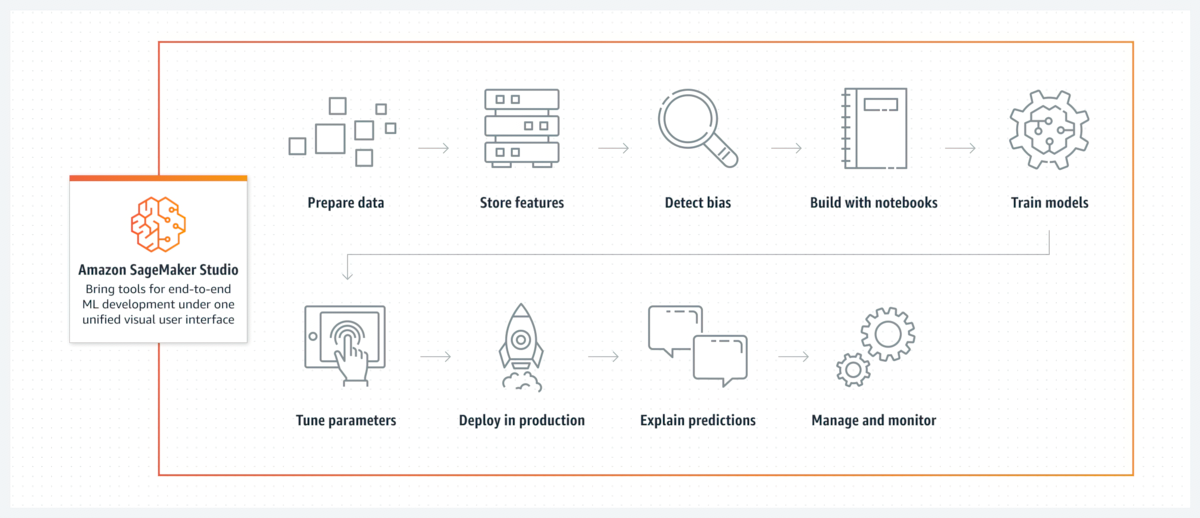
为什么使用 SageMaker Studio?
Amazon SageMaker Studio 提供多种专门构建的工具来执行所有机器学习(ML)开发步骤,从准备数据到构建、训练、部署和管理机器学习模型。您可以使用首选 IDE 快速上传数据并构建模型。简化机器学习团队协作,使用人工智能驱动型编程辅助工具高效编码,调整和调试模型,在生产环境中部署和管理模型,实现工作流程自动化,所有这些都在一个统一的 Web 界面中完成。
工作原理
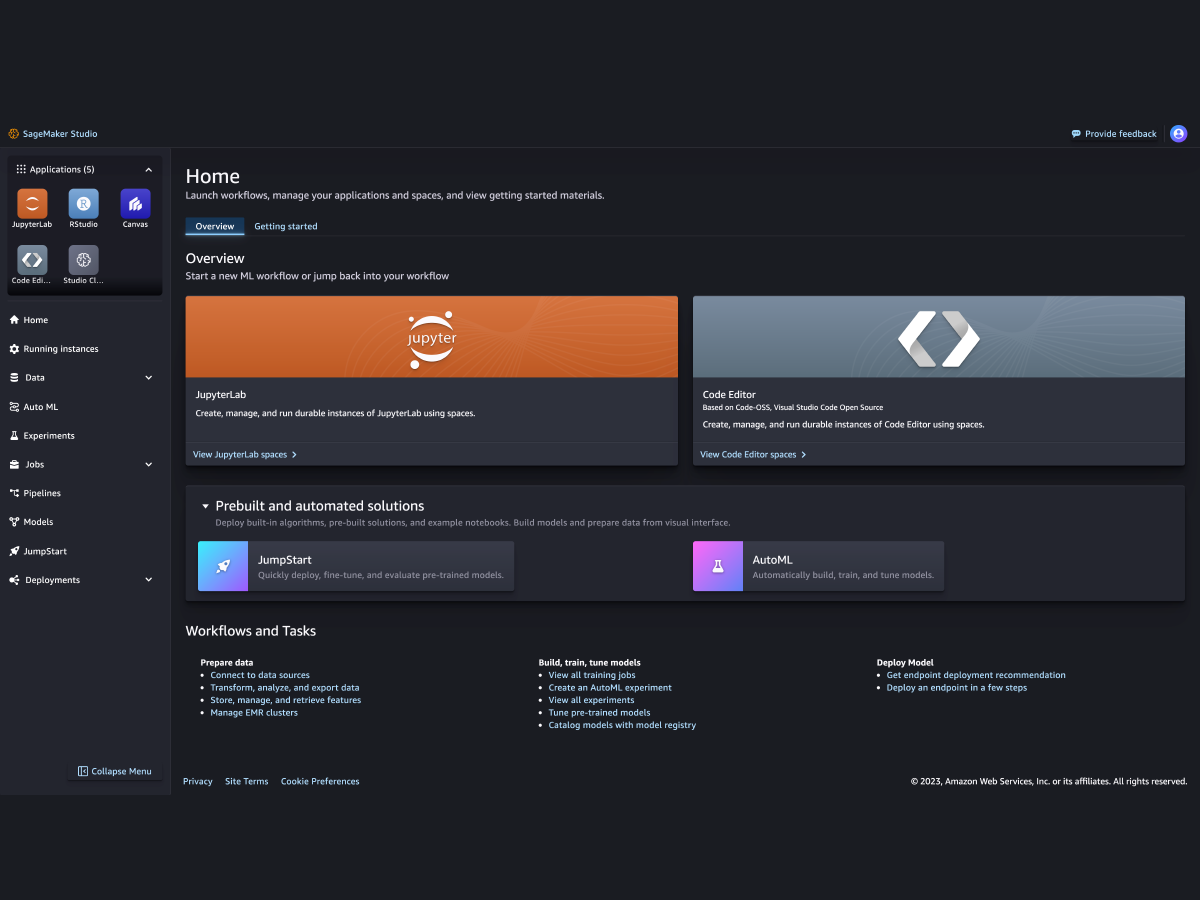
Amazon SageMaker Studio 是一个集成式开发环境(IDE),它提供了一个基于 Web 的可视化界面,您可以在其中访问专用工具来执行从准备数据到构建、训练和部署 ML 模型的所有机器学习 (ML) 开发步骤。您可以快速上传数据、创建新笔记本、训练和调优模型,在步骤之间来回切换以调整实验,以及在不离开 SageMaker Studio 的情况下将模型部署到生产环境中。它使您能够快速切换环境并在组织内无缝协作,以大规模构建机器学习模型。