亚马逊AWS官方博客
Amazon DeepRacer 多种策略模型实战应用分析
1. 概况
亚马逊云科技 DeepRacer 是第一款专门为帮助开发人员进行强化学习(Reinforcement learning)实践而开发的 1/18 比例的完全自动驾驶赛车。亚马逊云科技 DeepRacer 为开发人员提供了一种学习强化学习的简单方法,用新的强化学习算法和模拟到真实域传输方法进行实验,并在现实世界中体验强化学习。开发人员可以在线模拟器中训练、评估和调整强化学习模型,将他们的模型部署到亚马逊云科技 DeepRacer 上,从而获得现实世界的自动驾驶经验,并参加亚马逊云科技 DeepRacer League 的线下比赛。
强化学习(RL)已经被用来完成各种机器人任务,如操纵,移动,导航 ,互动,运动规划等。对于样本的复杂性和安全性要求较高的任务,在仿真环境训练强化学习模型可以减少训练时间,鼓励agent对于环境充分探索,之后将仿真模型转移到真实世界并使用真实世界的数据进行微调。下图是一个强化学习的简单示例,强化学习是机器学习中的一个领域,强调如何基于环境而行动,以取得最大化的预期利益。

对应到本次的 DeepRacer 比赛中,agent 使用的是限定的三层 CNN,Environment 是赛车前部的摄像头的图像,Action 为设计的 Action Space 中的速度和转向选择。在整个过程中,我们需要实现和可控制的主要包含三部分:
- Action Space:Action Space 包含两个量,速度及转向角度。其中速度的取值范围为(0,4), 转向角度的取值范围为(-30,30)。
- Reward Function:根据模拟平台提供的状态输入构造奖励函数供 Agent 学习。
- Model Type 和 Hyperparameter:Model Type 可选两种 PPO 与 SAC,Hyperparameter 里包含 Batch Size,Entropy,Discount factor 等
本篇blog基于DeepRacer的一次基于re:Invent2018赛道的备赛经历,阐述强化学习完成竞速类自动驾驶任务的算法调优与现实部署经验。
2. 背景
关于本次比赛的赛制如下,比赛分为线上赛和线下赛。先进行的是线上赛,线上赛是模拟赛,通过模拟线下的比赛环境,在 AWS 提供的 Deepracer race 控制台上提交训练好的模型,进行连续跑三圈的测试并获得成绩排名。之后进行的是线下赛,每组选择一个或两个训练好的模型导入 Deepracer car 中,在线下进行三圈的时间比拼。每出圈一次罚三秒,因此训练目标是尽量以更快的速度跑完三圈且不出圈。最终成绩以线下赛为准。
由于 Deepracer 比赛从 2018 年就开始了,本次比赛采用的也是经典的 re:Invent 2018 赛道,因此有大量的参考资料与模型。

在选择模型方面,我们主要参考了三部分资料,一部分是官网的 AWS DeepRacer Reward Function Examples,我们尝试并改进了其中的 Center Line 策略。一部分是 https://github.com/scottpletcher/deepracer ,我们尝试并改进了其中的 ”PurePursuit” 策略,另一部分是 https://github.com/dgnzlz/Capstone_AWS_DeepRacer ,这个策略针对赛道和 Action Space 进行了大量优化,我们也尝试了这种方法。
关于这三种方法的尝试及效果,我们将在下文中说明。
3. 实验
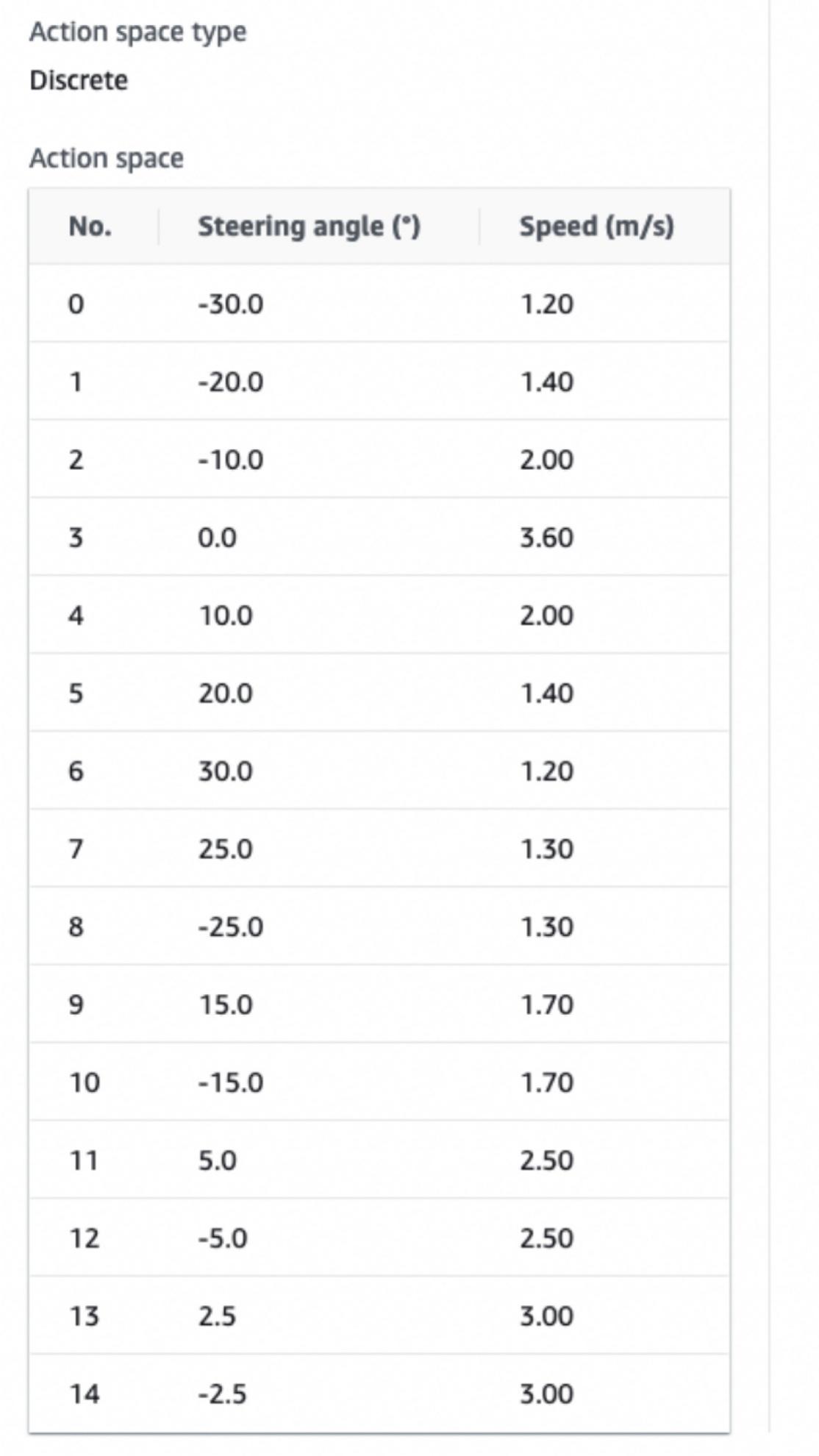
3.1 Action Space
Action Space 有连续性和离散型两种,连续型即我们只需要选取速度和转向角度的上下界,离散型则是我们需要对 Action Space 进行手动设定,如下是我们其中一个模型最终的 Action Space 的设置结果。

我们选取了离散型,主要原因是历史上基本上都是离散型的 Action Space 获得了比较好的效果。猜想的一个连续型的问题是模型在使用的 Reward Function 策略不正确的情况下更容易过拟合,更有可能过度适应模拟环境,而如果各种参数和模型选取都很合适,可能需要很长的时间才可以让模型收敛。考虑到模拟环境只是线下环境的一个很粗糙的近似,连续型 Action Space 要达到一个比较好的成绩可能需要做很多的工作。
我们在设定 Action Space 的时候,主要参考了场地情况,场地有一个很大的需要左转的弯,所以我们需要设定能左转很大的 Action,另外在走直线的时候我们希望车可以尽量快速,所以在 0 度的位置,我们设了一个较大的速度。
在另一个策略里,我们没有针对赛道左转较多而作优化,而是考虑到速度与转弯在车辆行驶过程中的不完全独立,为了简化 Action Space,我们做了在同一个转弯角度上只有单一速度的设定。
3.2 Reward Function 设计
这里主要介绍下我们实验的三种不同的策略模型,分别是中线策略,PurePursuit 策略和 Capstone 策略。
3.2.1 中线策略
中线策略,顾名思义,就是尽量让车开在中线附近,这个方式的好处是车出圈的概率比较低,能够尽量不被出圈罚秒。
设计的 reward function 主要参考了 AWS DeepRacer Reward Function Examples 的 Example 1,整体思想是:用车与中线的距离和行驶过程中转弯的角度两个条件来决定 reward。1. 车开的离中线越近,给的 reward 越高;反之越低。2. 让车在行驶中尽可能平滑地前进,希望车在做转弯决策的时角度尽可能的小,所以当车的转弯方向角度比较大的时候,我们也会给他更大的惩罚。
整体来说,这个策略在线上模拟的效果还是很好的,第一版训练时就可以收敛到测试时 100% 跑完一圈,且整体相对平稳。
效果图:

但这个策略在线下环境中未能完成任务。我们猜测最主要的原因是训练的模型过拟合了,因为我们选取的是一个已经训练了 12h 的模型,在完整跑完测试赛道之后还进行了很多轮训练。过拟合很可能是大多数队伍最终线下效果不及预期的一个最重要原因,后面我们还将花一些篇幅介绍我们对过拟合问题的理解。
3.2.2 PurePursuit 策略
我们在实际开车的时候,通过会以远方的某个位置为参照来做加减速和转向的操作,而不会看自己的车离路两边或中线有多远,这个策略就是一个对真实开车的模拟。赛道被划分为了很多的 waypoints,车在行驶过程中,对车到最近的 waypoint 的连线与车当前行进方向间的关系进行比较,来调整车的动作选取。

这个模型也是相对较快的可以实现收敛,大概在 3h 左右就可以达到测试时 100% 跑完一圈的效果,运行完成后通过调整 Action 的 Speed 也能实现比较好的加速效果。
但在模拟时候的一个问题是,在走直线的时候经常会走出 Z 字形,这可能是因为我们设置的 Action Space 中转向角过大,且策略上只看着下一个 waypoint,所以当车在直线上发现自己离下一个 waypoint 的角度差距比较大的时候,就会做一个大幅度转向,因为很难完美的转到中线上,所以会出现沿着中线附近的 Z 字形震荡。
针对这个问题,我们对直线方向进行了单独的优化,当我们判断前面一段路是直线的时候,我们不再以最近的一个 waypoint 作为参考点校正车辆,而以更远的点作为参考,并且将一些使用次数很少的 Action 修正为转向角较小的 Action,从而实现在走直线时候的微调。 在上线这个修正之后,车在走直线的 Z 字形问题获得了一定的改善。
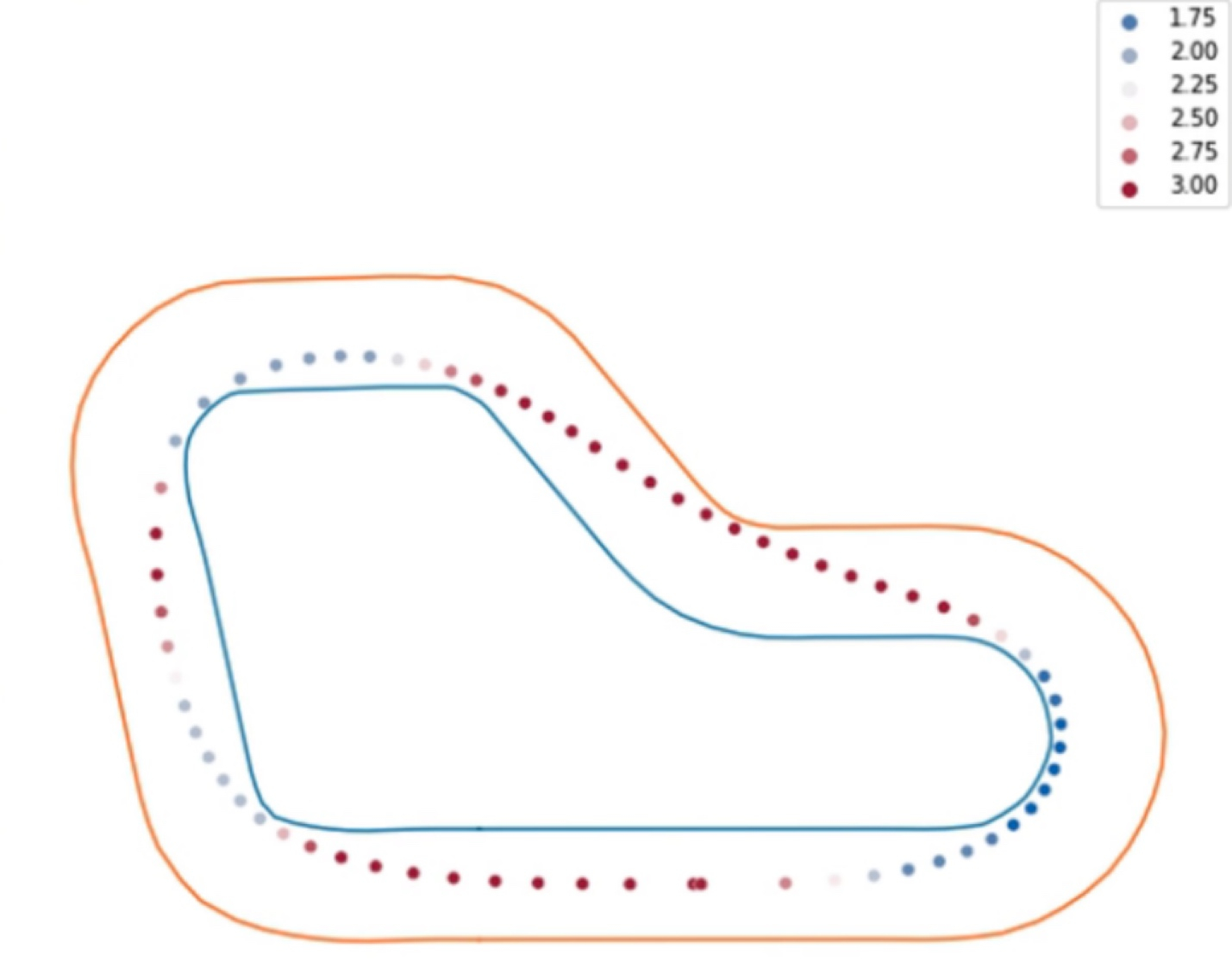
另一个策略类似的方法是我们不去参考 waypoint,而是设定一个固定的距离作为一个参考点,在直线的时候我们将这个距离设的远一些,当判断前面是弯道时我们设置的近一些。具体的判定方式是采用 1 倍,1.5 倍与2 倍于固定距离找前方的中线焦点,并通过此三条射线的夹角来决定具体选择哪个点作为目标点。通过这个方式也实现了一个较好的实验效果,示意图如下。

最终线下比赛的时候选取了基于这个策略的两个模型。我们选取这个模型的原因也是这两个模型在我们看来可能更符合线下的实际场景,因为我们通过这个方式训练时并没有给太多车可能不知道的环境信息,过拟合的可能性更低。
3.2.3 Capstone 策略
这个策略是一个看上去相对极端的策略,提供了一种通过数学模拟的方式找到最优解的思路。细节方面可以参考:https://github.com/dgnzlz/Capstone_AWS_DeepRacer
我们基本复现了这些实验,该策略主要通过对赛道路径进行优化,找到小车应该行驶的最佳路径和最佳速度。并根据选定的赛道计算出速度和转弯角度的分布,并依此优化对应的action space,然后尽可能让小车按照预定方式去跑。
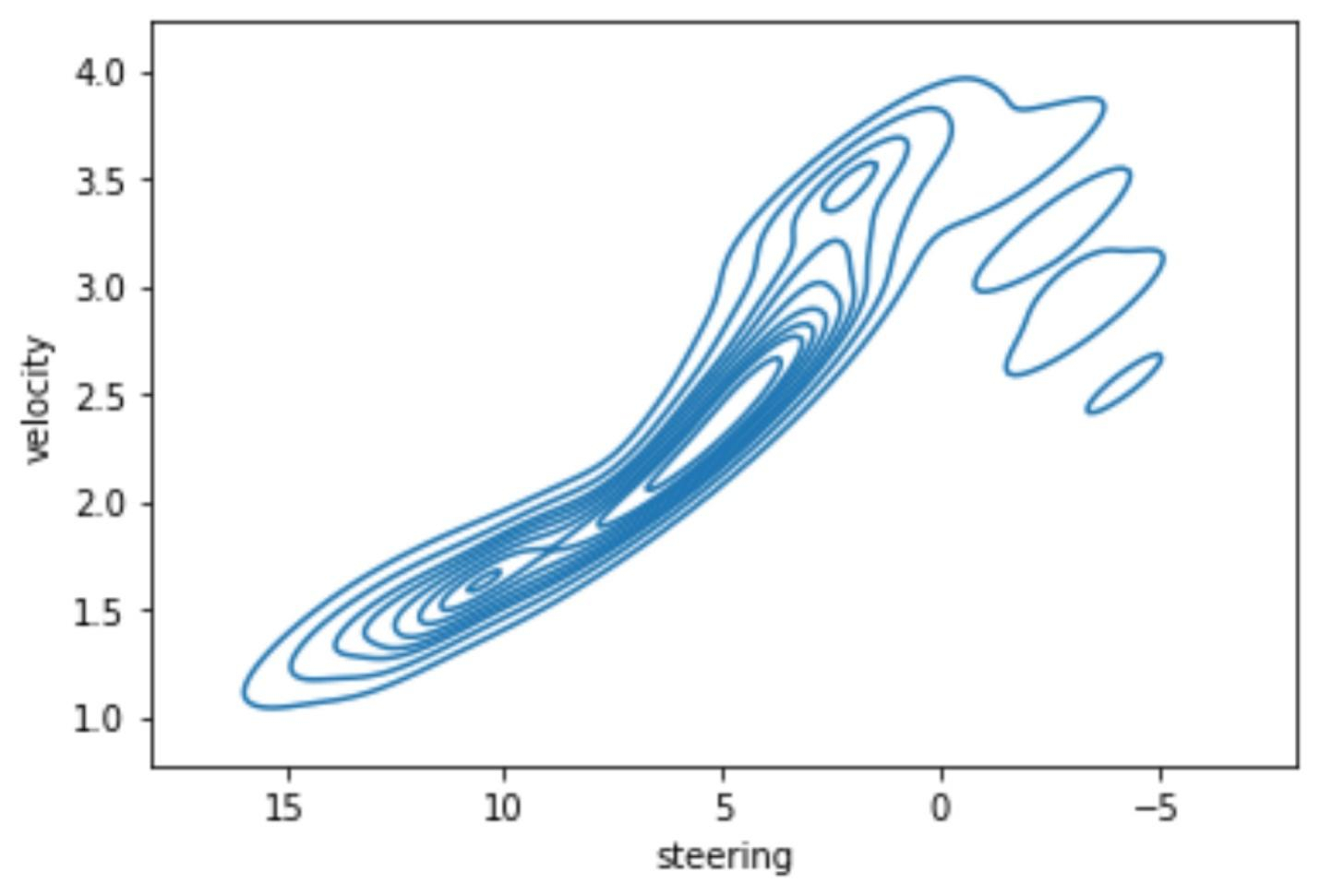
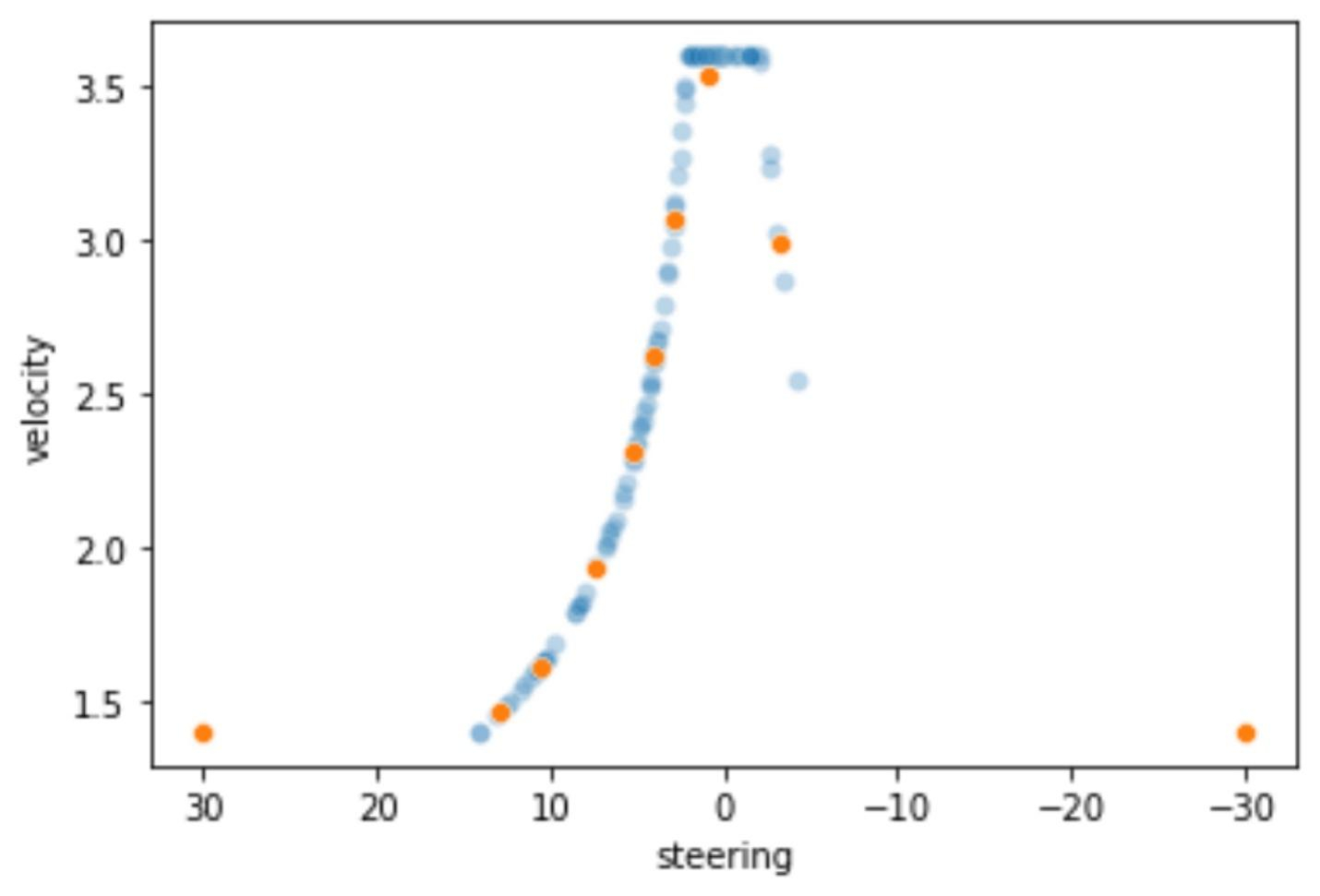
这个策略我们在线上模拟实验的时候同样存在在第一个左转大弯后的右转弯容易offtrack的情况,主要原因猜想是仅通过 Reward Function 很难实现如此精准的控制。即使最终实现,该模型也极大可能过拟合,无法适应线下的场景。
3.3 过拟合
在上述过程中,不难发现过拟合是线下赛中影响模型performance的一个重要因素。由于线上是模拟环境,当我们针对这个模拟环境反复训练的时候,很容易出现针对该场景的过拟合的情况,从而无法在线下获得较好成绩。
参考官网的说法,如果Reward Function 中包含了大量的环境信息,那么更容易出现过拟合。如上面的 Capstone 策略,小车在线下运行的时候,当它在走下方直线的时候它是不应该根据左上方的弯道来调整策略的,但当你设置了不当参数(如 Discount factor 一直设的非常大)或者反复训练很多次的情况时,可能就会出现这样过度利用环境信息的情况。
线上的模拟只是针对物理环境的一个粗糙近似,真实的物理运行受限于场地光线,小车动力,赛道平整度等各种问题。在模拟实验中的大多数队伍的成绩都远好于线下成绩,也是模型很容易过拟合的一个佐证。
另外一点关于过拟合需要注意的是在 Reward 已经不再提升的时候不要训练过长的时间,因为 Reward 不再提升标志着模型已经并没有超预期的方向在进行优化,模型只是在根据这一次模拟的环境修改了一些参数以更加适应模拟环境。当 Reward Function 的设计较为复杂的时候,在每次测试都已经可以 100% 跑完的情况下,即使 Reward 继续提升,也有可能已经过拟合。上面提到的中线策略就出现了这样的问题。

关于消除过拟合,首先应该多进行试验,发现大量线上线下不一致的情况。针对不一致的情况,回溯训练日志进行行车轨迹,reward function, action 分析,分析脚本可以参考https://github.com/TheRayG/deepracer-log-analysis/blob/master/DeepRacerLogAnalysis_Training.ipynb与 https://aws.amazon.com/cn/blogs/china/deepracer-training-log-analysis-example-and-reinforcement-learning-reward-function-design/。根据分析结果确认是否需要进行reward function与action space的调整,此外,如果模型已经陷入局部最优,提升hyperparameter中的entropy可以增加随机性,促进模型重新探索环境。
4. 比赛
4.1 校准
线下比赛的时候,AWS 的团队开始已经对车辆进行了校准。但在测试跑的时候看到前面的团队大部分都是跑不起来或者跑的很慢,我们猜想如果有些模型在 Action Space 设置的速度比较大的情况下,实际跑的比较慢,将会出现在实际比赛的时候无法复现线上模拟的欠拟合情况,于是我们在测试的时候就将速度动力调整的比较大。
实际测试时,基于 “PurePursuit 策略“ 的两个模型都跑的还不错,是很少的可以在赛道上完整跑完的模型。
4.2 策略
赛前,由于对物理环境中什么样的模型更加合适不太确定,我们分别准备了 “激进” 和 “稳妥” 的两类模型。比赛选取两轮的最好成绩作为最终成绩,首轮我们选取了测试时候表现较好的 “稳妥” 模型,最终获得了 44s 的成绩,排名首轮第一。
在第二轮比赛中,由于我们抽到的是第五位出场,跟我们有竞争关系的分别在第三位和第四位出场,因此我们可以比较从容的选择策略,如果前面跑的很好,我们就设置更大的动力。但后一轮另两队的成绩都没有超过我们的首轮成绩,因而我们对 “激进” 模型只设置了一个中等的动力,最终跑出了 38.74s 的成绩,成为了当天的冠军模型。
比赛之后的表演赛中,我们发现将 “激进” 模型设置更大动能,是有可能获得更好成绩的,90% 最大物理速度情况下,跑到了 34s,即使加上出圈一次的罚秒,也可以跑到 37s 的好成绩。

5.结论
在这篇blog中,我们使用AWS DeepRacer讨论基于强化学习进行自动驾驶任务的超参调节,动作空间选择,reward function策略,以及过拟合对于线下赛结果影响。AWS DeepRacer为您提供了一种开始强化学习 (RL) 的有趣方式。同时,我们欢迎大家参加AWS DeepRacer League,它是机器学习推动技术的世界上首个全球自动驾驶赛车联赛。立即参加比赛,赢得奖金和荣誉,并有机会晋级到 AWS DeepRacer 锦标赛。全球各地各技能级别的开发人员都可以逐梦赛道,在线参加比赛,您的机器学习技能也会大有长进!
6. 参考
- DeepRacer: Educational Autonomous Racing Platform for Experimentation with Sim2Real Reinforcement Learning
- AWS DeepRacer Action Space and Reward Function
- Optimizing the cost of training AWS DeepRacer reinforcement learning models
- AWS DeepRacer Reward Function Examples
- https://github.com/scottpletcher/deepracer
- https://github.com/dgnzlz/Capstone_AWS_DeepRacer
- https://www.youtube.com/watch?v=qOEqW-xTClE
- https://github.com/TheRayG/deepracer-log-analysis/blob/master/DeepRacerLogAnalysis_Training.ipynb