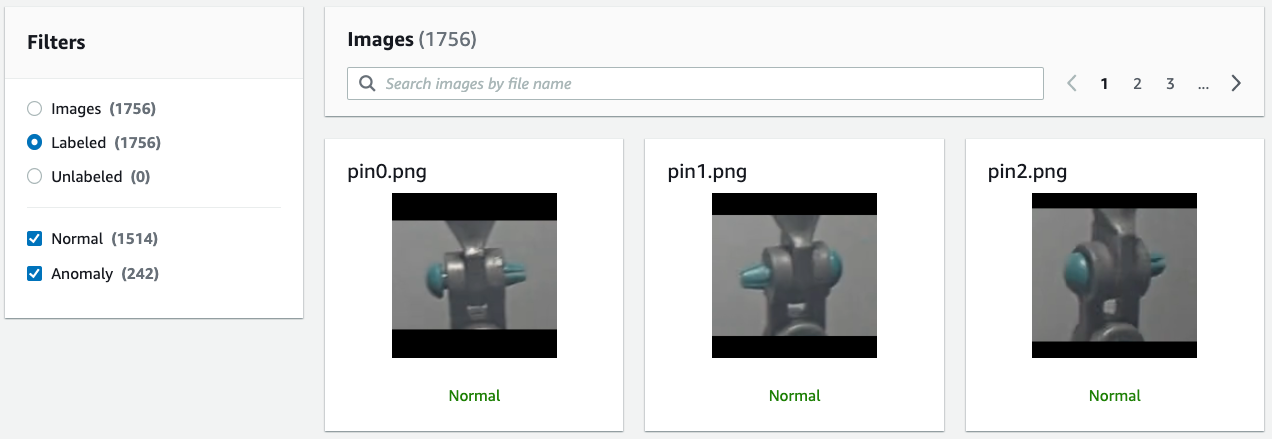
We label the images through Amazon SageMaker Ground Truth, which returns a label manifest file. This file is imported into Lookout for Vision to create the anomaly detection dataset. You can label the images within the Lookout for Vision platform, but we didn’t use that approach in this project. The following screenshot shows the labeled dataset on the Lookout for Vision console.
Train and tune the Lookout for Vision model
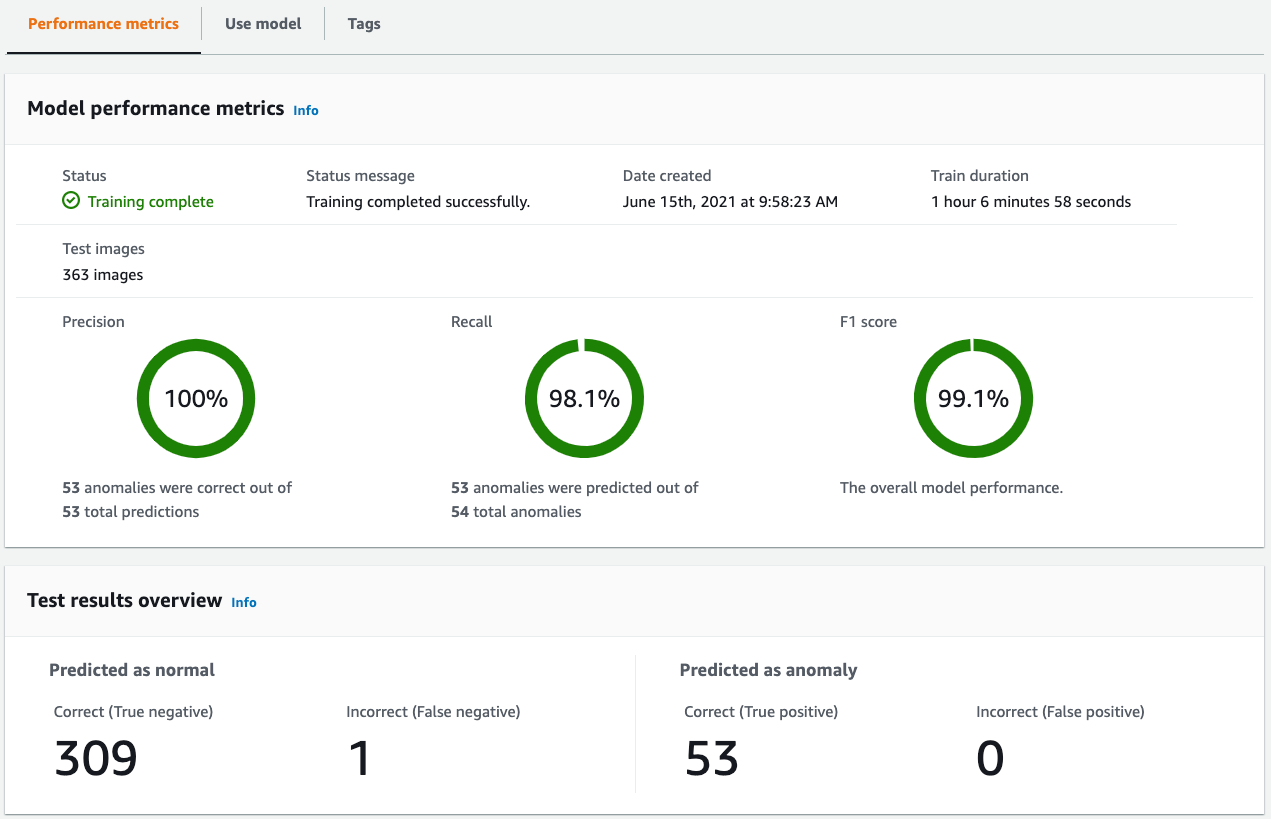
Training an anomaly detection model in Lookout for Vision is as simple as a click of a button. Lookout for Vision automatically holds out 20% of the data as a test set to validate the model performance. The key to generating good model results is to focus on labeling and image quality. The initial image size used was too small, and critical details were lost due to resolution. Increasing the resolution from 64 x 64 to 150 x 150 resulted in a significant jump in model accuracy. To tune the labels, the development team spent a significant amount of time with subject matter experts from the plant to utilize their knowledge in designing the definitions for each class. It was imperative that these class definitions were very clear, and it took a few iterations to get them perfect. The following screenshot shows the results achieved with well-established class definitions.
Develop the AWS Panorama application
The AWS Panorama application is an inference container deployed to the AWS Panorama Appliance to process input video streams, run inference, and output video results using the AWS Panorama SDK. Most of the inference code is the same as in Part 1; the following features are added specifically for this product carrier use case:
- Build a frame inference trigger
- Run Lookout for Vision inference
- Deduplicate and isolate pin location
Build a frame inference trigger
For this use case, our product carriers are moving continuously across the video frame, and the same pins may be detected repeatedly until it moves off of the camera view. To avoid sending duplicated pins to the Lookout for Vision model for anomaly classification and wasting compute resources, we developed a software trigger in our inference code to downsample the frames and reduce the number of duplicated pins for inference. In the following screenshot, the minimum number of pins detected is 8 and the maximum number of pins detected is 10.

The logic determines the trigger using product carrier IDs, which is a counter for the number of new product carriers moving into the camera view. We get that by determining when the number of bounding boxes in a frame reaches the max value. As shown in the preceding figure, there is a min and max possible bounding boxes detected at any given time. The count oscillates between the min and max value, which corresponds to a new product carrier moving into the camera view. The following figure illustrates the oscillation pattern. Because a camera frame can only fit six product carriers, we know an entire frame shifted off when the product carrier ID incremented by 6.

Run Lookout for Vision inference
We crop the bounding boxes from the frame image and process them using the same resize function described earlier, and then forward these images to the Lookout for Vision model for anomaly classification. In response, the Lookout for Vision model produces a label (normal or anomaly) and confidence score.
Isolate pin locations and deduplicate anomaly detections
Lastly for this use case, it was important to identify the relative location of the product carriers and only generate one entry per bad pin to avoid duplications. To track the pin location, inference code was written to use the flag as a point of reference and count the product carrier ID. When an anomaly is detected, the product carrier ID is recorded with the pin image to provide the location reference relative to the flag. We also use this flag to help us deduplicate the anomaly detections and track when an entire product carrier line has looped around. There is a cycle ID parameter that gets incremented every time the flag appears, and all the parameters like product carrier ID reset to 0 to start a new cycle.
Deploy models at the edge with AWS Panorama
When we have the models and the inference code ready, we package the object detection model, inference code, and camera stream into a container and deploy to AWS Panorama using the same deployment pattern described in Part 1.
Email alerts
Whenever the system detects an anomaly, the image containing the defective pin is sent to Amazon S3 for storage, and the metadata associated with it is sent to AWS IoT SiteWise. At the end of each shift, an EventBridge event triggers a Lambda function, which uses the images and metadata to send a summary email to the plant staff. The plant staff uses this information when making repairs during shift change.
Conclusion
In this post, we demonstrated how to set up a vision-based anomaly detection system in a production environment using Lookout for Vision and AWS Panorama. With this solution, plants can save 1 hour of team member time per day per line. This would save this plant alone an estimated 15,000 hours of skilled labor annually. This would free up the time of valuable Tyson team members to complete other, more complex tasks.
The models trained in this process performed well. The SSD pin detection model achieved 95% accuracy across both classes. The Lookout for Vision model was tuned to perform at 99.1% accuracy for failing pin detection. Despite the two models utilized in this project, the inference code was easily able to keep up with line speed, running at around 10 FPS.
By far the most exciting result of this project was the speedup in development time. Although this project utilizes two models and more complex application code than the project in Part 1, it took 12% less developer time to complete. This agility is only possible because of the repeatable patterns established in Part 1 and using managed services from AWS. This combination made our final solutions faster to scale and industry ready. Learn more about Amazon Lookout for Vision by going to the Amazon Lookout for Vision Resources page. You can also view other examples of AWS Panorama in action by going to the GitHub repo and Developer’s Guide.
View the Turkic translated version of this post here.
About the Authors
 Audrey Timmerman is a Sr Applications Developer at Tyson Foods. She is a Computer Engineering Graduate from the University of Arkansas and has been on the Emerging Technology team at Tyson Foods for 2 years. She has an interest in computer vision, machine learning, and IoT applications.
Audrey Timmerman is a Sr Applications Developer at Tyson Foods. She is a Computer Engineering Graduate from the University of Arkansas and has been on the Emerging Technology team at Tyson Foods for 2 years. She has an interest in computer vision, machine learning, and IoT applications.
 James Wu is a Senior Customer Solutions Manager at AWS, based in Dallas, TX. He works with customers to accelerate their cloud journey and fast-track their business value realization. In addition to that, James is also passionate about developing and scaling large AI/ ML solutions across various domains. Prior to joining AWS, he led a multi-discipline innovation technology team with ML engineers and software developers for a top global firm in the market and advertising industry.
James Wu is a Senior Customer Solutions Manager at AWS, based in Dallas, TX. He works with customers to accelerate their cloud journey and fast-track their business value realization. In addition to that, James is also passionate about developing and scaling large AI/ ML solutions across various domains. Prior to joining AWS, he led a multi-discipline innovation technology team with ML engineers and software developers for a top global firm in the market and advertising industry.
 Farooq Sabir is a Senior AI/ML Specialist Solutions Architect at AWS. He holds a PhD in Electrical Engineering from the University of Texas at Austin. He helps customers solve their business problems using data science, machine learning, artificial intelligence, and numerical optimization.
Farooq Sabir is a Senior AI/ML Specialist Solutions Architect at AWS. He holds a PhD in Electrical Engineering from the University of Texas at Austin. He helps customers solve their business problems using data science, machine learning, artificial intelligence, and numerical optimization.
 Elizabeth Samara Rubio is a Principal Specialist in the WWSO at Amazon Web Services, driving new AI/ML and computer vision solutions across industries, including industrial and manufacturing sectors. Prior to joining Amazon, Elizabeth was a Managing Director at Accenture leading North America Industry X growth and strategy, Divisional Vice President at AMETEK, and Business Unit Manager at Cognex.
Elizabeth Samara Rubio is a Principal Specialist in the WWSO at Amazon Web Services, driving new AI/ML and computer vision solutions across industries, including industrial and manufacturing sectors. Prior to joining Amazon, Elizabeth was a Managing Director at Accenture leading North America Industry X growth and strategy, Divisional Vice President at AMETEK, and Business Unit Manager at Cognex.
 Shreyas Subramanian is an AI/ML specialist Solutions Architect, and helps customers by using Machine Learning to solve their business challenges on the AWS Cloud.
Shreyas Subramanian is an AI/ML specialist Solutions Architect, and helps customers by using Machine Learning to solve their business challenges on the AWS Cloud.