Übersicht
In diesem Tutorial lernen Sie, wie Sie mit Amazon SageMaker Pipelines, Amazon SageMaker Model Registry und Amazon SageMaker Clarify durchgehende Workflows für Machine Learning (ML) erstellen und automatisieren.
SageMaker Pipelines ist der erste speziell entwickelte Service für kontinuierliche Integration und kontinuierliche Bereitstellung (CI/CD) für ML. Mit SageMaker Pipelines können Sie die verschiedenen Schritte des ML-Workflows automatisieren, einschließlich des Ladens von Daten, der Datentransformation, des Trainings, der Abstimmung, der Bewertung und der Bereitstellung. SageMaker Model Registry ermöglicht es Ihnen, Modellversionen, ihre Metadaten, wie beispielsweise die Gruppierung von Anwendungsfällen, und Modellleistungsmetriken in einem zentralen Repository zu verfolgen, wo es einfach ist, das richtige Modell für die Bereitstellung auf der Grundlage Ihrer Geschäftsanforderungen auszuwählen. SageMaker Clarify bietet einen besseren Einblick in Ihre Trainingsdaten und Modelle, so dass Sie Verzerrungen erkennen und einschränken und Vorhersagen erklären können.
Im Rahmen dieses Tutorials werden Sie eine SageMaker-Pipeline implementieren, um ein binäres XGBoost-Klassifizierungsmodell zu erstellen, zu trainieren und einzusetzen, das die Wahrscheinlichkeit eines betrügerischen Kfz-Versicherungsanspruchs vorhersagt. Sie werden einen synthetisch erzeugten Datensatz für Kfz-Versicherungsansprüche verwenden. Die Rohdaten sind zwei Tabellen mit Versicherungsdaten: eine Schadentabelle und eine Kundentabelle. Die Anspruchstabelle enthält eine Spalte mit der Bezeichnung Betrug, die angibt, ob ein Anspruch betrügerisch war oder nicht. Ihre Pipeline wird die Rohdaten verarbeiten, Trainings-, Validierungs- und Testdatensätze erstellen, sowie ein binäres Klassifizierungsmodell erstellen und bewerten. Danach wird SageMaker Clarify verwendet, um die Modellverzerrung und die Erklärbarkeit zu testen, und schließlich wird das Modell für die Inferenz eingesetzt.
Was Sie erreichen werden
In diesem Leitfaden werden Sie:
- Eine SageMaker-Pipeline erstellen und ausführen, um den gesamten ML-Lebenszyklus zu automatisieren
- Prognosen anhand des eingesetzten Modells erstellen
Voraussetzungen
Bevor Sie mit dieser Anleitung beginnen, benötigen Sie:
- Ein AWS-Konto: Wenn Sie noch keins haben, folgen Sie der Anleitung zum Einrichten Ihrer Umgebung, um einen schnellen Überblick zu erhalten.
Erfahrung mit AWS
Benötigte Zeit
120 Minuten
Kosten für die Fertigstellung
Siehe SageMaker-Preise, um die Kosten für dieses Tutorial abzuschätzen.
Erfordert
Sie müssen sich bei einem AWS-Konto anmelden.
Verwendete Services
Amazon SageMaker Studio, Amazon SageMaker Pipelines, Amazon SageMaker Clarify, Amazon SageMaker Model Registry
Letzte Aktualisierung
24. Juni 2022
Implementierung
Schritt 1: Richten Sie Ihre Domäne von Amazon SageMaker Studio ein
Ein AWS-Konto kann nur eine SageMaker-Studio-Domäne pro Region haben. Wenn Sie bereits über eine SageMaker-Studio-Domäne in der Region USA Ost (Nord-Virginia) verfügen, befolgen Sie die Anleitung zur Einrichtung von SageMaker Studio für ML-Workflows, um die erforderlichen AWS-IAM-Richtlinien mit Ihrem SageMaker-Studio-Konto zu verknüpfen, überspringen Sie dann Schritt 1 und fahren Sie direkt mit Schritt 2 fort.
Wenn Sie keine bestehende SageMaker-Studio-Domäne haben, fahren Sie mit Schritt 1 fort, um eine AWS-CloudFormation-Vorlage auszuführen, die eine SageMaker-Studio-Domäne erstellt und die für den Rest dieses Lehrgangs erforderlichen Berechtigungen hinzufügt.
Wählen Sie den Link für AWS-CloudFormation-Stack. Dieser Link öffnet die AWS-CloudFormation-Konsole und erstellt Ihre SageMaker-Studio-Domäne und einen Benutzer namens studio-user . Er fügt auch die erforderlichen Berechtigungen zu Ihrem SageMaker-Studio-Konto hinzu. Bestätigen Sie in der CloudFormation-Konsole, dass USA Ost (Nord-Virginia) die Region ist, die in der oberen rechten Ecke angezeigt wird. Der Stack-Name sollte CFN-SM-IM-Lambda-catalog lauten und sollte nicht geändert werden. Dieser Stack benötigt etwa 10 Minuten, um alle Ressourcen zu erstellen.
Dieser Stack geht davon aus, dass Sie bereits eine öffentliche VPC in Ihrem Konto eingerichtet haben. Wenn Sie keine öffentliche VPC haben, lesen Sie VPC mit einem einzigen öffentlichen Subnetz, um zu erfahren, wie Sie eine öffentliche VPC erstellen können.

Wählen Sie Ich bestätige, dass AWS CloudFormation möglicherweise IAM-Ressourcen erstellt und wählen Sie dann Stack erstellen.

Wählen Sie im Bereich CloudFormation die Option Stacks. Es dauert etwa 10 Minuten, bis der Stack erstellt ist. Wenn der Stack erstellt wird, ändert sich der Status des Stacks von CREATE_IN_PROGRESS zu CREATE_COMPLETE.

Schritt 2: Einrichten eines SageMaker-Studio-Notebooks und Parametrisierung der Pipeline
In diesem Schritt starten Sie ein neues SageMaker-Studio-Notebook und konfigurieren die SageMaker-Variablen, die für die Interaktion mit Amazon Simple Storage Service (Amazon S3) erforderlich sind.
Geben Sie SageMaker Studio in die Suchleiste der AWS-Konsole ein und wählen Sie dann SageMaker Studio. Wählen Sie USA Ost (Nord-Virginia) aus der Dropdown-Liste Region in der oberen rechten Ecke der Konsole.

Wählen Sie für Anwendung starten die Option Studio, um SageMaker Studio mit dem studio-user-Profil zu öffnen.

Wählen Sie in der Navigationsleiste von SageMaker Studio Datei, Neu, Notebook.

Wählen Sie im Dialogfeld Notebook-Umgebung einrichten unter Image die Option Datenwissenschaft. Der Python-3-Kernel wird automatisch ausgewählt. Wählen Sie Auswählen aus.

Der Kernel in der oberen rechten Ecke des Notizbuchs sollte nun Python 3 (Datenwissenschaft) anzeigen.

Kopieren Sie den folgenden Code, um die erforderlichen Bibliotheken zu importieren, fügen Sie ihn in eine Zelle in Ihrem Notebook ein und führen Sie die Zelle aus.
import pandas as pd
import json
import boto3
import pathlib
import io
import sagemaker
from sagemaker.deserializers import CSVDeserializer
from sagemaker.serializers import CSVSerializer
from sagemaker.xgboost.estimator import XGBoost
from sagemaker.sklearn.processing import SKLearnProcessor
from sagemaker.processing import (
ProcessingInput,
ProcessingOutput,
ScriptProcessor
)
from sagemaker.inputs import TrainingInput
from sagemaker.workflow.pipeline import Pipeline
from sagemaker.workflow.steps import (
ProcessingStep,
TrainingStep,
CreateModelStep
)
from sagemaker.workflow.check_job_config import CheckJobConfig
from sagemaker.workflow.parameters import (
ParameterInteger,
ParameterFloat,
ParameterString,
ParameterBoolean
)
from sagemaker.workflow.clarify_check_step import (
ModelBiasCheckConfig,
ClarifyCheckStep,
ModelExplainabilityCheckConfig
)
from sagemaker.workflow.step_collections import RegisterModel
from sagemaker.workflow.conditions import ConditionGreaterThanOrEqualTo
from sagemaker.workflow.properties import PropertyFile
from sagemaker.workflow.condition_step import ConditionStep
from sagemaker.workflow.functions import JsonGet
from sagemaker.workflow.lambda_step import (
LambdaStep,
LambdaOutput,
LambdaOutputTypeEnum,
)
from sagemaker.lambda_helper import Lambda
from sagemaker.model_metrics import (
MetricsSource,
ModelMetrics,
FileSource
)
from sagemaker.drift_check_baselines import DriftCheckBaselines
from sagemaker.image_uris import retrieveKopieren Sie den folgenden Codeblock, fügen Sie ihn in eine Zelle ein und führen Sie ihn aus, um SageMaker und S3-Client-Objekte mit den SageMaker- und AWS-SDKs einzurichten. Diese Objekte werden benötigt, um SageMaker zu ermöglichen, verschiedene Aktionen wie das Bereitstellen und Aufrufen von Endpunkten auszuführen und um mit Amazon S3 und AWS Lambda zu interagieren. Der Code richtet auch die Speicherorte der S3-Buckets ein, in welchen die Rohdaten, die verarbeiteten Datensätze und die Modellartefakte gespeichert werden. Beachten Sie, dass die Lese- und Schreib-Buckets getrennt sind. Der Lese-Bucket ist der öffentliche S3-Bucket namens sagemaker-sample-files und enthält die Rohdatensätze. Der Schreib-Bucket ist der Standard-S3-Bucket, der Ihrem Konto mit dem Namen sagemaker-<Ihre-Region>-<Ihre-Kontonummer> zugeordnet ist und später in diesem Tutorial zum Speichern der verarbeiteten Datensätze und Artefakte verwendet wird.
# Instantiate AWS services session and client objects
sess = sagemaker.Session()
write_bucket = sess.default_bucket()
write_prefix = "fraud-detect-demo"
region = sess.boto_region_name
s3_client = boto3.client("s3", region_name=region)
sm_client = boto3.client("sagemaker", region_name=region)
sm_runtime_client = boto3.client("sagemaker-runtime")
# Fetch SageMaker execution role
sagemaker_role = sagemaker.get_execution_role()
# S3 locations used for parameterizing the notebook run
read_bucket = "sagemaker-sample-files"
read_prefix = "datasets/tabular/synthetic_automobile_claims"
# S3 location where raw data to be fetched from
raw_data_key = f"s3://{read_bucket}/{read_prefix}"
# S3 location where processed data to be uploaded
processed_data_key = f"{write_prefix}/processed"
# S3 location where train data to be uploaded
train_data_key = f"{write_prefix}/train"
# S3 location where validation data to be uploaded
validation_data_key = f"{write_prefix}/validation"
# S3 location where test data to be uploaded
test_data_key = f"{write_prefix}/test"
# Full S3 paths
claims_data_uri = f"{raw_data_key}/claims.csv"
customers_data_uri = f"{raw_data_key}/customers.csv"
output_data_uri = f"s3://{write_bucket}/{write_prefix}/"
scripts_uri = f"s3://{write_bucket}/{write_prefix}/scripts"
estimator_output_uri = f"s3://{write_bucket}/{write_prefix}/training_jobs"
processing_output_uri = f"s3://{write_bucket}/{write_prefix}/processing_jobs"
model_eval_output_uri = f"s3://{write_bucket}/{write_prefix}/model_eval"
clarify_bias_config_output_uri = f"s3://{write_bucket}/{write_prefix}/model_monitor/bias_config"
clarify_explainability_config_output_uri = f"s3://{write_bucket}/{write_prefix}/model_monitor/explainability_config"
bias_report_output_uri = f"s3://{write_bucket}/{write_prefix}/clarify_output/pipeline/bias"
explainability_report_output_uri = f"s3://{write_bucket}/{write_prefix}/clarify_output/pipeline/explainability"
# Retrieve training image
training_image = retrieve(framework="xgboost", region=region, version="1.3-1")Kopieren Sie den folgenden Code und fügen Sie ihn ein, um die Namen für die verschiedenen Komponenten der SageMaker-Pipeline festzulegen, beispielsweise das Modell und den Endpunkt, und um die Typen und Anzahl der Trainings- und Inferenz-Instances anzugeben. Diese Werte werden für die Parametrisierung Ihrer Pipeline verwendet.
# Set names of pipeline objects
pipeline_name = "FraudDetectXGBPipeline"
pipeline_model_name = "fraud-detect-xgb-pipeline"
model_package_group_name = "fraud-detect-xgb-model-group"
base_job_name_prefix = "fraud-detect"
endpoint_config_name = f"{pipeline_model_name}-endpoint-config"
endpoint_name = f"{pipeline_model_name}-endpoint"
# Set data parameters
target_col = "fraud"
# Set instance types and counts
process_instance_type = "ml.c5.xlarge"
train_instance_count = 1
train_instance_type = "ml.m4.xlarge"
predictor_instance_count = 1
predictor_instance_type = "ml.m4.xlarge"
clarify_instance_count = 1
clarify_instance_type = "ml.m4.xlarge"SageMaker Pipelines unterstützt Parametrisierung, was Ihnen die Angabe von Eingabeparametern zur Laufzeit ermöglicht, ohne Ihren Pipeline-Code zu ändern. Sie können die unter dem Modul sagemaker.workflow.parameters verfügbaren Module wie ParameterInteger, ParameterFloat, ParameterString und ParameterBoolean verwenden, um Pipeline-Parameter unterschiedlicher Datentypen anzugeben. Kopieren Sie den folgenden Code, fügen Sie ihn ein und führen Sie ihn aus, um mehrfache Eingabeparameter, einschließlich SageMaker-Clarify-Konfigurationen, einzurichten.
# Set up pipeline input parameters
# Set processing instance type
process_instance_type_param = ParameterString(
name="ProcessingInstanceType",
default_value=process_instance_type,
)
# Set training instance type
train_instance_type_param = ParameterString(
name="TrainingInstanceType",
default_value=train_instance_type,
)
# Set training instance count
train_instance_count_param = ParameterInteger(
name="TrainingInstanceCount",
default_value=train_instance_count
)
# Set deployment instance type
deploy_instance_type_param = ParameterString(
name="DeployInstanceType",
default_value=predictor_instance_type,
)
# Set deployment instance count
deploy_instance_count_param = ParameterInteger(
name="DeployInstanceCount",
default_value=predictor_instance_count
)
# Set Clarify check instance type
clarify_instance_type_param = ParameterString(
name="ClarifyInstanceType",
default_value=clarify_instance_type,
)
# Set model bias check params
skip_check_model_bias_param = ParameterBoolean(
name="SkipModelBiasCheck",
default_value=False
)
register_new_baseline_model_bias_param = ParameterBoolean(
name="RegisterNewModelBiasBaseline",
default_value=False
)
supplied_baseline_constraints_model_bias_param = ParameterString(
name="ModelBiasSuppliedBaselineConstraints",
default_value=""
)
# Set model explainability check params
skip_check_model_explainability_param = ParameterBoolean(
name="SkipModelExplainabilityCheck",
default_value=False
)
register_new_baseline_model_explainability_param = ParameterBoolean(
name="RegisterNewModelExplainabilityBaseline",
default_value=False
)
supplied_baseline_constraints_model_explainability_param = ParameterString(
name="ModelExplainabilitySuppliedBaselineConstraints",
default_value=""
)
# Set model approval param
model_approval_status_param = ParameterString(
name="ModelApprovalStatus", default_value="Approved"
)Schritt 3: Aufbau der Pipeline-Komponenten
Eine Pipeline ist eine Abfolge von Schritten, die einzeln erstellt und dann zu einem ML-Workflow zusammengefügt werden können. Das folgende Diagramm zeigt die wesentlichen Schritte einer Pipeline.
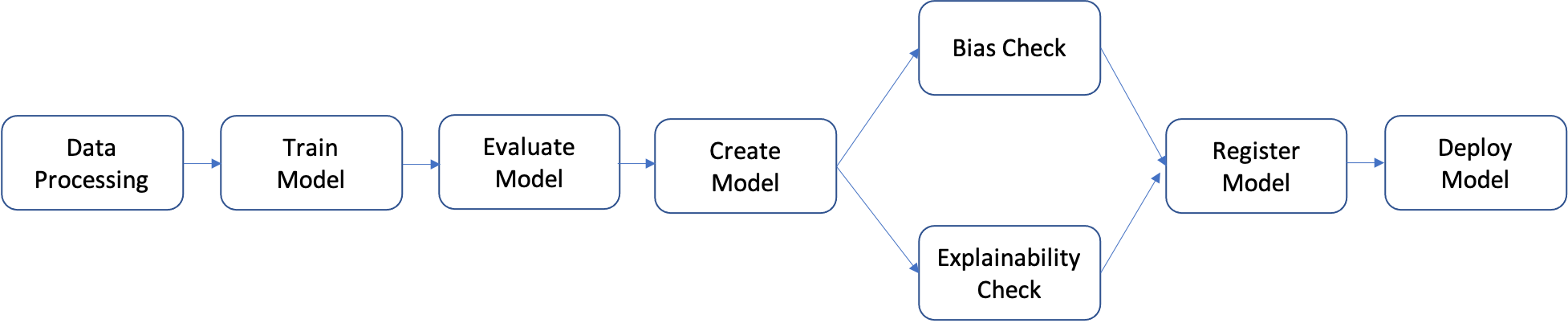
In diesem Tutorial werden Sie eine Pipeline mit den folgenden Schritten aufbauen:
- Schritt der Datenverarbeitung: Ausführung eines SageMaker-Verarbeitungsauftrags unter Verwendung der eingegebenen Rohdaten in S3 und Ausgabe von Trainings-, Validierungs- und Test-Splits in S3.
- Trainingsschritt: Trainiert ein XGBoost-Modell unter Verwendung von SageMaker-Trainingsaufträgen mit Trainings- und Validierungsdaten in S3 als Eingaben und speichert das trainierte Modell-Artefakt in S3.
- Auswertungsschritt: Bewertung des Modells auf dem Testdatensatz durch Ausführen eines SageMaker-Verarbeitungsauftrags unter Verwendung der Testdaten und des Modellartefakts in S3 als Eingaben und Speichern des ausgegebenen Modellleistungsbewertungsberichts in S3.
- Bedingter Schritt: Vergleich der Modellleistung auf dem Testdatensatz mit dem Schwellenwert. Führt einen vordefinierten Schritt von SageMaker Pipelines aus, der den Bericht zur Bewertung der Modellleistung in S3 als Eingabe verwendet, und speichert die Ausgabeliste der Pipeline-Schritte, die ausgeführt werden, wenn die Modellleistung akzeptabel ist.
- Schritt zur Erstellung des Modells: Führt einen vordefinierten Schritt von SageMaker Pipelines aus, der das Modell-Artefakt in S3 als Eingabe verwendet, und speichert das ausgegebene SageMaker-Modell in S3.
- Schritt zur Verzerrungsprüfung: Überprüft die Modellverzerrung mithilfe von SageMaker Clarify mit den Trainingsdaten und dem Modellartefakt in S3 als Eingaben und speichert den Bericht über die Modellverzerrung und die Basisdatenmetriken in S3.
- Schritt zur Erklärung des Modells: Führt SageMaker Clarify mit den Trainingsdaten und dem Modell-Artefakt in S3 als Eingaben aus und speichert den Bericht über die Erklärbarkeit des Modells und die Baseline-Metriken in S3.
- Registrierungsschritt: Führt einen vordefinierten Schritt von SageMaker Pipelines aus, der die Modell-, Verzerrungs- und Erklärbarkeits-Basiskennzahlen als Eingaben verwendet, um das Modell in der SageMaker Model Registry zu registrieren.
- Bereitstellungsschritt: Führt einen vordefinierten Schritt von SageMaker Pipelines aus, der eine Handler-Funktion von AWS Lambda, das Modell und die Endpunktkonfiguration als Eingaben verwendet, um das Modell an einem Endpunkt von SageMaker Real-Time Inference bereitzustellen.
SageMaker Pipelines bietet viele vordefinierte Schritttypen, wie beispielsweise Schritte zur Datenverarbeitung, zum Modelltraining, zur Modellabstimmung und zur Batch-Transformation. Weitere Informationen finden Sie unter Pipeline-Schritte im Entwicklerhandbuch für Amazon Sagemaker. In den folgenden Schritten konfigurieren und definieren Sie jeden Pipelineschritt individuell und definieren dann die Pipeline selbst, indem Sie die Pipeline-Schritte mit den Eingabeparametern kombinieren.
Datenverarbeitungsschritt: In diesem Schritt bereiten Sie ein Python-Skript vor, mit dem Sie Rohdateien einlesen, Verarbeitungen wie die Imputation fehlender Werte und das Feature-Engineering durchführen und die Trainings-, Validierungs- und Test-Splits für die Modellerstellung zusammenstellen. Kopieren Sie den folgenden Code, fügen Sie ihn ein und führen Sie ihn aus, um Ihr Verarbeitungsskript zu erstellen.
%%writefile preprocessing.py
import argparse
import pathlib
import boto3
import os
import pandas as pd
import logging
from sklearn.model_selection import train_test_split
logger = logging.getLogger()
logger.setLevel(logging.INFO)
logger.addHandler(logging.StreamHandler())
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--train-ratio", type=float, default=0.8)
parser.add_argument("--validation-ratio", type=float, default=0.1)
parser.add_argument("--test-ratio", type=float, default=0.1)
args, _ = parser.parse_known_args()
logger.info("Received arguments {}".format(args))
# Set local path prefix in the processing container
local_dir = "/opt/ml/processing"
input_data_path_claims = os.path.join("/opt/ml/processing/claims", "claims.csv")
input_data_path_customers = os.path.join("/opt/ml/processing/customers", "customers.csv")
logger.info("Reading claims data from {}".format(input_data_path_claims))
df_claims = pd.read_csv(input_data_path_claims)
logger.info("Reading customers data from {}".format(input_data_path_customers))
df_customers = pd.read_csv(input_data_path_customers)
logger.debug("Formatting column names.")
# Format column names
df_claims = df_claims.rename({c : c.lower().strip().replace(' ', '_') for c in df_claims.columns}, axis = 1)
df_customers = df_customers.rename({c : c.lower().strip().replace(' ', '_') for c in df_customers.columns}, axis = 1)
logger.debug("Joining datasets.")
# Join datasets
df_data = df_claims.merge(df_customers, on = 'policy_id', how = 'left')
# Drop selected columns not required for model building
df_data = df_data.drop(['customer_zip'], axis = 1)
# Select Ordinal columns
ordinal_cols = ["police_report_available", "policy_liability", "customer_education"]
# Select categorical columns and filling with na
cat_cols_all = list(df_data.select_dtypes('object').columns)
cat_cols = [c for c in cat_cols_all if c not in ordinal_cols]
df_data[cat_cols] = df_data[cat_cols].fillna('na')
logger.debug("One-hot encoding categorical columns.")
# One-hot encoding categorical columns
df_data = pd.get_dummies(df_data, columns = cat_cols)
logger.debug("Encoding ordinal columns.")
# Ordinal encoding
mapping = {
"Yes": "1",
"No": "0"
}
df_data['police_report_available'] = df_data['police_report_available'].map(mapping)
df_data['police_report_available'] = df_data['police_report_available'].astype(float)
mapping = {
"15/30": "0",
"25/50": "1",
"30/60": "2",
"100/200": "3"
}
df_data['policy_liability'] = df_data['policy_liability'].map(mapping)
df_data['policy_liability'] = df_data['policy_liability'].astype(float)
mapping = {
"Below High School": "0",
"High School": "1",
"Associate": "2",
"Bachelor": "3",
"Advanced Degree": "4"
}
df_data['customer_education'] = df_data['customer_education'].map(mapping)
df_data['customer_education'] = df_data['customer_education'].astype(float)
df_processed = df_data.copy()
df_processed.columns = [c.lower() for c in df_data.columns]
df_processed = df_processed.drop(["policy_id", "customer_gender_unkown"], axis=1)
# Split into train, validation, and test sets
train_ratio = args.train_ratio
val_ratio = args.validation_ratio
test_ratio = args.test_ratio
logger.debug("Splitting data into train, validation, and test sets")
y = df_processed['fraud']
X = df_processed.drop(['fraud'], axis = 1)
X_train_val, X_test, y_train_val, y_test = train_test_split(X, y, test_size=test_ratio, random_state=42)
X_train, X_val, y_train, y_val = train_test_split(X_train_val, y_train_val, test_size=val_ratio, random_state=42)
train_df = pd.concat([y_train, X_train], axis = 1)
val_df = pd.concat([y_val, X_val], axis = 1)
test_df = pd.concat([y_test, X_test], axis = 1)
dataset_df = pd.concat([y, X], axis = 1)
logger.info("Train data shape after preprocessing: {}".format(train_df.shape))
logger.info("Validation data shape after preprocessing: {}".format(val_df.shape))
logger.info("Test data shape after preprocessing: {}".format(test_df.shape))
# Save processed datasets to the local paths in the processing container.
# SageMaker will upload the contents of these paths to S3 bucket
logger.debug("Writing processed datasets to container local path.")
train_output_path = os.path.join(f"{local_dir}/train", "train.csv")
validation_output_path = os.path.join(f"{local_dir}/val", "validation.csv")
test_output_path = os.path.join(f"{local_dir}/test", "test.csv")
full_processed_output_path = os.path.join(f"{local_dir}/full", "dataset.csv")
logger.info("Saving train data to {}".format(train_output_path))
train_df.to_csv(train_output_path, index=False)
logger.info("Saving validation data to {}".format(validation_output_path))
val_df.to_csv(validation_output_path, index=False)
logger.info("Saving test data to {}".format(test_output_path))
test_df.to_csv(test_output_path, index=False)
logger.info("Saving full processed data to {}".format(full_processed_output_path))
dataset_df.to_csv(full_processed_output_path, index=False)
Kopieren Sie dann den folgenden Codeblock, fügen Sie ihn ein und führen Sie ihn aus, um den Prozessor zu instanzieren und den Schritt SageMaker Pipelines auszuführen, um das Verarbeitungsskript zu starten. Weil das Verarbeitungsskript in Pandas geschrieben ist, verwenden Sie einen SKLearnProcessor. Die Funktion ProcessingStep von SageMaker Pipelines nimmt die folgenden Argumente entgegen: den Prozessor, die Eingabe-S3-Speicherorte für Rohdatensätze und die Ausgabe-S3-Speicherorte zum Speichern verarbeiteter Datensätze. Zusätzliche Argumente wie Trainings-, Validierungs- und Test-Split-Verhältnisse werden über das Argument job_arguments bereitgestellt.
from sagemaker.workflow.pipeline_context import PipelineSession
# Upload processing script to S3
s3_client.upload_file(
Filename="preprocessing.py", Bucket=write_bucket, Key=f"{write_prefix}/scripts/preprocessing.py"
)
# Define the SKLearnProcessor configuration
sklearn_processor = SKLearnProcessor(
framework_version="0.23-1",
role=sagemaker_role,
instance_count=1,
instance_type=process_instance_type,
base_job_name=f"{base_job_name_prefix}-processing",
)
# Define pipeline processing step
process_step = ProcessingStep(
name="DataProcessing",
processor=sklearn_processor,
inputs=[
ProcessingInput(source=claims_data_uri, destination="/opt/ml/processing/claims"),
ProcessingInput(source=customers_data_uri, destination="/opt/ml/processing/customers")
],
outputs=[
ProcessingOutput(destination=f"{processing_output_uri}/train_data", output_name="train_data", source="/opt/ml/processing/train"),
ProcessingOutput(destination=f"{processing_output_uri}/validation_data", output_name="validation_data", source="/opt/ml/processing/val"),
ProcessingOutput(destination=f"{processing_output_uri}/test_data", output_name="test_data", source="/opt/ml/processing/test"),
ProcessingOutput(destination=f"{processing_output_uri}/processed_data", output_name="processed_data", source="/opt/ml/processing/full")
],
job_arguments=[
"--train-ratio", "0.8",
"--validation-ratio", "0.1",
"--test-ratio", "0.1"
],
code=f"s3://{write_bucket}/{write_prefix}/scripts/preprocessing.py"
)Kopieren Sie den folgenden Codeblock, fügen Sie ihn ein und führen Sie ihn aus, um das Trainingsskript vorzubereiten. Dieses Skript verkapselt die Trainingslogik für den binären XGBoost-Klassifikator. Die Hyperparameter, die beim Training des Modells verwendet werden, werden später im Tutorial durch die Definition des Trainingsschritts bereitgestellt.
%%writefile xgboost_train.py
import argparse
import os
import joblib
import json
import pandas as pd
import xgboost as xgb
from sklearn.metrics import roc_auc_score
if __name__ == "__main__":
parser = argparse.ArgumentParser()
# Hyperparameters and algorithm parameters are described here
parser.add_argument("--num_round", type=int, default=100)
parser.add_argument("--max_depth", type=int, default=3)
parser.add_argument("--eta", type=float, default=0.2)
parser.add_argument("--subsample", type=float, default=0.9)
parser.add_argument("--colsample_bytree", type=float, default=0.8)
parser.add_argument("--objective", type=str, default="binary:logistic")
parser.add_argument("--eval_metric", type=str, default="auc")
parser.add_argument("--nfold", type=int, default=3)
parser.add_argument("--early_stopping_rounds", type=int, default=3)
# SageMaker specific arguments. Defaults are set in the environment variables
# Set location of input training data
parser.add_argument("--train_data_dir", type=str, default=os.environ.get("SM_CHANNEL_TRAIN"))
# Set location of input validation data
parser.add_argument("--validation_data_dir", type=str, default=os.environ.get("SM_CHANNEL_VALIDATION"))
# Set location where trained model will be stored. Default set by SageMaker, /opt/ml/model
parser.add_argument("--model_dir", type=str, default=os.environ.get("SM_MODEL_DIR"))
# Set location where model artifacts will be stored. Default set by SageMaker, /opt/ml/output/data
parser.add_argument("--output_data_dir", type=str, default=os.environ.get("SM_OUTPUT_DATA_DIR"))
args = parser.parse_args()
data_train = pd.read_csv(f"{args.train_data_dir}/train.csv")
train = data_train.drop("fraud", axis=1)
label_train = pd.DataFrame(data_train["fraud"])
dtrain = xgb.DMatrix(train, label=label_train)
data_validation = pd.read_csv(f"{args.validation_data_dir}/validation.csv")
validation = data_validation.drop("fraud", axis=1)
label_validation = pd.DataFrame(data_validation["fraud"])
dvalidation = xgb.DMatrix(validation, label=label_validation)
# Choose XGBoost model hyperparameters
params = {"max_depth": args.max_depth,
"eta": args.eta,
"objective": args.objective,
"subsample" : args.subsample,
"colsample_bytree":args.colsample_bytree
}
num_boost_round = args.num_round
nfold = args.nfold
early_stopping_rounds = args.early_stopping_rounds
# Cross-validate train XGBoost model
cv_results = xgb.cv(
params=params,
dtrain=dtrain,
num_boost_round=num_boost_round,
nfold=nfold,
early_stopping_rounds=early_stopping_rounds,
metrics=["auc"],
seed=42,
)
model = xgb.train(params=params, dtrain=dtrain, num_boost_round=len(cv_results))
train_pred = model.predict(dtrain)
validation_pred = model.predict(dvalidation)
train_auc = roc_auc_score(label_train, train_pred)
validation_auc = roc_auc_score(label_validation, validation_pred)
print(f"[0]#011train-auc:{train_auc:.2f}")
print(f"[0]#011validation-auc:{validation_auc:.2f}")
metrics_data = {"hyperparameters" : params,
"binary_classification_metrics": {"validation:auc": {"value": validation_auc},
"train:auc": {"value": train_auc}
}
}
# Save the evaluation metrics to the location specified by output_data_dir
metrics_location = args.output_data_dir + "/metrics.json"
# Save the trained model to the location specified by model_dir
model_location = args.model_dir + "/xgboost-model"
with open(metrics_location, "w") as f:
json.dump(metrics_data, f)
with open(model_location, "wb") as f:
joblib.dump(model, f)Richten Sie das Modelltraining mithilfe eines SageMaker-XGBoost-Estimators und der Funktion TrainingStep von SageMaker Pipelines ein.
# Set XGBoost model hyperparameters
hyperparams = {
"eval_metric" : "auc",
"objective": "binary:logistic",
"num_round": "5",
"max_depth":"5",
"subsample":"0.75",
"colsample_bytree":"0.75",
"eta":"0.5"
}
# Set XGBoost estimator
xgb_estimator = XGBoost(
entry_point="xgboost_train.py",
output_path=estimator_output_uri,
code_location=estimator_output_uri,
hyperparameters=hyperparams,
role=sagemaker_role,
# Fetch instance type and count from pipeline parameters
instance_count=train_instance_count,
instance_type=train_instance_type,
framework_version="1.3-1"
)
# Access the location where the preceding processing step saved train and validation datasets
# Pipeline step properties can give access to outputs which can be used in succeeding steps
s3_input_train = TrainingInput(
s3_data=process_step.properties.ProcessingOutputConfig.Outputs["train_data"].S3Output.S3Uri,
content_type="csv",
s3_data_type="S3Prefix"
)
s3_input_validation = TrainingInput(
s3_data=process_step.properties.ProcessingOutputConfig.Outputs["validation_data"].S3Output.S3Uri,
content_type="csv",
s3_data_type="S3Prefix"
)
# Set pipeline training step
train_step = TrainingStep(
name="XGBModelTraining",
estimator=xgb_estimator,
inputs={
"train":s3_input_train, # Train channel
"validation": s3_input_validation # Validation channel
}
)Kopieren Sie den folgenden Codeblock, fügen Sie ihn ein und führen Sie ihn aus, um ein SageMaker-Modell mit der Funktion CreateModelStep von SageMaker Pipelines zu erstellen. In diesem Schritt werden die Ergebnisse des Trainingsschritts verwendet, um das Modell für den Einsatz zu verpacken. Beachten Sie, dass der Wert für das Argument Instance-Typ mit dem SageMaker-Pipelines-Parameter übergeben wird, den Sie zuvor im Tutorial definiert haben.
# Create a SageMaker model
model = sagemaker.model.Model(
image_uri=training_image,
model_data=train_step.properties.ModelArtifacts.S3ModelArtifacts,
sagemaker_session=sess,
role=sagemaker_role
)
# Specify model deployment instance type
inputs = sagemaker.inputs.CreateModelInput(instance_type=deploy_instance_type_param)
create_model_step = CreateModelStep(name="FraudDetModel", model=model, inputs=inputs)In einem ML-Arbeitsablauf ist es wichtig, ein trainiertes Modell auf potenzielle Verzerrungen zu prüfen und zu verstehen, wie die unterschiedlichen Merkmale in den Eingabedaten die Modellvorhersage beeinflussen. SageMaker Pipelines bietet eine ClarifyCheckStep-Funktion, mit der drei Arten von Prüfungen durchgeführt werden können: Datenverzerrungsprüfung (vor dem Training), Modellverzerrungsprüfung (nach dem Training) und Modellerklärbarkeitsprüfung. Um die Laufzeit zu verkürzen, werden in diesem Tutorial nur Verzerrungs- und Erklärbarkeitsprüfungen durchgeführt. Kopieren Sie den folgenden Codeblock, fügen Sie ihn ein und führen Sie ihn aus, um SageMaker Clarify für die Modellverzerrungsprüfung einzurichten. Beachten Sie, dass dieser Schritt Assets, wie die Trainingsdaten und das in den vorherigen Schritten erstellte SageMaker-Modell, über das Attribut properties aufnimmt. Wenn die Pipeline ausgeführt wird, wird dieser Schritt erst gestartet, nachdem die Schritte, die die Eingaben liefern, beendet sind. Weitere Details finden Sie unter Datenabhängigkeit zwischen Schritten im Entwicklerhandbuch für Amazon SageMaker. Um die Kosten und die Laufzeit des Tutorials zu reduzieren, ist die Funktion ModelBiasCheckConfig so konfiguriert, dass sie nur eine Bias-Metrik, DPPL, berechnet. Weitere Informationen zu den in SageMaker Clarify verfügbaren Verzerrungsmetriken finden Sie unter Messen von Posttraining-Daten und Modellverzerrungen im Entwicklerhandbuch für Amazon SageMaker.
# Set up common configuration parameters to be used across multiple steps
check_job_config = CheckJobConfig(
role=sagemaker_role,
instance_count=1,
instance_type=clarify_instance_type,
volume_size_in_gb=30,
sagemaker_session=sess,
)
# Set up configuration of data to be used for model bias check
model_bias_data_config = sagemaker.clarify.DataConfig(
# Fetch S3 location where processing step saved train data
s3_data_input_path=process_step.properties.ProcessingOutputConfig.Outputs["train_data"].S3Output.S3Uri,
s3_output_path=bias_report_output_uri,
label=target_col,
dataset_type="text/csv",
s3_analysis_config_output_path=clarify_bias_config_output_uri
)
# Set up details of the trained model to be checked for bias
model_config = sagemaker.clarify.ModelConfig(
# Pull model name from model creation step
model_name=create_model_step.properties.ModelName,
instance_count=train_instance_count,
instance_type=train_instance_type
)
# Set up column and categories that are to be checked for bias
model_bias_config = sagemaker.clarify.BiasConfig(
label_values_or_threshold=[0],
facet_name="customer_gender_female",
facet_values_or_threshold=[1]
)
# Set up model predictions configuration to get binary labels from probabilities
model_predictions_config = sagemaker.clarify.ModelPredictedLabelConfig(probability_threshold=0.5)
model_bias_check_config = ModelBiasCheckConfig(
data_config=model_bias_data_config,
data_bias_config=model_bias_config,
model_config=model_config,
model_predicted_label_config=model_predictions_config,
methods=["DPPL"]
)
# Set up pipeline model bias check step
model_bias_check_step = ClarifyCheckStep(
name="ModelBiasCheck",
clarify_check_config=model_bias_check_config,
check_job_config=check_job_config,
skip_check=skip_check_model_bias_param,
register_new_baseline=register_new_baseline_model_bias_param,
supplied_baseline_constraints=supplied_baseline_constraints_model_bias_param
)Kopieren Sie den folgenden Codeblock, fügen Sie ihn ein und führen Sie ihn aus, um Erklärbarkeitsprüfungen für Modelle einzurichten. Dieser Schritt liefert Einsichten wie die Bedeutung von Merkmalen (wie sich Eingangsmerkmale auf Modellvorhersagen auswirken).
# Set configuration of data to be used for model explainability check
model_explainability_data_config = sagemaker.clarify.DataConfig(
# Fetch S3 location where processing step saved train data
s3_data_input_path=process_step.properties.ProcessingOutputConfig.Outputs["train_data"].S3Output.S3Uri,
s3_output_path=explainability_report_output_uri,
label=target_col,
dataset_type="text/csv",
s3_analysis_config_output_path=clarify_explainability_config_output_uri
)
# Set SHAP configuration for Clarify to compute global and local SHAP values for feature importance
shap_config = sagemaker.clarify.SHAPConfig(
seed=42,
num_samples=100,
agg_method="mean_abs",
save_local_shap_values=True
)
model_explainability_config = ModelExplainabilityCheckConfig(
data_config=model_explainability_data_config,
model_config=model_config,
explainability_config=shap_config
)
# Set pipeline model explainability check step
model_explainability_step = ClarifyCheckStep(
name="ModelExplainabilityCheck",
clarify_check_config=model_explainability_config,
check_job_config=check_job_config,
skip_check=skip_check_model_explainability_param,
register_new_baseline=register_new_baseline_model_explainability_param,
supplied_baseline_constraints=supplied_baseline_constraints_model_explainability_param
)In Produktionssystemen werden nicht alle trainierten Modelle eingesetzt. Normalerweise werden nur die Modelle eingesetzt, die besser als der Schwellenwert für die gewählte Bewertungsmetrik abschneiden. In diesem Schritt werden Sie ein Python-Skript erstellen, das das Modell auf einer Testmenge unter Verwendung der Receiver Operating Characteristic Area Under the Curve (ROC-AUC)-Metrik bewertet. Die Leistung dieses Modells in Bezug auf diese Metrik wird in einem weiteren Schritt verwendet, um zu entscheiden, ob das Modell registriert und eingesetzt werden sollte. Kopieren Sie den folgenden Code, fügen Sie ihn ein und führen Sie ihn aus, um ein Bewertungsskript zu erstellen, das einen Testdatensatz aufnimmt und die AUC-Metrik generiert.
%%writefile evaluate.py
import json
import logging
import pathlib
import pickle
import tarfile
import numpy as np
import pandas as pd
import xgboost as xgb
from sklearn.metrics import roc_auc_score
logger = logging.getLogger()
logger.setLevel(logging.INFO)
logger.addHandler(logging.StreamHandler())
if __name__ == "__main__":
model_path = "/opt/ml/processing/model/model.tar.gz"
with tarfile.open(model_path) as tar:
tar.extractall(path=".")
logger.debug("Loading xgboost model.")
# The name of the file should match how the model was saved in the training script
model = pickle.load(open("xgboost-model", "rb"))
logger.debug("Reading test data.")
test_local_path = "/opt/ml/processing/test/test.csv"
df_test = pd.read_csv(test_local_path)
# Extract test set target column
y_test = df_test.iloc[:, 0].values
cols_when_train = model.feature_names
# Extract test set feature columns
X = df_test[cols_when_train].copy()
X_test = xgb.DMatrix(X)
logger.info("Generating predictions for test data.")
pred = model.predict(X_test)
# Calculate model evaluation score
logger.debug("Calculating ROC-AUC score.")
auc = roc_auc_score(y_test, pred)
metric_dict = {
"classification_metrics": {"roc_auc": {"value": auc}}
}
# Save model evaluation metrics
output_dir = "/opt/ml/processing/evaluation"
pathlib.Path(output_dir).mkdir(parents=True, exist_ok=True)
logger.info("Writing evaluation report with ROC-AUC: %f", auc)
evaluation_path = f"{output_dir}/evaluation.json"
with open(evaluation_path, "w") as f:
f.write(json.dumps(metric_dict))Kopieren Sie dann den folgenden Codeblock, fügen Sie ihn ein und führen Sie ihn aus, um den Prozessor zu instanzieren und den Schritt SageMaker Pipelines auszuführen, um das Auswertungsscript zu starten. Für die Verarbeitung des benutzerdefinierten Skripts verwenden Sie einen ScriptProcessor. Die Funktion ProcessingStep von SageMaker Pipelines nimmt die folgenden Argumente entgegen: den Prozessor, den S3-Eingabespeicherort für den Testdatensatz, das Modell-Artefakt und den Ausgabespeicherort für die Bewertungsergebnisse. Außerdem wird ein Argument property_files angegeben. Sie verwenden Eigenschaftsdateien, um Informationen aus der Ausgabe des Verarbeitungsschritts zu speichern, welche in diesem Fall eine json-Datei mit der Modell-Leistungsmetrik ist. Wie später im Tutorial gezeigt wird, ist dies besonders nützlich, um festzulegen, wann ein bedingter Schritt ausgeführt werden sollte.
# Upload model evaluation script to S3
s3_client.upload_file(
Filename="evaluate.py", Bucket=write_bucket, Key=f"{write_prefix}/scripts/evaluate.py"
)
eval_processor = ScriptProcessor(
image_uri=training_image,
command=["python3"],
instance_type=predictor_instance_type,
instance_count=predictor_instance_count,
base_job_name=f"{base_job_name_prefix}-model-eval",
sagemaker_session=sess,
role=sagemaker_role,
)
evaluation_report = PropertyFile(
name="FraudDetEvaluationReport",
output_name="evaluation",
path="evaluation.json",
)
# Set model evaluation step
evaluation_step = ProcessingStep(
name="XGBModelEvaluate",
processor=eval_processor,
inputs=[
ProcessingInput(
# Fetch S3 location where train step saved model artifacts
source=train_step.properties.ModelArtifacts.S3ModelArtifacts,
destination="/opt/ml/processing/model",
),
ProcessingInput(
# Fetch S3 location where processing step saved test data
source=process_step.properties.ProcessingOutputConfig.Outputs["test_data"].S3Output.S3Uri,
destination="/opt/ml/processing/test",
),
],
outputs=[
ProcessingOutput(destination=f"{model_eval_output_uri}", output_name="evaluation", source="/opt/ml/processing/evaluation"),
],
code=f"s3://{write_bucket}/{write_prefix}/scripts/evaluate.py",
property_files=[evaluation_report],
)Mit SageMaker Model Registry können Sie Modelle katalogisieren, Modellversionen verwalten und Modelle selektiv in der Produktion einsetzen. Kopieren Sie den folgenden Codeblock, fügen Sie ihn ein und führen Sie ihn aus, um den Modellregistrierungsschritt einzurichten. Die beiden Parameter model_metrics und drift_check_baselines enthalten die zuvor im Tutorial mit der Funktion ClarifyCheckStep berechneten Basismetriken. Sie können auch Ihre eigenen Basismetriken angeben. Die Intention hinter diesen Parametern ist es, eine Möglichkeit zu bieten, die mit einem Modell verknüpften Basislinien zu konfigurieren, so dass sie bei Driftprüfungen und Modellüberwachungsaufgaben verwendet werden können. Bei jeder Ausführung einer Pipeline können Sie diese Parameter mit neu berechneten Basislinien aktualisieren.
# Fetch baseline constraints to record in model registry
model_metrics = ModelMetrics(
bias_post_training=MetricsSource(
s3_uri=model_bias_check_step.properties.CalculatedBaselineConstraints,
content_type="application/json"
),
explainability=MetricsSource(
s3_uri=model_explainability_step.properties.CalculatedBaselineConstraints,
content_type="application/json"
),
)
# Fetch baselines to record in model registry for drift check
drift_check_baselines = DriftCheckBaselines(
bias_post_training_constraints=MetricsSource(
s3_uri=model_bias_check_step.properties.BaselineUsedForDriftCheckConstraints,
content_type="application/json",
),
explainability_constraints=MetricsSource(
s3_uri=model_explainability_step.properties.BaselineUsedForDriftCheckConstraints,
content_type="application/json",
),
explainability_config_file=FileSource(
s3_uri=model_explainability_config.monitoring_analysis_config_uri,
content_type="application/json",
),
)
# Define register model step
register_step = RegisterModel(
name="XGBRegisterModel",
estimator=xgb_estimator,
# Fetching S3 location where train step saved model artifacts
model_data=train_step.properties.ModelArtifacts.S3ModelArtifacts,
content_types=["text/csv"],
response_types=["text/csv"],
inference_instances=[predictor_instance_type],
transform_instances=[predictor_instance_type],
model_package_group_name=model_package_group_name,
approval_status=model_approval_status_param,
# Registering baselines metrics that can be used for model monitoring
model_metrics=model_metrics,
drift_check_baselines=drift_check_baselines
)Mit Amazon SageMaker kann ein registriertes Modell auf verschiedene Arten für Inferenz eingesetzt werden. In diesem Schritt stellen Sie das Modell mittels der Funktion LambdaStep bereit. Auch wenn Sie normalerweise SageMaker Projects für robuste Modellbereitstellungen verwenden sollten, die den bewährten CI/CD-Verfahren folgen, kann es unter bestimmten Umständen sinnvoll sein, LambdaStep für leichtgewichtige Modellbereitstellungen für Entwicklungs-, Test- und interne Endpunkte mit geringem Datenverkehr zu verwenden. Die LambdaStep-Funktion bietet eine native Integration mit AWS Lambda, sodass Sie benutzerdefinierte Logik in Ihrer Pipeline implementieren können, ohne Server bereitstellen oder verwalten zu müssen. Im Kontext von SageMaker Pipelines ermöglicht LambdaStep das Hinzufügen einer AWS-Lambda-Funktion zu Ihren Pipelines, um beliebige Rechenoperationen zu unterstützen, insbesondere leichtgewichtige Vorgänge mit kurzer Dauer. Beachten Sie, dass eine Lambda-Funktion in einem LambdaStep von SageMaker Pipelines auf eine maximale Laufzeit von 10 Minuten begrenzt ist, mit einem veränderbaren Standard-Timeout von 2 Minuten.
Sie haben zwei Wege, einen LambdaStep zu Ihren Pipelines hinzuzufügen. Erstens können Sie den ARN einer vorhandenen Lambda-Funktion angeben, die Sie mit dem AWS Cloud Development Kit (AWS CDK), der AWS-Managementkonsole oder auf andere Weise erstellt haben. Zweitens verfügt das übergeordnete SageMaker Python SDK über eine Lambda-Hilfsklasse, die Sie verwenden können, um eine neue Lambda-Funktion zusammen mit Ihrem anderen Code zu erstellen, der Ihre Pipeline definiert. Sie verwenden die zweite Methode in diesem Tutorial. Kopieren Sie den folgenden Code, fügen Sie ihn ein und führen Sie ihn aus, um die Lambda-Handler-Funktion zu definieren. Dies ist das benutzerdefinierte Python-Skript, das Modellattribute wie den Modellnamen entgegennimmt und an einen Echtzeit-Endpunkt weiterleitet.
%%writefile lambda_deployer.py
"""
Lambda function creates an endpoint configuration and deploys a model to real-time endpoint.
Required parameters for deployment are retrieved from the event object
"""
import json
import boto3
def lambda_handler(event, context):
sm_client = boto3.client("sagemaker")
# Details of the model created in the Pipeline CreateModelStep
model_name = event["model_name"]
model_package_arn = event["model_package_arn"]
endpoint_config_name = event["endpoint_config_name"]
endpoint_name = event["endpoint_name"]
role = event["role"]
instance_type = event["instance_type"]
instance_count = event["instance_count"]
primary_container = {"ModelPackageName": model_package_arn}
# Create model
model = sm_client.create_model(
ModelName=model_name,
PrimaryContainer=primary_container,
ExecutionRoleArn=role
)
# Create endpoint configuration
create_endpoint_config_response = sm_client.create_endpoint_config(
EndpointConfigName=endpoint_config_name,
ProductionVariants=[
{
"VariantName": "Alltraffic",
"ModelName": model_name,
"InitialInstanceCount": instance_count,
"InstanceType": instance_type,
"InitialVariantWeight": 1
}
]
)
# Create endpoint
create_endpoint_response = sm_client.create_endpoint(
EndpointName=endpoint_name,
EndpointConfigName=endpoint_config_name
)Kopieren Sie den folgenden Codeblock, fügen Sie ihn ein und führen Sie ihn aus, um den LambdaStep zu erstellen. Alle Parameter wie Modell, Endpunktname, Typ und Anzahl der Bereitstellungs-Instances werden mit dem Argument inputs angegeben.
# The function name must contain sagemaker
function_name = "sagemaker-fraud-det-demo-lambda-step"
# Define Lambda helper class can be used to create the Lambda function required in the Lambda step
func = Lambda(
function_name=function_name,
execution_role_arn=sagemaker_role,
script="lambda_deployer.py",
handler="lambda_deployer.lambda_handler",
timeout=600,
memory_size=10240,
)
# The inputs used in the lambda handler are passed through the inputs argument in the
# LambdaStep and retrieved via the `event` object within the `lambda_handler` function
lambda_deploy_step = LambdaStep(
name="LambdaStepRealTimeDeploy",
lambda_func=func,
inputs={
"model_name": pipeline_model_name,
"endpoint_config_name": endpoint_config_name,
"endpoint_name": endpoint_name,
"model_package_arn": register_step.steps[0].properties.ModelPackageArn,
"role": sagemaker_role,
"instance_type": deploy_instance_type_param,
"instance_count": deploy_instance_count_param
}
)In diesem Schritt verwenden Sie den ConditionStep, um die Leistung des aktuellen Modells auf der Grundlage der Metrik Area Under Curve (AUC) zu vergleichen. Erst wenn die Leistung größer oder gleich einem Schwellenwert für die AUC ist (hier 0,7), führt die Pipeline Verzerrungs- und Erklärbarkeitsprüfungen durch, registriert das Modell und setzt es ein. Bedingte Schritte wie dieser helfen dabei, die besten Modelle selektiv in der Produktion bereitzustellen. Kopieren Sie den folgenden Code, fügen Sie ihn ein und führen Sie ihn aus, um den bedingten Schritt zu definieren.
# Evaluate model performance on test set
cond_gte = ConditionGreaterThanOrEqualTo(
left=JsonGet(
step_name=evaluation_step.name,
property_file=evaluation_report,
json_path="classification_metrics.roc_auc.value",
),
right=0.7, # Threshold to compare model performance against
)
condition_step = ConditionStep(
name="CheckFraudDetXGBEvaluation",
conditions=[cond_gte],
if_steps=[create_model_step, model_bias_check_step, model_explainability_step, register_step, lambda_deploy_step],
else_steps=[]
)Schritt 4: Erstellen und Ausführen der Pipeline
Nachdem Sie alle Komponentenschritte definiert haben, können Sie sie zu einem SageMaker-Pipelines-Objekt zusammenfügen. Sie brauchen die Reihenfolge der Ausführung nicht anzugeben, da SageMaker Pipelines die Ausführungsreihenfolge automatisch aus den Abhängigkeiten zwischen den Schritten ableitet.
Kopieren Sie den folgenden Codeblock, fügen Sie ihn ein und führen Sie ihn aus, um die Pipeline einzurichten. Die Pipeline-Definition enthält alle Parameter, die Sie in Schritt 2 definiert haben, sowie die Liste der Komponentenschritte. Schritte wie Modell erstellen, Bias- und Erklärbarkeitsprüfungen, Modellregistrierung und Lambda-Einsatz sind in der Pipeline-Definition nicht aufgeführt, da sie nur ausgeführt werden, wenn der bedingte Schritt als wahr bewertet wird. Wenn der bedingte Schritt wahr ist, werden nachfolgende Schritte in der Reihenfolge ihrer angegebenen Eingaben und Ausgaben ausgeführt.
# Create the Pipeline with all component steps and parameters
pipeline = Pipeline(
name=pipeline_name,
parameters=[process_instance_type_param,
train_instance_type_param,
train_instance_count_param,
deploy_instance_type_param,
deploy_instance_count_param,
clarify_instance_type_param,
skip_check_model_bias_param,
register_new_baseline_model_bias_param,
supplied_baseline_constraints_model_bias_param,
skip_check_model_explainability_param,
register_new_baseline_model_explainability_param,
supplied_baseline_constraints_model_explainability_param,
model_approval_status_param],
steps=[
process_step,
train_step,
evaluation_step,
condition_step
],
sagemaker_session=sess
)Kopieren Sie den folgenden Code, fügen Sie ihn ein und führen Sie ihn in einer Zelle in Ihrem Notebook aus. Falls die Pipeline bereits existiert, aktualisiert der Code die Pipeline. Wenn die Pipeline nicht existiert, wird eine neue erstellt. Ignorieren Sie alle SageMaker-SDK-Warnungen wie „Es wurde kein abgeschlossener Trainingsauftrag gefunden, der mit diesem Kalkulator verknüpft ist. Bitte stellen Sie sicher, dass dieser Estimator nur für die Erstellung der Workflow-Konfiguration verwendet wird.“
# Create a new or update existing Pipeline
pipeline.upsert(role_arn=sagemaker_role)
# Full Pipeline description
pipeline_definition = json.loads(pipeline.describe()['PipelineDefinition'])
pipeline_definitionSageMaker kodiert die Pipeline in einem gerichteten azyklischen Graphen (DAG), in dem jeder Knoten einen Schritt darstellt und die Verbindungen zwischen den Knoten Abhängigkeiten repräsentieren. Um die Pipeline-DAG von der SageMaker-Studio-Oberfläche aus zu inspizieren, wählen Sie die Registerkarte SageMaker-Ressourcen im linken Bereich, wählen Sie Pipelines aus der Dropdown-Liste und wählen Sie FraudDetectXGBPipeline, Graph. Sie können erkennen, dass die von Ihnen erstellten Pipeline-Schritte durch Knoten im Diagramm dargestellt werden und die Verbindungen zwischen den Knoten von SageMaker auf der Grundlage der in den Schrittdefinitionen angegebenen Eingaben und Ausgaben abgeleitet wurden.

Führen Sie die Pipeline aus, indem Sie die folgende Codeanweisung ausführen. Pipeline-Ausführungsparameter werden in diesem Schritt als Argumente angegeben. Gehen Sie auf die Registerkarte SageMaker-Ressourcen auf der linken Seite, wählen Sie Pipelines aus der Dropdown-Liste und wählen Sie dann FraudDetectXGBPipeline, Executions. Die aktuelle Ausführung der Pipeline wird aufgelistet.
# Execute Pipeline
start_response = pipeline.start(parameters=dict(
SkipModelBiasCheck=True,
RegisterNewModelBiasBaseline=True,
SkipModelExplainabilityCheck=True,
RegisterNewModelExplainabilityBaseline=True)
)
Um die Ausführung der Pipeline zu überprüfen, wählen Sie die Registerkarte Status. Wenn alle Schritte erfolgreich ausgeführt wurden, erscheinen die Knoten im Diagramm grün.

Wählen Sie in der Benutzeroberfläche von SageMaker Studio die Registerkarte SageMaker-Ressourcen im linken Bereich und wählen Sie Modellregistrierung aus der Dropdown-Liste. Das registrierte Modell wird im linken Fenster unter Modellgruppenname aufgeführt. Wählen Sie den Namen der Modellgruppe, um die Liste der Modellversionen anzuzeigen. Bei jedem Durchlauf der Pipeline wird der Registrierung eine neue Modellversion hinzugefügt, wenn die Modellversion den bedingten Schwellenwert für die Bewertung erfüllt. Wählen Sie eine Modellversion, um Details wie beispielsweise den Modellendpunkt und den Bericht über die Erklärbarkeit des Modells anzuzeigen.

Schritt 5: Testen Sie die Pipeline durch Aufrufen des Endpunkts
In diesem Tutorial erreicht das Modell einen Wert, der über dem gewählten Schwellenwert von 0,7 AUC liegt. Daher registriert der bedingte Schritt das Modell und setzt es an einem Echtzeit-Inferenz-Endpunkt ein.
Wählen Sie in der Oberfläche von SageMaker Studio auf der linken Seite die Registerkarte SageMaker-Ressourcen, wählen Sie Endpunkte , und warten Sie, bis der Status des Endpunkts fraud-detect-xgb-pipeline auf InService wechselt.

Nachdem sich der Status des Endpunkts in InService geändert hat, kopieren Sie den folgenden Code, fügen ihn ein und führen ihn aus, um den Endpunkt aufzurufen und Beispielinferenzen auszuführen. Der Code gibt die Modellvorhersagen für die ersten fünf Stichproben im Testdatensatz zurück.
# Fetch test data to run predictions with the endpoint
test_df = pd.read_csv(f"{processing_output_uri}/test_data/test.csv")
# Create SageMaker Predictor from the deployed endpoint
predictor = sagemaker.predictor.Predictor(endpoint_name,
sagemaker_session=sess,
serializer=CSVSerializer(),
deserializer=CSVDeserializer()
)
# Test endpoint with payload of 5 samples
payload = test_df.drop(["fraud"], axis=1).iloc[:5]
result = predictor.predict(payload.values)
prediction_df = pd.DataFrame()
prediction_df["Prediction"] = result
prediction_df["Label"] = test_df["fraud"].iloc[:5].values
prediction_dfSchritt 6: Bereinigung der Ressourcen
Es ist eine bewährte Methode, Ressourcen zu löschen, die Sie nicht mehr verwenden, damit Ihnen keine unbeabsichtigten Kosten entstehen.
Kopieren Sie den folgenden Codeblock und fügen Sie ihn ein, um die Lambda-Funktion, das Modell, die Endpunktkonfiguration, den Endpunkt und die Pipeline zu löschen, die Sie in diesem Tutorial erstellt haben.
# Delete the Lambda function
func.delete()
# Delete the endpoint
sm_client.delete_endpoint(EndpointName=endpoint_name)
# Delete the EndpointConfig
sm_client.delete_endpoint_config(EndpointConfigName=endpoint_config_name)
# Delete the model
sm_client.delete_model(ModelName=pipeline_model_name)
# Delete the pipeline
sm_client.delete_pipeline(PipelineName=pipeline_name)Um den S3-Bucket zu löschen, machen Sie Folgendes:
- Öffnen Sie die Amazon-S3-Konsole. Wählen Sie in der Navigationsleiste Buckets, sagemaker-<Ihre-Region>-<Ihre-Konto-ID>, und aktivieren Sie dann das Kontrollkästchen neben fraud-detect-demo. Wählen Sie dann Löschen.
- Im Dialogfeld Objekte löschen vergewissern Sie sich, dass Sie das richtige Objekt zum Löschen ausgewählt haben, und geben Sie dauerhaft löschen im Bestätigungsfeld Objekte dauerhaft löschen ein.
- Wenn der Vorgang abgeschlossen und der Bucket leer ist, können Sie den Bucket sagemaker-<Ihre Region>-<Ihre Konton-ID> löschen, indem Sie das gleiche Verfahren erneut durchführen.

Der Datenwissenschaftliche Kernel, der für die Ausführung des Notebook-Images in diesem Tutorial verwendet wird, sammelt Gebühren an, bis Sie entweder den Kernel stoppen oder die folgenden Schritte ausführen, um die Anwendungen zu löschen. Weitere Informationen finden Sie unter Herunterfahren von Ressourcen im Entwicklerhandbuch für Amazon SageMaker.
Gehen Sie wie folgt vor, um die SageMaker-Studio-Anwendungen zu löschen: Wählen Sie in der SageMaker-Studio-Konsole studio-user und löschen Sie dann alle unter Anwendungen aufgeführten Anwendungen, indem Sie Anwendung löschen wählen. Warten Sie, bis der Status auf Gelöscht wechselt.

Wenn Sie in Schritt 1 eine bestehende SageMaker-Studio-Domäne verwendet haben, überspringen Sie den Rest von Schritt 6 und fahren Sie direkt mit dem Abschnitt Fazit fort.
Wenn Sie die CloudFormation-Vorlage in Schritt 1 ausgeführt haben, um eine neue SageMaker-Studio-Domäne zu erstellen, fahren Sie mit den folgenden Schritten fort, um die Domäne, den Benutzer und die von der CloudFormation-Vorlage erstellten Ressourcen zu löschen.
Um die CloudFormation-Konsole zu öffnen, geben Sie CloudFormation in die Suchleiste der AWS-Konsole ein, und wählen Sie CloudFormation aus den Suchergebnissen aus.

Wählen Sie im Bereich CloudFormation die Option Stacks. Wählen Sie in der Dropdown-Liste Status die Option Aktiv. Wählen Sie unter Stackname die Option CFN-SM-IM-Lambda-catalog, um die Seite mit den Stackdetails zu öffnen.

Wählen Sie auf der Seite CFN-SM-IM-Lambda-catalog Stack-Details die Option Löschen, um den Stack zusammen mit den in Schritt 1 erstellten Ressourcen zu löschen.

Zusammenfassung
Herzlichen Glückwunsch! Sie haben das Tutorial Automatisieren von Machine-Learning-Workflows abgeschlossen.
Sie haben erfolgreich Amazon SageMaker Pipelines verwendet, um den gesamten ML-Workflow zu automatisieren, angefangen bei der Datenverarbeitung, dem Modelltraining, der Modellevaluierung, der Überprüfung von Verzerrungen und Erklärbarkeit, der Registrierung bedingter Modelle und der Bereitstellung. Abschließend haben Sie das SageMaker-SDK verwendet, um das Modell an einem Echtzeit-Inferenz-Endpunkt einzusetzen und es mit einer Beispiel-Nutzlast zu testen.
Sie können Ihre Machine-Learning-Reise mit Amazon SageMaker fortsetzen, indem Sie den Abschnitt Nächste Schritte unten befolgen.
Bereitstellung eines Machine Learning-Modells
Trainieren Sie ein Deep-Learning-Modell
Weitere Praxis-Tutorials finden