AWS Database Blog
How Autodesk Increased Database Scalability and Reduced Replication Lag with Amazon Aurora
Autodesk is a leader in 3D design, engineering, and entertainment software. Autodesk makes software for people who make things. If you’ve ever driven a high-performance car, admired a towering skyscraper, used a smartphone, or watched a great film, chances are you’ve experienced what millions of Autodesk customers are doing with their software.
Autodesk has successfully migrated to Amazon Aurora from both managed MySQL databases running on Amazon RDS and self-managed MySQL databases hosted on Amazon EC2. This blog post summarizes the experience and covers:
- Factors that influenced Autodesk’s decision to move to Amazon Aurora
- Specific migration benefits
- Best practices and lessons learned for migration and optimization
We start off by reviewing the migration path for the Autodesk Access Control Management (ACM) application, which was born in the cloud. We chose Amazon RDS for MySQL at onset and migrated to Aurora for improved scalability, availability, and performance. ACM’s success with the migration motivated several other applications at Autodesk to migrate to Aurora. We discuss BIM 360 Field Classic as a leading example of migrating self-managed MySQL database hosted on EC2 to Amazon Aurora.
ACM application architecture and challenges with MySQL
The following diagram provides a high-level schematic of ACM’s initial architecture. The application tier consists of EC2 instances across multiple Availability Zones to maintain high availability. Traffic is distributed using the Elastic Load Balancing service. Additionally, EC2 Auto Scaling is employed to adjust the number of EC2 instances to handle spiky traffic to the application.
Although this architecture allowed Autodesk to scale and load-balance the application, the bottleneck soon shifted to the database. The application connected to a single RDS MySQL database instance, limiting the available scaling options. One approach was to increase the size of the database instance. This approach was still constrained by the maximum size of database instances that could be provisioned. ACM soon outgrew the capacity limits of the largest available instance.
The next option was to horizontally scale database capacity by adding RDS Read Replica instances for offloading reads from the primary instance. Autodesk wanted to keep the replication lag below a second to provide a consistent experience to all ACM users. The replication lag associated with Read Replicas depends on workload pressure on the primary and read replica instance. (Replication lag here is the time taken for effects of a write operation to become visible on the Read Replica.)
Short of rearchitecting ACM by splitting the data across multiple MySQL databases, Autodesk had to throttle the application to limit the load directed at the database to minimize the replication lag. This approach was not sustainable because ACM adoption was severely curtailed by the limits imposed. This effect led Autodesk to evaluate alternatives, such as Amazon Aurora.
Amazon Aurora to the rescue
Some of the key priorities as Autodesk started evaluating Aurora were these:
- Performance enhancement
- Low-lag replication for read scaling
- Full MySQL compatibility (lift-and-shift migration)
- Automated storage scaling
Aurora provides up to five times the throughput of standard MySQL databases. This performance boost meant Autodesk could remove throttling restrictions introduced with MySQL without altering the application and still have enough headroom for future growth. The distributed, fault-tolerant, self-healing storage system that Aurora provides automatically scales up to 64 terabytes and eliminates the need to scale database storage manually. Up to 15 low-latency Aurora Replicas improve availability and enable read scaling with typical replication lags under 100 milliseconds.
Autodesk used Aurora Replicas to offload reads from the primary instance and scale reads horizontally. Additionally, with fast cloning, point-in-time recovery, continuous backup to Amazon S3, and replication across three Availability Zones, Aurora enabled Autodesk to reduce operational overheads further.
The following diagram shows ACM application architecture after migration to Aurora.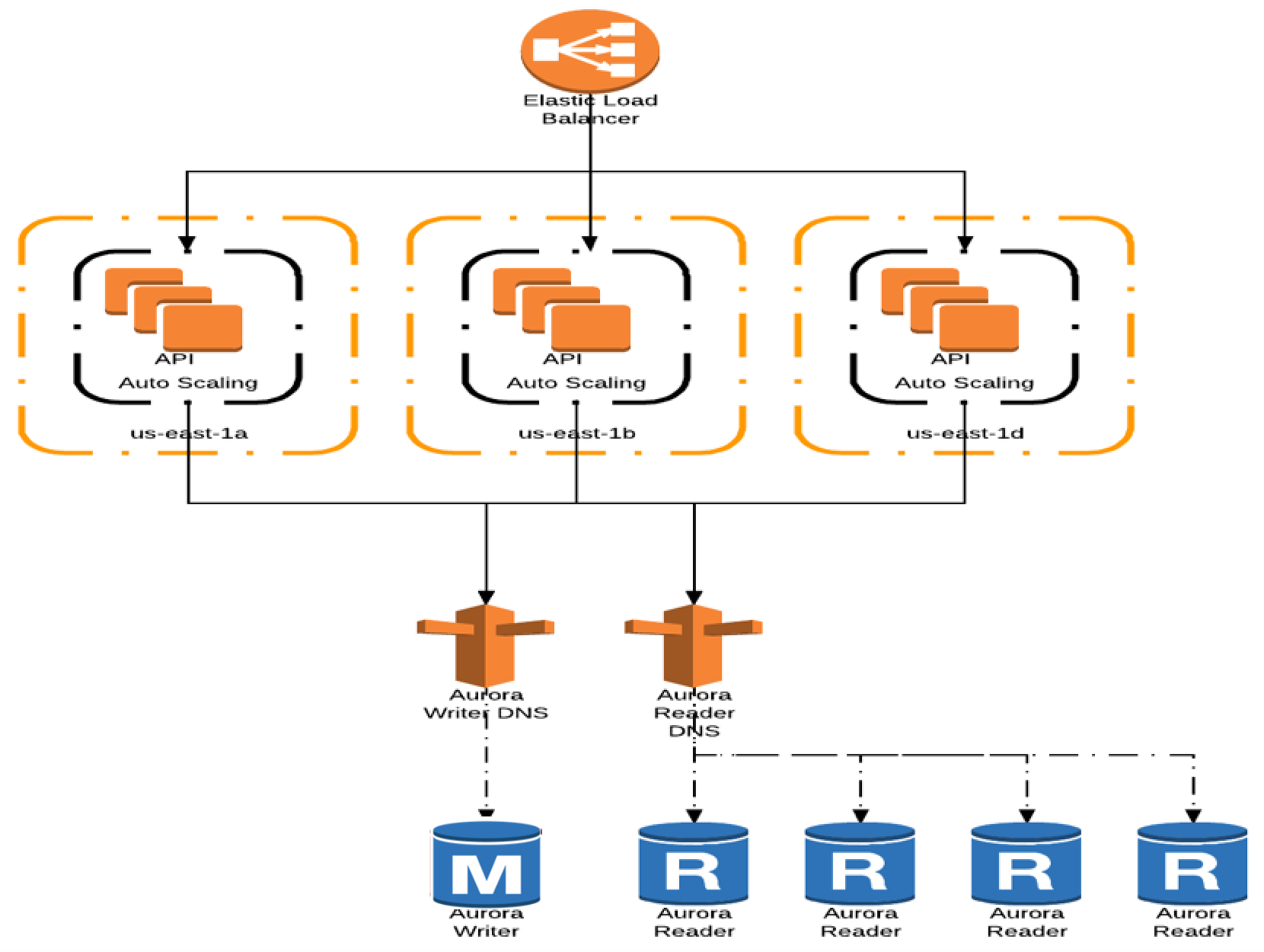
In this architecture, the Aurora cluster includes one writer instance and up to four Aurora Replicas. Aurora Auto Scaling was enabled to automatically adjust the number of Aurora Replicas based on CPU utilization.
The performance of the database surpassed expectations after migration to Aurora. Autodesk observed a 20x improvement in application scalability, application response time was improved by 2x, and Aurora could support 7x more database connections. The highlight of the migration was the 10x reduction in CPU utilization on a similar-sized database instance, leaving enough headroom for the database to grow as ACM scales. We have captured a few comparative charts between MySQL and Amazon Aurora before and after migration that underscore these improvements.
Autodesk achieved 10x reduction in CPU utilization, from peaks reaching 100% with MySQL to less than 10% with Amazon Aurora. The following charts show the before and after CPU utilization.

MySQL

Aurora
The following charts show the before and after application response times.
Autodesk gained 2x improvement in response time.

MySQL

Aurora
Let’s dive deeper into the migration process and lessons learned.
Migration best practices and lessons learned
Autodesk engaged AWS Professional Service to support the migration to Amazon Aurora. Following is a summary of all considerations and best practices categorized by five pillars of the AWS Well-Architected framework:
Reliability
- Test and verify: We performed load tests in the staging environment with 5x the usual traffic with one Aurora writer and four Aurora Replicas to affirm performance gains and ensure future scalability. The test results confirmed that CPU utilization was below 10% even under sustained loads. Application latency requirements were also exceeded. Aurora supports up to 15 Aurora Replicas on an Aurora cluster. Because we are only using up to four Aurora Replicas, we have sufficient headroom to scale reads by adding additional Aurora Replicas. Aurora can automatically scale storage up to 64 terabytes. ACM database measures around 1 terabyte, leaving enough room for storage growth.
- Multi-AZ deployment: To improve availability and fast automated failovers, we created Aurora Replicas in different Availability Zones (AZs). The Aurora Replicas serve two purposes: first as failover targets for the primary instance, and second to offload low-latency reads because they share the same storage with the primary instance. We set up a failover priority for each Aurora Replica to specify the order Aurora Replicas get promoted if the primary instance becomes unavailable. Aurora storage maintains six copies of data in three Availability Zones and is distributed across hundreds of storage nodes. This functionality helps ensure full read-write availability even in an unlikely loss of connectivity to an entire AZ.
- Spread the load: Connecting to the reader endpoint allows Aurora to load-balance connections across the replicas in the DB cluster. This approach helps spread the read workload around and can lead to better performance and more equitable use of resources available to each replica. The ACM database workload was read-heavy, with approximately 90% of the workloads consisting of reads. Configuring four Aurora Replicas allowed us to offload and distribute read workloads to the replicas. At the same time, we increased the connection pool size in the application to better use Aurora Replicas.
- Coexistence during the migration: During the initial migration, we also set up replication between Aurora and RDS MySQL for a safe rollback. A week after successful production cutover, we gained sufficient confidence and decided that we no longer required the fallback environment and terminated the replication at that point. MySQL binlog-based replication is performance-intensive and can cause write performance degradation. We recommend turning off binlog unless it is required for operational reasons.
- Durability and disaster recovery (DR): Aurora maintains six copies of data across three Availability Zones and continuously backs up data in S3. For DR, we added a cross-region read replica Aurora cluster in another AWS Region and simulated disaster recovery drills in the staging environment to help ensure operational readiness for large-scale disasters.
Performance efficiency
- Right sizing: We executed load tests with different instance types and picked r3.8xlarge for the optimal cost to performance benefit. We also benchmarked the load test results against MySQL to get a sense of performance improvements achieved with the Aurora migration. Instead of overprovisioning the primary instance to serve both writes and reads, we sized the primary instances to serve writes predominantly. Aurora Replicas were added to scale out read performance.
- Optional optimizations: Although it’s not usually required, you can optimize your query execution by working with available MySQL parameters. For example, we increased the query cache size to gain performance on repeat reads. We also monitored long-running queries and reduced transaction lengths. To find MySQL parameter details, see the MySQL Reference Manual.
Operational excellence
- Performance optimization: We enabled enhanced monitoring for the Aurora cluster at 5-second intervals and looked for long-running queries. Additionally, we scheduled a weekly job to analyze tables and gather new statistics. Doing this allowed us to improve transaction processing times and reduce long-running queries.
- Continuous monitoring: We created dashboards for Amazon CloudWatch to maintain visibility into key metrics of the Aurora clusters and also metrics for the application. By default, the AuroraReplicaLag metric, which represents the replication lag value between the primary instance and Aurora Replicas, is published to CloudWatch every minute. We configured a custom CloudWatch metric for gathering this value every second to maintain more granular visibility into replication lag. We also created event subscriptions and alarms for key metrics such as CPU utilization, memory utilization, DML and DDL query latencies and throughputs, and buffer cache hit ratio. In addition, we set up automatic event notifications to responsible groups using Amazon SNS.
- Build automation: We employed AWS CloudFormation templates to provision Aurora clusters and auto-scaling Aurora Replicas. This considerably reduced the time to provision a new stack. Building on top of this automation, we deployed a blue-green architecture for zero-downtime upgrades and release management.
Security
We set up the Aurora cluster in the Amazon VPC service and configured security groups to isolate access to the Aurora cluster. Encryption was enabled in Aurora to secure data at rest. When encryption is enabled on Aurora, backups and snapshots are encrypted automatically. Additionally, we configured the application to use Secure Socket Layer (SSL) connection with Aurora instances.
Cost optimization
Due to the uncertainty of the application load on the new environment, we decided to over-provision the Aurora cluster with four r3.8xlarge Aurora Replicas. After successful migration, we continued to monitor the database performance and utilization using CloudWatch metrics. When we had adequate confidence in the new system’s stability, we used the collected metrics to right-size the environment. As part of this, we configured Aurora based on CPU utilization to optimize utilization for Aurora Replicas. Today, depending on workload, our Aurora cluster consists of one primary instance and can scale up to four Aurora Replica instances.
What’s next?
With the successful Autodesk ACM database migration and the significant performance improvements post-migration, Autodesk has started to adopt Amazon Aurora across multiple applications. The migration work carried out by the BIM 360 Field team is a great example of a migrating a self-managed MySQL database to Amazon Aurora.
BIM 360 Field Classic
Following the success of the ACM migration, Autodesk engaged AWS Professional Services to perform another migration. In this, we migrated a self-managed six-node MySQL setup hosted on Amazon EC2 for the BIM 360 Field Classic application to Amazon Aurora. The MySQL setup had one master writer and five read replicas. We evaluated the BIM 360 Field environment with the following findings:
- The AWS BIM 360 Field application database holds around 2 terabytes of data.
- High availability and failover are managed through the middleware layer sitting in between the application and the database.
- The failover application is hosted on EC2.
- Aurora Replicas are connected with the master through MySQL binlog-based replication and also act as failover targets to achieve failovers in 10 seconds or less.
- The application manually routes the queries to all the five nodes based on the port numbers that each of the replicas are configured to.
- The backup is configured through daily Percona XtraBackup and MySQLDump script runs. An EC2 instance–level snapshot is also scripted for instance level recovery.
Although this configuration worked for BIM 360 Field Classic, Autodesk still had to manage a wide area from the EC2 instance-level backup to the database backups. As part of that, it was important to ensure high availability of the database and implement failover application disaster recovery strategies. Similarly, Autodesk needed to manage application code to load balance queries and to maintain data integrity for logical binlog replication. Although these operations are feasible, they don’t scale well and require considerable resources and planning. We automated and simplified high availability, failover, and load balancing mechanisms by migrating to Amazon Aurora, which supports these capabilities out of the box.
Migration to Aurora
We evaluated different migration approaches from the Amazon Aurora Migration Handbook and chose the logical backup approach using the open-source tool Mydumper for this migration. Migrations are sped up by parallelizing the overall data transfer process with the r4.16xlarge instances.
To further optimize the cost and to meet the additional requirements of several Autodesk applications, we did the following:
- Enabled Aurora Auto Scaling to automatically adjust the number of Aurora Replicas based on CPU utilization. Instead of continuously running multiple replicas, we are saving costs by adding replicas when needed.
- Deployed the Snapshot tool for Aurora for all the Aurora clusters to automate the copy of the snapshot across AWS Regions and implementing Aurora snapshot retentions beyond 35 days. We did this to meet Autodesk’s requirements on both recovery point objective (RPO) and recovery time objective (RTO). The Snapshot tool uses several AWS services within the AWS ecosystem, such as AWS Lambda and AWS Step Functions, to automate the snapshot copy process across AWS Regions and accounts.
- Enabled CloudWatch Logs for the Amazon Aurora Audit events to publish audit logs to CloudWatch Logs and to create CloudWatch metrics and alarms to monitor activity in Aurora DB clusters continuously.
Conclusion
With Amazon Aurora, both ACM and BIM 360 Field Classic applications were able to improve scalability, increase application performance, reduce management overhead, and optimize cost.
“ACM database is approximately one terabyte in size, with a few tables going beyond a billion rows. We get up to 25 to 30 thousand requests per minute during our peak hours,” said Krishna Kumar, senior engineering manager at Autodesk. “We are building a strategy to handle 100X growth for our applications. We definitely see Aurora as a big part of the ACM roadmap and feel Aurora can buy us capabilities to solve these scaling challenges.”
ACM’s successful migration to Aurora gave overall direction to multiple Autodesk teams to use the higher performance, scalability, and availability of Aurora. Autodesk formalized a migration strategy to Aurora and is actively working on moving multiple application stacks to start using Aurora, with BIM 360 Field Classic as the most recent example.
About the Authors
 Piyush Patel is a senior big data consultant at AWS Professional Services. He works with customers to provide guidance and technical assistance about big data and analytics projects, helping them improving the value of their solutions when using AWS.
Piyush Patel is a senior big data consultant at AWS Professional Services. He works with customers to provide guidance and technical assistance about big data and analytics projects, helping them improving the value of their solutions when using AWS.
 Akm Raziul Islam is a consultant with a focus on Database and Analytics at Amazon Web Services. He works with customers to provide guidance and technical assistance about various database and analytical projects, helping them improving the value of their solutions when using AWS.
Akm Raziul Islam is a consultant with a focus on Database and Analytics at Amazon Web Services. He works with customers to provide guidance and technical assistance about various database and analytical projects, helping them improving the value of their solutions when using AWS.
 Chayan Biswas is a product manager at Amazon Web Services.
Chayan Biswas is a product manager at Amazon Web Services.
 Krishna Kumar is senior engineering manager responsible for several of core foundational cloud services at Autodesk. He has built and led teams on multiple technology and domain fronts over the years. He is passionate about building highly scalable applications with dependable stability and performance.
Krishna Kumar is senior engineering manager responsible for several of core foundational cloud services at Autodesk. He has built and led teams on multiple technology and domain fronts over the years. He is passionate about building highly scalable applications with dependable stability and performance.