Ein Machine-Learning-Modell mit Amazon SageMaker erstellen, trainieren und bereitstellen
TUTORIAL
Einführung
In diesem Tutorial lernen Sie, wie Sie mit Amazon SageMaker ein Modell für Machine Learning (ML) unter Verwendung des ML-Algorithmus XGBoost erstellen, trainieren und einsetzen. Amazon SageMaker ist ein vollständig verwalteter Service, der jedem Entwickler und Daten-Wissenschaftler die Möglichkeit bietet, ML-Modelle schnell zu erstellen, zu trainieren und zu implementieren.
Die Entwicklung eines ML-Modells vom Konzept zum Produktiveinsatz ist in der Regel komplex und zeitaufwändig. Wenn Sie große Datenmengen verwalten müssen, um das Modell zu trainieren, müssen Sie den für das Training am besten geeigneten Algorithmus auswählen, während des Trainings die Datenverarbeitungsleistung optimieren und anschließend das Modell in einer Produktivumgebung bereitstellen. Mit Amazon SageMaker werden diese komplexen Abläufe vereinfacht, sodass ML-Modelle mit deutlich geringerem Aufwand erstellt und bereitgestellt werden können. Nachdem Sie aus der breiten Palette verfügbarer Lösungen die für Ihre Zwecke am besten geeigneten Algorithmen und Frameworks ausgewählt haben, übernimmt SageMaker die Verwaltung der zugrunde liegenden Infrastruktur, um das Modell mit Petabytes an Daten zu trainieren und in der Produktivumgebung bereitzustellen.
In diesem Tutorial übernehmen Sie die Rolle eines Machine-Learning-Entwicklers, der für eine Bank tätig ist. Sie wurden gebeten, ein Machine-Learning-Modell zu entwickeln, mit dem vorhergesagt werden kann, ob ein Kunde ein Einlagenzertifikat zeichnen wird.
In diesem Tutorial lernen Sie Folgendes:
- Eine Notebook-Instance für Amazon SageMaker erstellen
- Die Daten vorbereiten
- Das Modell anhand der Daten trainieren
- Das Modell bereitstellen
- Die Leistung Ihres ML-Modells beurteilen
Zum Trainieren des Modells wird der Marketingdatensatz der Bank verwendet, der Informationen zur Demographie des Kunden, seine Reaktionen auf Marketinginitiativen und externe Faktoren enthält. Die Daten wurden für Sie bereits mit Kennzeichnungen versehen und in einer Spalte im Datensatz ist angegeben, ob der Kunde bereits ein von der Bank angebotenes Produkt gezeichnet hat. Eine Version dieses Datensatzes ist in dem von der University of California in Irvine (USA) zusammengestellten Machine-Learning-Repository öffentlich verfügbar.
Die in diesem Tutorial erstellten und verwendeten Ressourcen können im Rahmen des kostenlosen AWS-Kontingents genutzt werden. Die Kosten für diesen Workshop betragen weniger als 1 USD.
Erfahrung mit AWS
Einsteiger
Benötigte Zeit
10 Minuten
Veranschlagte Kosten
Weniger als 1 USD. Für kostenloses Kontingent qualifiziert.
Erfordert
- AWS-Konto
- Empfohlener Browser: aktuelle Version von Chrome oder Firefox
[**] Innerhalb der letzten 24 Stunden erstellte Konten haben möglicherweise noch keinen Zugriff auf alle für dieses Tutorial erforderlichen Services.
Verwendete Services
Letzte Aktualisierung
23. August 2022
Bevor Sie beginnen
Sie benötigen ein AWS-Konto, um dieses Tutorial abschließen zu können. Wenn Sie noch kein Konto haben, klicken Sie auf Registrieren bei AWS und erstellen Sie ein neues Konto.
Sie haben bereits ein Konto?
Melden Sie sich bei Ihrem AWS-Konto an.
Schritt 1: Eine Notebook-Instance für Amazon SageMaker erstellen
In diesem Schritt erstellen Sie die Notebook-Instance, die Sie zum Herunterladen und Verarbeiten Ihrer Daten verwenden. Im Rahmen des Erstellungsprozesses erstellen Sie auch eine Rolle für Identity and Access Management (IAM), mit der Amazon SageMaker auf Daten in Amazon Simple Storage Service (Amazon S3) zugreifen kann.
a. Melden Sie sich bei der Amazon-SageMaker-Konsole an und wählen Sie in der oberen rechten Ecke Ihre bevorzugte AWS-Region aus. In diesem Tutorial wird die Region USA West (Oregon) verwendet.

b. Wählen Sie im linken Navigationsbereich Notebook-Instances und anschließend Notebook-Instance erstellen aus.

c. Füllen Sie auf der Seite Notebook-Instance erstellen im Feld Einstellungen der Notebook-Instance die folgenden Felder aus:
- Geben Sie als Name der Notebook-Instance SageMaker-Tutorial ein.
- Als Notebook-Instance-Typ wählen Sie ml.t2.medium aus.
- Behalten Sie für Elastische Inferenz die Standardauswahl Keine bei.
- Behalten Sie für Plattformkennung die Standardauswahl bei.

d. Wählen Sie im Abschnitt Berechtigungen und Verschlüsselung für IAM-Rolle Eine neue Rolle erstellen , im Dialogfeld zu Eine IAM-Rolle erstellen Einen beliebigen S3-Bucket und anschließend Rolle erstellen aus.
Hinweis: Falls Sie bereits über einen Bucket verfügen, den Sie verwenden möchten, wählen Sie Spezifische S3-Buckets aus und geben Sie den Namen des Buckets an.

Amazon SageMaker erstellt die Rolle AmazonSageMaker-ExecutionRole-***.

e. Behalten Sie für die anderen Optionen die Standardeinstellungen bei und klicken Sie auf Notebook-Instance erstellen.
Im Bereich Notebook-Instances wird die neu angelegte Notebook-Instance SageMaker-Tutorial mit dem Status Ausstehend angezeigt. Das Notebook ist fertig, wenn der Status auf InService wechselt.

Schritt 2: Die Daten vorbereiten
In diesem Schritt werden Sie mithilfe Ihres Notebook für Amazon SageMaker die Daten vorbereiten, die Sie zum Trainieren Ihres Machine-Learning-Modells benötigen, und die Daten dann in Amazon S3 hochladen.
a. Nachdem der Status Ihrer Notebook-Instance SageMaker-Tutorial auf InService geändert wurde, wählen Sie Jupyter öffnen aus.

b. Wählen Sie in Jupyter Neu und dann conda_python3 aus.

c. Kopieren Sie den folgenden Code in eine neue Codezelle in Ihr Jupyter-Notebook und wählen Sie Ausführen aus.
Dieser Code importiert die erforderlichen Bibliotheken und definiert die Umgebungsvariablen, die Sie zur Vorbereitung der Daten sowie zum Trainieren und Bereitstellen des ML-Modells benötigen.
# import libraries
import boto3, re, sys, math, json, os, sagemaker, urllib.request
from sagemaker import get_execution_role
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from IPython.display import Image
from IPython.display import display
from time import gmtime, strftime
from sagemaker.predictor import csv_serializer
# Define IAM role
role = get_execution_role()
prefix = 'sagemaker/DEMO-xgboost-dm'
my_region = boto3.session.Session().region_name # set the region of the instance
# this line automatically looks for the XGBoost image URI and builds an XGBoost container.
xgboost_container = sagemaker.image_uris.retrieve("xgboost", my_region, "latest")
print("Success - the MySageMakerInstance is in the " + my_region + " region. You will use the " + xgboost_container + " container for your SageMaker endpoint.")
d. Erstellen Sie den S3-Bucket zum Speichern Ihrer Daten. Kopieren Sie den folgenden Code in die neue Codezelle und wählen Sie Ausführen aus.
Hinweis: Stellen Sie sicher, dass Sie den Bucket_Name your-s3-bucket-name durch einen eindeutigen S3-Bucket-Namen ersetzen. Wenn nach dem Ausführen des Codes keine Erfolgsmeldung angezeigt wird, ändern Sie den Namen des Buckets und versuchen Sie es erneut.
bucket_name = 'your-s3-bucket-name' # <--- CHANGE THIS VARIABLE TO A UNIQUE NAME FOR YOUR BUCKET
s3 = boto3.resource('s3')
try:
if my_region == 'us-east-1':
s3.create_bucket(Bucket=bucket_name)
else:
s3.create_bucket(Bucket=bucket_name, CreateBucketConfiguration={ 'LocationConstraint': my_region })
print('S3 bucket created successfully')
except Exception as e:
print('S3 error: ',e)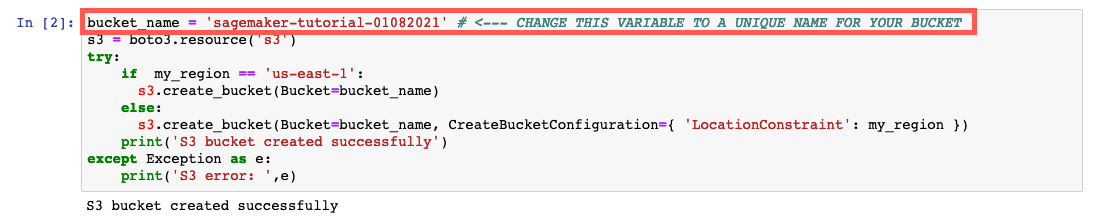
e. Laden Sie die Daten auf Ihre SageMaker-Instance herunter und laden Sie die Daten in einen Datenrahmen. Kopieren Sie den folgenden Code in die neue Codezelle und wählen Sie Ausführen aus.
try:
urllib.request.urlretrieve ("https://d1.awsstatic.com/tmt/build-train-deploy-machine-learning-model-sagemaker/bank_clean.27f01fbbdf43271788427f3682996ae29ceca05d.csv", "bank_clean.csv")
print('Success: downloaded bank_clean.csv.')
except Exception as e:
print('Data load error: ',e)
try:
model_data = pd.read_csv('./bank_clean.csv',index_col=0)
print('Success: Data loaded into dataframe.')
except Exception as e:
print('Data load error: ',e)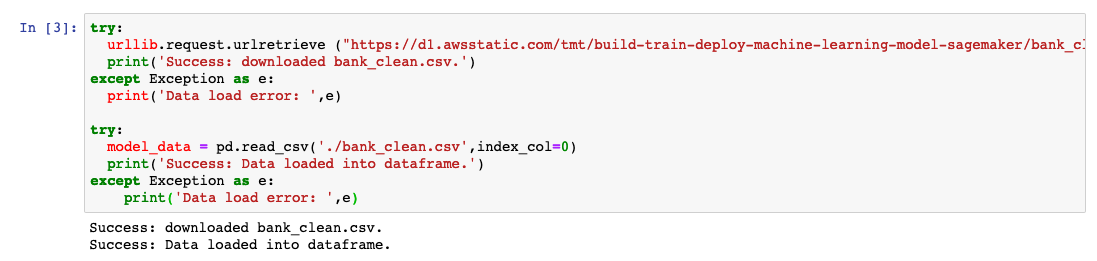
f. Mischen Sie die Daten und teilen Sie sie in Trainingsdaten und Testdaten auf. Kopieren Sie den folgenden Code in die neue Codezelle und wählen Sie Ausführen aus.
Die Trainingsdaten (70 % der Kunden) werden während der Trainingsschleife des Modells verwendet. Die Modellparameter werden mithilfe des Gradientenverfahrens optimiert und iterativ verfeinert. Durch die gradientenbasierte Optimierung können die Parameterwerte ermittelt werden, mit denen Fehler im Modell minimiert werden. Dazu wird der Gradient der Modell-Verlustfunktion berechnet.
Die Testdaten (die restlichen 30 % der Kunden) werden genutzt, um die Leistung des Modells zu beurteilen und festzustellen, wie gut das trainierte Modell unbekannte Daten verallgemeinern kann.
train_data, test_data = np.split(model_data.sample(frac=1, random_state=1729), [int(0.7 * len(model_data))])
print(train_data.shape, test_data.shape)
Schritt 3: Das ML-Modell trainieren
In diesem Schritt werden Sie den Trainingsdatensatz verwenden, um das Machine-Learning-Modell zu trainieren.
a. Kopieren Sie den folgenden Code in eine neue Codezelle in Ihr Jupyter-Notebook und wählen Sie Ausführen aus.
Dieser Code formatiert den Header und die erste Spalte der Trainingsdaten neu und lädt dann die Daten aus dem S3-Bucket. Dieser Schritt ist erforderlich, um den vorgefertigten XGBoost-Algorithmus von Amazon SageMaker zu verwenden.
pd.concat([train_data['y_yes'], train_data.drop(['y_no', 'y_yes'], axis=1)], axis=1).to_csv('train.csv', index=False, header=False)
boto3.Session().resource('s3').Bucket(bucket_name).Object(os.path.join(prefix, 'train/train.csv')).upload_file('train.csv')
s3_input_train = sagemaker.inputs.TrainingInput(s3_data='s3://{}/{}/train'.format(bucket_name, prefix), content_type='csv')
b. Sie müssen die Amazon-SageMaker-Sitzung einrichten, eine Instance des XGBoost-Modells (einen Kalkulator) erstellen und die Hyperparameter des Modells festlegen. Kopieren Sie den folgenden Code in die neue Codezelle und wählen Sie Ausführen aus.
sess = sagemaker.Session()
xgb = sagemaker.estimator.Estimator(xgboost_container,role, instance_count=1, instance_type='ml.m4.xlarge',output_path='s3://{}/{}/output'.format(bucket_name, prefix),sagemaker_session=sess)
xgb.set_hyperparameters(max_depth=5,eta=0.2,gamma=4,min_child_weight=6,subsample=0.8,silent=0,objective='binary:logistic',num_round=100)
c. Den Trainingsauftrag starten Kopieren Sie den folgenden Code in die neue Codezelle und wählen Sie Ausführen aus.
Dieser Code trainiert das Modell mithilfe der Gradientenoptimierung auf einer ml.m4.xlarge-Instance. Nach ein paar Minuten sollten Sie sehen, dass die Trainingsprotokolle in Ihrem Jupyter-Notebook generiert werden.
xgb.fit({'train': s3_input_train})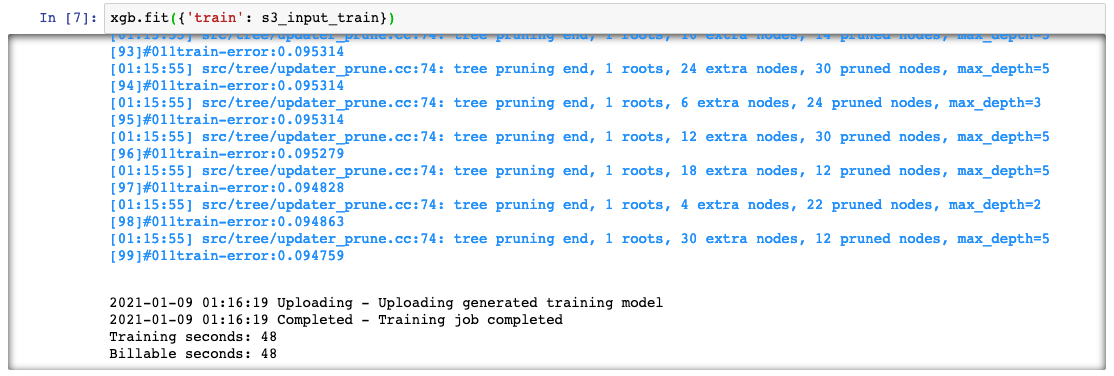
Schritt 4: Das Modell bereitstellen
In diesem Schritt stellen Sie das trainierte Modell auf einem Endpunkt bereit, formatieren die CSV-Daten neu, laden diese und führen anschließend das Modell zum Erstellen von Prognosen aus.
a. Kopieren Sie den folgenden Code in eine neue Codezelle in Ihr Jupyter-Notebook und wählen Sie Ausführen aus.
Dieser Code stellt das Modell auf einem Server bereit und erstellt einen SageMaker-Endpunkt, auf den Sie zugreifen können. Dieser Schritt kann einige Minuten dauern.
xgb_predictor = xgb.deploy(initial_instance_count=1,instance_type='ml.m4.xlarge')
b. Kopieren Sie den folgenden Code in die nächste Codezelle und wählen Sie Ausführen aus, um eine Vorhersage darüber zu treffen, ob Kunden in den Testdaten das Produkt der Bank gezeichnet haben:
from sagemaker.serializers import CSVSerializer
test_data_array = test_data.drop(['y_no', 'y_yes'], axis=1).values #load the data into an array
xgb_predictor.serializer = CSVSerializer() # set the serializer type
predictions = xgb_predictor.predict(test_data_array).decode('utf-8') # predict!
predictions_array = np.fromstring(predictions[1:], sep=',') # and turn the prediction into an array
print(predictions_array.shape)
Schritt 5: Die Leistung des Modells beurteilen
In diesem Schritt beurteilen Sie die Leistung und die Genauigkeit des Machine-Learning-Modells.
Kopieren Sie den folgenden Code in eine neue Codezelle in Ihr Jupyter-Notebook und wählen Sie Ausführen aus.
Dieser Code vergleicht die tatsächlichen und vorhergesagten Werte in einer Tabelle, die als Konfusionsmatrix bezeichnet wird.
Aus der Vorhersage lässt sich schließen, dass das Modell für 90 % der Kunden in den Testdaten präzise vorhersagen konnte, ob ein Kunde ein Einlagenzertifikat zeichnen würde oder nicht. Dabei lag die Genauigkeit für Kunden, die das Zertifikat zeichneten, bei 65 % (278/429) und für Kunden, die es nicht zeichneten, bei 90 % (10 785/11 928).
cm = pd.crosstab(index=test_data['y_yes'], columns=np.round(predictions_array), rownames=['Observed'], colnames=['Predicted'])
tn = cm.iloc[0,0]; fn = cm.iloc[1,0]; tp = cm.iloc[1,1]; fp = cm.iloc[0,1]; p = (tp+tn)/(tp+tn+fp+fn)*100
print("\n{0:<20}{1:<4.1f}%\n".format("Overall Classification Rate: ", p))
print("{0:<15}{1:<15}{2:>8}".format("Predicted", "No Purchase", "Purchase"))
print("Observed")
print("{0:<15}{1:<2.0f}% ({2:<}){3:>6.0f}% ({4:<})".format("No Purchase", tn/(tn+fn)*100,tn, fp/(tp+fp)*100, fp))
print("{0:<16}{1:<1.0f}% ({2:<}){3:>7.0f}% ({4:<}) \n".format("Purchase", fn/(tn+fn)*100,fn, tp/(tp+fp)*100, tp))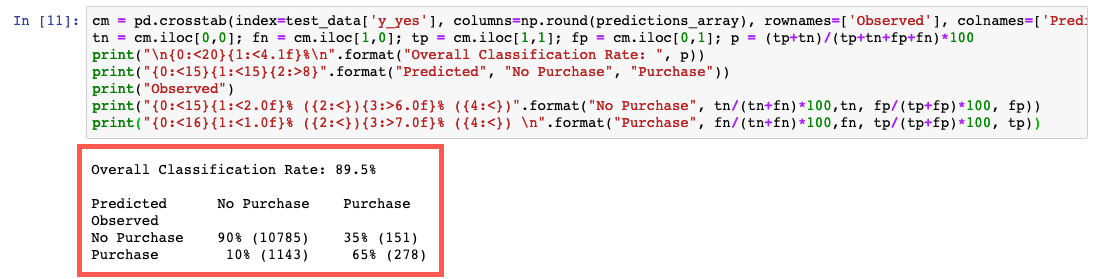
Schritt 6: Bereinigen
In diesem Schritt beenden Sie die in dieser Übung verwendeten Ressourcen.
Wichtig: Die Beendigung von Ressourcen, die nicht aktiv genutzt werden, senkt die Kosten und ist eine bewährte Methode. Wenn Sie Ihre Ressourcen nicht beenden, fallen Gebühren für Ihr Konto an.
a. Löschen Sie Ihren Endpunkt: Kopieren Sie den folgenden Code in Ihr Jupyter-Notebook und wählen Sie Ausführen aus.
xgb_predictor.delete_endpoint(delete_endpoint_config=True)b. Löschen Sie Ihre Trainingsartefakte und Ihren S3-Bucket: Kopieren Sie den folgenden Code, fügen Sie ihn in Ihr Jupyter-Notebook ein und wählen Sie Ausführen aus.
bucket_to_delete = boto3.resource('s3').Bucket(bucket_name)
bucket_to_delete.objects.all().delete()c. Löschen Sie Ihr SageMaker-Notebook: Halten Sie Ihr SageMaker-Notebook an und löschen Sie es.
- Öffnen Sie die SageMaker-Konsole.
- Wählen Sie unter Notebooks die Option Notebook-Instances aus.
- Wählen Sie die Notebook-Instance aus, die Sie für dieses Tutorial erstellt haben, und wählen Sie dann Aktionenund Anhalten aus. Das Stoppen der Notebook-Instance kann mehrere Minuten dauern. Wenn der Status zu Angehalten wechselt, fahren Sie mit dem nächsten Schritt fort.
- Wählen Sie Aktionen und dann Löschen aus.
- Wählen Sie Löschen.
Zusammenfassung
Sie wissen nun, wie Sie mit Amazon SageMaker ein Machine-Learning-Modell erstellen, trainieren, bereitstellen und seine Leistung beurteilen. Mit Amazon SageMaker ist es ganz einfach, ML-Modelle zu erstellen. Der Service bietet alles, was Sie benötigen, um schnell auf Trainingsdaten zuzugreifen und den besten Algorithmus und das beste Framework für Ihre Anwendung auszuwählen. Dabei übernimmt der Service die Verwaltung der zugrunde liegenden Infrastruktur, damit Sie das Modell mit Petabytes von Daten trainieren können.
Nächste Schritte
Nachdem Sie nun ein Modell für maschinelles Lernen vorbereitet, trainiert, bereitgestellt und beurteilt haben, können Sie auf dem Gelernten aufbauen, indem Sie sich mit anderen Amazon-SageMaker-Ressourcen vertraut machen.