AWS Machine Learning Blog
Introducing recommendation scores in Amazon Personalize
Amazon Personalize enables you to personalize your website, app, ads, emails, and more, using the same machine learning technology as used by Amazon.com, without requiring any prior machine learning experience. Using Amazon Personalize, you can generate personalized recommendations for your users through a simple API interface. We are pleased to announce that Amazon Personalize now provides recommendations scores generated with each personalized recommendation. These scores can help you understand the relative difference in the relevance of recommendations. This post will walk you through the usage and interpretation of these scores.
Using recommendation scores
Recommendation scores from Amazon Personalize help you apply additional business logic on the recommendations. Let us look at a few illustrative examples below:
- Recommend items above a relative threshold, for example only recommend items whose score > 50% of the highest score among the returned items. It is not recommended to have absolute thresholds, for example only recommend items whose recommendation score > 0.001
- Perform a special action when an item has a very high score for a user. For example, if an item has a score > 0.2, send a special notification to the user or show a special UI element to let them know about this high-confidence item.
- Perform custom reranking on Personalize results e.g. balance relevance of recommendations with other business objective such as displaying sponsored content.
Recommendation scores are available through real-time recommendations and batch recommendations. For real-time recommendations, they are also available through the Amazon Personalize console. Scores are enabled for solution versions created using the following recipes:
arn:aws:personalize:::recipe/aws-hrnnarn:aws:personalize:::recipe/aws-hrnn-metadataarn:aws:personalize:::recipe/aws-hrnn-coldstartarn:aws:personalize:::recipe/aws-personalized-ranking
At this time, scores are not available for solutions created using aws-sims and aws-popularity-count recipes.
In this post we give a brief demonstration of getting recommendation scores on the console. If you have not used Amazon Personalize before, see Getting Started before proceeding.
Getting scores for real-time recommendations
Amazon Personalize console provides an easy way to spot check results from GetRecommendations or GetPersonalizedRanking APIs. In production applications you would call these APIs using the AWS CLI or a language-specific SDKs. To retrieve the recommendations scores please update your Amazon Personalize SDK. For more information, see Getting Real-Time Recommendations.
The following steps detail how to get the recommendations and scores from the console.
Choosing your campaign
In Amazon Personalize a campaign is used to make recommendations for your users. You will need a campaign whose solution version uses a recipe that supports scores, as listed above. You can either create a new campaign, or reuse an existing one.
To create a new campaign, complete the following steps:
- On the Campaigns tab, choose Create Campaign.
- For Campaign name, enter a name.
- For Solution, choose the solution and then the solution version which uses a scores-enabled recipe
- Choose Create campaign.

The following screenshot shows the details of a Campaign using a Solution created with aws-hrnn recipe. This Campaign will be used to produce recommendation scores.

Getting recommendations
After you create or update your campaign, you can get recommended items for a user, similar items for an item or a reranked list of input items for a user. In the Campaigns detail page, enter the userId, itemId, or the inputList you want to test.
The following screenshot shows the Campaign detail page with results from a GetRecommendations call which include the recommended items and their scores.
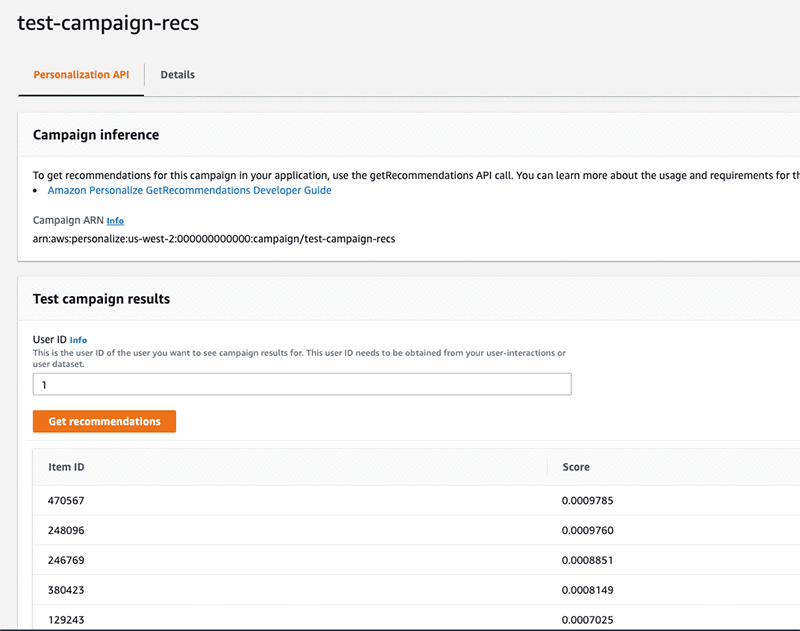
For a given user, HRNN recipe-based solutions score all the items in your item dataset relative to each other, such that the score for each item is between 0 and 1 inclusive, and such that the total of all items scores for a user equals 1. For example, if you are generating movie recommendations for a user and there are three movies in the item dataset, their scores could be .6, .3, and .1. If you have 10,000 movies in your item dataset, the average score will be 1/10,000, and even the highest-scoring movies might have small absolute scores. Therefore, scores should be interpreted relatively.
In mathematical terms, HRNN scores for each user-item pair (u,i) are computed as follows, where “exp” is the exponential function, wu and wi/j are learned user and item embeddings respectively, and Σ represents summation over all items in the item dataset:
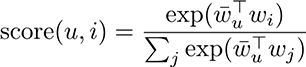
Notice the inner or dot product between the user and item embeddings wu and wi/j, which expresses the level of fit between a particular user and item.
The following screenshot shows the Campaign detail page with a successful GetPersonalizedRanking call returning scores at bottom-right.
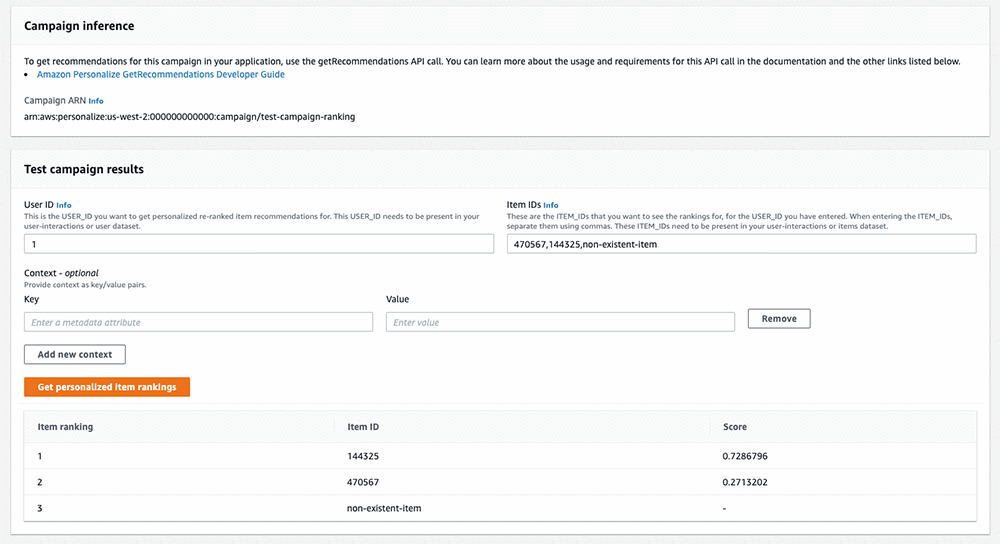
For Solutions created using aws-personalized-ranking recipe the items in output from GetPersonalizedRanking API are also scored relative to each other on a scale from 0 to 1. However, unlike results from GetRecommendations API, scores sum to 1 over the input ItemIDs instead of over all possible items in the item dataset. Since the input list is typically much smaller than total number of items in the ITEMS dataset, the absolute values can appear larger than say score for the same user – item pair from GetRecommendations API. Scores for different items in the inputList for GetPersonalizedRanking operations should thus be interpreted relative to each other.
Mathematically, the scoring function for GetPersonalizedRanking is identical to GetRecommendations, except that it only considers the input items for reranking. This means that scores closer to 1 are more likely, as there are fewer other items to divide up the score:

For GetPersonalizedRanking API, items in the inputList that are not in the ITEMS or INTERACTIONS dataset at time of training are returned without a score and ranked to the end of the list.
Getting scores for batch recommendations
Scores are included in the results of batch inference jobs created using a solution version derived from a scores-enabled recipe. Complete the following steps to get scores for batch recommendations. For more information, see Getting Batch Recommendations.
- On the Amazon Personalize console, on the Batch inference jobs tab, create a new batch inference job using a solution version with a scores-enabled recipe.

- When the job is complete, navigate to the output Amazon S3The output file has the suffix
.out. For this post, the expected output file name isbatch-20-lines.json.outbecause the input file isbatch-20-lines.json.The following screenshot showsbatch-20-lines.json.outwritten to S3 and appearing in the S3 console.
- Download the file from Amazon S3.
- Open the file in a text editor.
The scores appear in the output. The old output schema without recommendation scores was as follows:
This new output schema with scores is as follows:
The following is the sample output from the *.out files. The output has been formatted for readability.
Summary
With the launch of recommendation scores, you now have finer-grained insights into the quality of their recommendations, and can write smarter business logic to integrate with your production systems downstream. Start personalizing your user experience today with Amazon Personalize! Click here for our developer guide.
About the Author
 Brandon Huang is a Software Development Engineer with AWS, working as a member of the Amazon Personalize development team. He specializes in training faster, more accurate models for recommendations, and previously worked on Amazon Forecast. When he’s not programming, Brandon enjoys badminton, piano, and exploring the Bay Area’s top-notch variety of restaurants.
Brandon Huang is a Software Development Engineer with AWS, working as a member of the Amazon Personalize development team. He specializes in training faster, more accurate models for recommendations, and previously worked on Amazon Forecast. When he’s not programming, Brandon enjoys badminton, piano, and exploring the Bay Area’s top-notch variety of restaurants.