Información general
En este tutorial, aprenderá a crear y automatizar flujos de trabajo de machine learning (ML) de extremo a extremo con Canalizaciones de Amazon SageMaker, Amazon SageMaker Model Registry y Amazon SageMaker Clarify.
Las Canalizaciones de SageMaker son el primer servicio de integración y entrega continuas (CI/CD) especialmente diseñado para ML. Con las Canalizaciones de SageMaker, puede automatizar diferentes pasos del flujo de trabajo de ML, incluida la carga de datos, la transformación de datos, el entrenamiento, el ajuste, la evaluación y la implementación. SageMaker Model Registry le permite realizar un seguimiento de las versiones del modelo, sus metadatos, como la agrupación de casos de uso, y las referencias de las métricas de rendimiento del modelo en un repositorio central donde es fácil elegir el modelo adecuado para la implementación en función de los requisitos de su negocio. SageMaker Clarify proporciona una mayor visibilidad de sus datos y modelos de entrenamiento para que pueda identificar y limitar el sesgo y explicar las predicciones.
En este tutorial, implementará una canalización de SageMaker para crear, entrenar e implementar un modelo de clasificación binaria XGBoost que predice la probabilidad de que una reclamación de seguro de automóvil sea fraudulenta. Utilizará un conjunto de datos de reclamaciones de seguros de automóviles generado de forma sintética. Las entradas sin procesar son dos tablas de datos de seguros: una tabla de reclamaciones y una tabla de clientes. La tabla de reclamaciones tiene una columna llamada fraude que indica si una reclamación fue fraudulenta o no. Su canalización procesará los datos sin procesar; creará conjuntos de datos de entrenamiento, validación y prueba; y creará y evaluará un modelo de clasificación binaria. Luego utilizará SageMaker Clarify para probar el sesgo y la explicabilidad del modelo y, por último, implementará el modelo para la inferencia.
Lo que logrará
En esta guía, aprenderá a hacer lo siguiente:
- Crear y ejecutar una canalización de SageMaker para automatizar el ciclo de vida de ML de extremo a extremo.
- Generar predicciones mediante el modelo implementado.
Requisitos previos
Antes de comenzar esta guía, necesitará lo siguiente:
- Una cuenta de AWS: si aún no tiene una cuenta, siga la guía de introducción a la Configuración de su entorno de AWS para obtener una descripción general rápida.
Experiencia en AWS
Tiempo de realización
120 minutos
Costo de realización
Consulte los precios de SageMaker para estimar el costo de este tutorial.
Requisitos
Debe iniciar sesión en una cuenta de AWS.
Servicios utilizados
Amazon SageMaker Studio, Canalizaciones de Amazon SageMaker, Amazon SageMaker Clarify, Amazon SageMaker Model Registry
Última actualización
24 de junio de 2022
Implementación
Paso 1: configurar el dominio de Amazon SageMaker Studio
Una cuenta de AWS solo puede tener un dominio de SageMaker Studio por región. Si ya tiene un dominio de SageMaker Studio en la región Este de EE. UU. (Norte de Virginia), siga la guía de configuración de SageMaker Studio para flujos de trabajo de ML a fin de adjuntar las políticas de AWS IAM requeridas a su cuenta de SageMaker Studio; luego omita el paso 1 y continúe directamente con paso 2.
Si no tiene un dominio de SageMaker Studio existente, continúe con el paso 1 a fin de ejecutar una plantilla de AWS CloudFormation que cree un dominio de SageMaker Studio y agregue los permisos necesarios para el resto de este tutorial.
Elija el enlace de la pila de AWS CloudFormation. Este enlace abre la consola de AWS CloudFormation y crea su dominio de SageMaker Studio y un usuario denominado studio-user. También agrega los permisos necesarios a su cuenta de SageMaker Studio. En la consola de CloudFormation, confirme que Este de EE. UU. (Norte de Virginia) sea la región que se muestra en la esquina superior derecha. El nombre de la pila debe ser CFN-SM-IM-Lambda-Catalog y no debe cambiarse. Esta pila tarda unos 10 minutos en crear todos los recursos.
Esta pila asume que ya tiene una VPC pública configurada en su cuenta. Si no tiene una VPC pública, consulte VPC con una única subred pública para obtener información sobre cómo crear una VPC pública.

Seleccione I acknowledge that AWS CloudFormation might create IAM resources (Acepto que AWS CloudFormation podría crear recursos de IAM) y luego elija Create stack (Crear pila).

En el panel de CloudFormation, elija Stacks (Pilas). La pila tarda unos 10 minutos en crearse. Cuando se crea la pila, su estado cambia de CREATE_IN_PROGRESS a CREATE_COMPLETE.

Paso 2: configurar un cuaderno de SageMaker Studio y parametrizar la canalización
En este paso, lanzará un nuevo cuaderno de SageMaker Studio y configurará las variables de SageMaker necesarias para interactuar con Amazon Simple Storage Service (Amazon S3).
Ingrese SageMaker Studio en la barra de búsqueda de la consola de AWS y luego seleccione SageMaker Studio. Elija US East (N. Virginia) (Este de EE. UU. [Norte de Virginia]) de la lista desplegable Region (Región) en la esquina superior derecha de la consola.

En Launch app (Lanzar aplicación), seleccione Studio para abrir SageMaker Studio con el perfil studio-user.

En la barra de navegación de SageMaker Studio, seleccione File (Archivo), New (Nuevo), Notebook (Cuaderno).

En el cuadro de diálogo Set up notebook environment (Configurar entorno de cuaderno), en Image (Imagen), seleccione Data Science (Ciencia de datos). El kernel de Python 3 se selecciona automáticamente. Elija Select (Seleccionar).

El kernel en la esquina superior derecha del cuaderno ahora debería mostrar Python 3 (Data Science) (Python 3 [Ciencia de datos]).

Para importar las bibliotecas requeridas, copie y pegue el siguiente código en una celda de su cuaderno y ejecute la celda.
import pandas as pd
import json
import boto3
import pathlib
import io
import sagemaker
from sagemaker.deserializers import CSVDeserializer
from sagemaker.serializers import CSVSerializer
from sagemaker.xgboost.estimator import XGBoost
from sagemaker.sklearn.processing import SKLearnProcessor
from sagemaker.processing import (
ProcessingInput,
ProcessingOutput,
ScriptProcessor
)
from sagemaker.inputs import TrainingInput
from sagemaker.workflow.pipeline import Pipeline
from sagemaker.workflow.steps import (
ProcessingStep,
TrainingStep,
CreateModelStep
)
from sagemaker.workflow.check_job_config import CheckJobConfig
from sagemaker.workflow.parameters import (
ParameterInteger,
ParameterFloat,
ParameterString,
ParameterBoolean
)
from sagemaker.workflow.clarify_check_step import (
ModelBiasCheckConfig,
ClarifyCheckStep,
ModelExplainabilityCheckConfig
)
from sagemaker.workflow.step_collections import RegisterModel
from sagemaker.workflow.conditions import ConditionGreaterThanOrEqualTo
from sagemaker.workflow.properties import PropertyFile
from sagemaker.workflow.condition_step import ConditionStep
from sagemaker.workflow.functions import JsonGet
from sagemaker.workflow.lambda_step import (
LambdaStep,
LambdaOutput,
LambdaOutputTypeEnum,
)
from sagemaker.lambda_helper import Lambda
from sagemaker.model_metrics import (
MetricsSource,
ModelMetrics,
FileSource
)
from sagemaker.drift_check_baselines import DriftCheckBaselines
from sagemaker.image_uris import retrieveCopie y pegue el siguiente bloque de código en una celda y ejecútelo para configurar los objetos de cliente de SageMaker y S3 mediante los SDK de SageMaker y AWS. Estos objetos son necesarios para permitir que SageMaker realice diversas acciones, como implementar e invocar puntos de conexión, y para interactuar con Amazon S3 y AWS Lambda. El código también configura las ubicaciones de bucket de S3 donde se almacenan los conjuntos de datos sin procesar y procesados y los artefactos del modelo. Tenga en cuenta que los buckets de lectura y escritura están separados. El bucket de lectura es el bucket público de S3 denominado sagemaker-sample-files y contiene los conjuntos de datos sin procesar. El bucket de escritura es el bucket de S3 predeterminado asociado a su cuenta denominado sagemaker-<your- Region>-<your-account-id> y se usará más adelante en este tutorial para almacenar los conjuntos de datos y los artefactos procesados.
# Instantiate AWS services session and client objects
sess = sagemaker.Session()
write_bucket = sess.default_bucket()
write_prefix = "fraud-detect-demo"
region = sess.boto_region_name
s3_client = boto3.client("s3", region_name=region)
sm_client = boto3.client("sagemaker", region_name=region)
sm_runtime_client = boto3.client("sagemaker-runtime")
# Fetch SageMaker execution role
sagemaker_role = sagemaker.get_execution_role()
# S3 locations used for parameterizing the notebook run
read_bucket = "sagemaker-sample-files"
read_prefix = "datasets/tabular/synthetic_automobile_claims"
# S3 location where raw data to be fetched from
raw_data_key = f"s3://{read_bucket}/{read_prefix}"
# S3 location where processed data to be uploaded
processed_data_key = f"{write_prefix}/processed"
# S3 location where train data to be uploaded
train_data_key = f"{write_prefix}/train"
# S3 location where validation data to be uploaded
validation_data_key = f"{write_prefix}/validation"
# S3 location where test data to be uploaded
test_data_key = f"{write_prefix}/test"
# Full S3 paths
claims_data_uri = f"{raw_data_key}/claims.csv"
customers_data_uri = f"{raw_data_key}/customers.csv"
output_data_uri = f"s3://{write_bucket}/{write_prefix}/"
scripts_uri = f"s3://{write_bucket}/{write_prefix}/scripts"
estimator_output_uri = f"s3://{write_bucket}/{write_prefix}/training_jobs"
processing_output_uri = f"s3://{write_bucket}/{write_prefix}/processing_jobs"
model_eval_output_uri = f"s3://{write_bucket}/{write_prefix}/model_eval"
clarify_bias_config_output_uri = f"s3://{write_bucket}/{write_prefix}/model_monitor/bias_config"
clarify_explainability_config_output_uri = f"s3://{write_bucket}/{write_prefix}/model_monitor/explainability_config"
bias_report_output_uri = f"s3://{write_bucket}/{write_prefix}/clarify_output/pipeline/bias"
explainability_report_output_uri = f"s3://{write_bucket}/{write_prefix}/clarify_output/pipeline/explainability"
# Retrieve training image
training_image = retrieve(framework="xgboost", region=region, version="1.3-1")Copie y pegue el siguiente código para establecer los nombres de los diversos componentes de canalización de SageMaker, como el modelo y el punto de conexión, y especifique los tipos y recuentos de instancias de entrenamiento e inferencia. Estos valores se utilizarán para parametrizar su canalización.
# Set names of pipeline objects
pipeline_name = "FraudDetectXGBPipeline"
pipeline_model_name = "fraud-detect-xgb-pipeline"
model_package_group_name = "fraud-detect-xgb-model-group"
base_job_name_prefix = "fraud-detect"
endpoint_config_name = f"{pipeline_model_name}-endpoint-config"
endpoint_name = f"{pipeline_model_name}-endpoint"
# Set data parameters
target_col = "fraud"
# Set instance types and counts
process_instance_type = "ml.c5.xlarge"
train_instance_count = 1
train_instance_type = "ml.m4.xlarge"
predictor_instance_count = 1
predictor_instance_type = "ml.m4.xlarge"
clarify_instance_count = 1
clarify_instance_type = "ml.m4.xlarge"Las Canalizaciones de SageMaker admiten la parametrización, lo que le permite especificar parámetros de entrada en tiempo de ejecución sin cambiar el código de su canalización. Puede usar los módulos disponibles en el módulo sagemaker.workflow.parameters, como ParameterInteger, ParameterFloat, ParameterString y ParameterBoolean para especificar parámetros de canalización de varios tipos de datos. Copie, pegue y ejecute el siguiente código para configurar varios parámetros de entrada, incluidas las configuraciones de SageMaker Clarify.
# Set up pipeline input parameters
# Set processing instance type
process_instance_type_param = ParameterString(
name="ProcessingInstanceType",
default_value=process_instance_type,
)
# Set training instance type
train_instance_type_param = ParameterString(
name="TrainingInstanceType",
default_value=train_instance_type,
)
# Set training instance count
train_instance_count_param = ParameterInteger(
name="TrainingInstanceCount",
default_value=train_instance_count
)
# Set deployment instance type
deploy_instance_type_param = ParameterString(
name="DeployInstanceType",
default_value=predictor_instance_type,
)
# Set deployment instance count
deploy_instance_count_param = ParameterInteger(
name="DeployInstanceCount",
default_value=predictor_instance_count
)
# Set Clarify check instance type
clarify_instance_type_param = ParameterString(
name="ClarifyInstanceType",
default_value=clarify_instance_type,
)
# Set model bias check params
skip_check_model_bias_param = ParameterBoolean(
name="SkipModelBiasCheck",
default_value=False
)
register_new_baseline_model_bias_param = ParameterBoolean(
name="RegisterNewModelBiasBaseline",
default_value=False
)
supplied_baseline_constraints_model_bias_param = ParameterString(
name="ModelBiasSuppliedBaselineConstraints",
default_value=""
)
# Set model explainability check params
skip_check_model_explainability_param = ParameterBoolean(
name="SkipModelExplainabilityCheck",
default_value=False
)
register_new_baseline_model_explainability_param = ParameterBoolean(
name="RegisterNewModelExplainabilityBaseline",
default_value=False
)
supplied_baseline_constraints_model_explainability_param = ParameterString(
name="ModelExplainabilitySuppliedBaselineConstraints",
default_value=""
)
# Set model approval param
model_approval_status_param = ParameterString(
name="ModelApprovalStatus", default_value="Approved"
)Paso 3: crear los componentes de la canalización
Una canalización es una secuencia de pasos que se pueden crear individualmente y luego unir para formar un flujo de trabajo de ML. El siguiente diagrama muestra los pasos de alto nivel de una canalización.
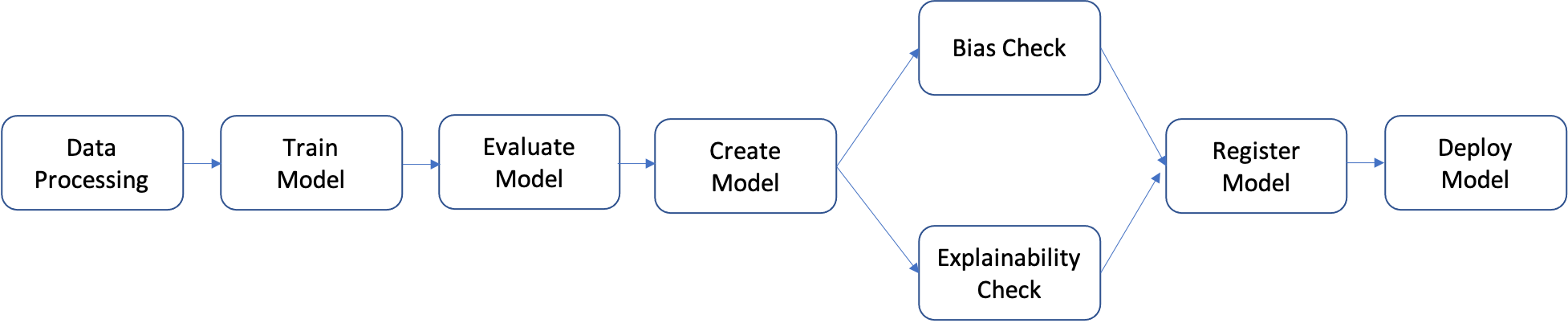
En este tutorial, creará una canalización con los siguientes pasos:
- Paso de procesamiento de datos: ejecuta un trabajo de procesamiento de SageMaker utilizando los datos sin procesar de entrada en S3 y genera divisiones de entrenamiento, validación y prueba en S3.
- Paso de entrenamiento: entrena un modelo XGBoost mediante trabajos de entrenamiento de SageMaker con datos de entrenamiento y validación en S3 como entradas, y almacena el artefacto del modelo entrenado en S3.
- Paso de evaluación: evalúa el modelo en el conjunto de datos de prueba mediante la ejecución de un trabajo de procesamiento de SageMaker utilizando los datos de prueba y el artefacto del modelo en S3 como entradas, y almacena el informe de evaluación del rendimiento del modelo de salida en S3.
- Paso condicional: compara el rendimiento del modelo en el conjunto de datos de prueba con el umbral. Ejecuta un paso predefinido de Canalizaciones de SageMaker utilizando el informe de evaluación del rendimiento del modelo en S3 como entrada y almacena la lista de salida de los pasos de la canalización que se ejecutarán si el rendimiento del modelo es aceptable.
- Paso de creación del modelo: ejecuta un paso predefinido de Canalizaciones de SageMaker utilizando el artefacto del modelo en S3 como entrada y almacena el modelo de salida de SageMaker en S3.
- Paso de comprobación de sesgo: comprueba el sesgo del modelo mediante SageMaker Clarify con los datos de entrenamiento y el artefacto del modelo en S3 como entradas y almacena el informe de sesgo del modelo y las métricas de referencia en S3.
- Paso de explicabilidad del modelo: ejecuta SageMaker Clarify con los datos de entrenamiento y el artefacto del modelo en S3 como entradas, y almacena el informe de explicabilidad del modelo y las métricas de referencia en S3.
- Paso de registro: ejecuta un paso predefinido de Canalizaciones de SageMaker utilizando las métricas de referencia del modelo, el sesgo y la explicabilidad como entradas para registrar el modelo en SageMaker Model Registry.
- Paso de implementación: ejecuta un paso predefinido de Canalizaciones de SageMaker mediante una función de controlador de AWS Lambda, el modelo y la configuración del punto de conexión como entradas para implementar el modelo en un punto de conexión de inferencia en tiempo real de SageMaker.
Las Canalizaciones de SageMaker proporcionan muchos tipos de pasos predefinidos, como pasos para el procesamiento de datos, entrenamiento de modelos, ajuste de modelos y transformación por lotes. Para obtener más información, consulte Pasos de canalización en la Guía para desarrolladores de Amazon SageMaker. En los siguientes pasos, configurará y definirá cada paso de la canalización de forma individual y, a continuación, definirá la propia canalización combinando los pasos de la canalización con los parámetros de entrada.
Paso de procesamiento de datos: en este paso, se prepara un script de Python para ingerir archivos sin procesar; realizar procesamientos como la imputación de valores perdidos y la ingeniería de características; y seleccionar las divisiones de entrenamiento, validación y prueba que se utilizarán para la creación de modelos. Copie, pegue y ejecute el siguiente código para crear el script de procesamiento.
%%writefile preprocessing.py
import argparse
import pathlib
import boto3
import os
import pandas as pd
import logging
from sklearn.model_selection import train_test_split
logger = logging.getLogger()
logger.setLevel(logging.INFO)
logger.addHandler(logging.StreamHandler())
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--train-ratio", type=float, default=0.8)
parser.add_argument("--validation-ratio", type=float, default=0.1)
parser.add_argument("--test-ratio", type=float, default=0.1)
args, _ = parser.parse_known_args()
logger.info("Received arguments {}".format(args))
# Set local path prefix in the processing container
local_dir = "/opt/ml/processing"
input_data_path_claims = os.path.join("/opt/ml/processing/claims", "claims.csv")
input_data_path_customers = os.path.join("/opt/ml/processing/customers", "customers.csv")
logger.info("Reading claims data from {}".format(input_data_path_claims))
df_claims = pd.read_csv(input_data_path_claims)
logger.info("Reading customers data from {}".format(input_data_path_customers))
df_customers = pd.read_csv(input_data_path_customers)
logger.debug("Formatting column names.")
# Format column names
df_claims = df_claims.rename({c : c.lower().strip().replace(' ', '_') for c in df_claims.columns}, axis = 1)
df_customers = df_customers.rename({c : c.lower().strip().replace(' ', '_') for c in df_customers.columns}, axis = 1)
logger.debug("Joining datasets.")
# Join datasets
df_data = df_claims.merge(df_customers, on = 'policy_id', how = 'left')
# Drop selected columns not required for model building
df_data = df_data.drop(['customer_zip'], axis = 1)
# Select Ordinal columns
ordinal_cols = ["police_report_available", "policy_liability", "customer_education"]
# Select categorical columns and filling with na
cat_cols_all = list(df_data.select_dtypes('object').columns)
cat_cols = [c for c in cat_cols_all if c not in ordinal_cols]
df_data[cat_cols] = df_data[cat_cols].fillna('na')
logger.debug("One-hot encoding categorical columns.")
# One-hot encoding categorical columns
df_data = pd.get_dummies(df_data, columns = cat_cols)
logger.debug("Encoding ordinal columns.")
# Ordinal encoding
mapping = {
"Yes": "1",
"No": "0"
}
df_data['police_report_available'] = df_data['police_report_available'].map(mapping)
df_data['police_report_available'] = df_data['police_report_available'].astype(float)
mapping = {
"15/30": "0",
"25/50": "1",
"30/60": "2",
"100/200": "3"
}
df_data['policy_liability'] = df_data['policy_liability'].map(mapping)
df_data['policy_liability'] = df_data['policy_liability'].astype(float)
mapping = {
"Below High School": "0",
"High School": "1",
"Associate": "2",
"Bachelor": "3",
"Advanced Degree": "4"
}
df_data['customer_education'] = df_data['customer_education'].map(mapping)
df_data['customer_education'] = df_data['customer_education'].astype(float)
df_processed = df_data.copy()
df_processed.columns = [c.lower() for c in df_data.columns]
df_processed = df_processed.drop(["policy_id", "customer_gender_unkown"], axis=1)
# Split into train, validation, and test sets
train_ratio = args.train_ratio
val_ratio = args.validation_ratio
test_ratio = args.test_ratio
logger.debug("Splitting data into train, validation, and test sets")
y = df_processed['fraud']
X = df_processed.drop(['fraud'], axis = 1)
X_train_val, X_test, y_train_val, y_test = train_test_split(X, y, test_size=test_ratio, random_state=42)
X_train, X_val, y_train, y_val = train_test_split(X_train_val, y_train_val, test_size=val_ratio, random_state=42)
train_df = pd.concat([y_train, X_train], axis = 1)
val_df = pd.concat([y_val, X_val], axis = 1)
test_df = pd.concat([y_test, X_test], axis = 1)
dataset_df = pd.concat([y, X], axis = 1)
logger.info("Train data shape after preprocessing: {}".format(train_df.shape))
logger.info("Validation data shape after preprocessing: {}".format(val_df.shape))
logger.info("Test data shape after preprocessing: {}".format(test_df.shape))
# Save processed datasets to the local paths in the processing container.
# SageMaker will upload the contents of these paths to S3 bucket
logger.debug("Writing processed datasets to container local path.")
train_output_path = os.path.join(f"{local_dir}/train", "train.csv")
validation_output_path = os.path.join(f"{local_dir}/val", "validation.csv")
test_output_path = os.path.join(f"{local_dir}/test", "test.csv")
full_processed_output_path = os.path.join(f"{local_dir}/full", "dataset.csv")
logger.info("Saving train data to {}".format(train_output_path))
train_df.to_csv(train_output_path, index=False)
logger.info("Saving validation data to {}".format(validation_output_path))
val_df.to_csv(validation_output_path, index=False)
logger.info("Saving test data to {}".format(test_output_path))
test_df.to_csv(test_output_path, index=False)
logger.info("Saving full processed data to {}".format(full_processed_output_path))
dataset_df.to_csv(full_processed_output_path, index=False)
A continuación, copie, pegue y ejecute el siguiente bloque de código para crear las instancias del procesador y el paso de Canalizaciones de SageMaker a fin de ejecutar el script de procesamiento. Dado que el script de procesamiento está escrito en Pandas, se usa un SKLearnProcessor. La función ProcessingStep de Canalizaciones de SageMaker toma los siguientes argumentos: el procesador, las ubicaciones S3 de entrada para conjuntos de datos sin procesar y las ubicaciones S3 de salida para guardar conjuntos de datos procesados. Los argumentos adicionales, como el entrenamiento, la validación y las proporciones de división de prueba, se proporcionan a través del argumento job_arguments.
from sagemaker.workflow.pipeline_context import PipelineSession
# Upload processing script to S3
s3_client.upload_file(
Filename="preprocessing.py", Bucket=write_bucket, Key=f"{write_prefix}/scripts/preprocessing.py"
)
# Define the SKLearnProcessor configuration
sklearn_processor = SKLearnProcessor(
framework_version="0.23-1",
role=sagemaker_role,
instance_count=1,
instance_type=process_instance_type,
base_job_name=f"{base_job_name_prefix}-processing",
)
# Define pipeline processing step
process_step = ProcessingStep(
name="DataProcessing",
processor=sklearn_processor,
inputs=[
ProcessingInput(source=claims_data_uri, destination="/opt/ml/processing/claims"),
ProcessingInput(source=customers_data_uri, destination="/opt/ml/processing/customers")
],
outputs=[
ProcessingOutput(destination=f"{processing_output_uri}/train_data", output_name="train_data", source="/opt/ml/processing/train"),
ProcessingOutput(destination=f"{processing_output_uri}/validation_data", output_name="validation_data", source="/opt/ml/processing/val"),
ProcessingOutput(destination=f"{processing_output_uri}/test_data", output_name="test_data", source="/opt/ml/processing/test"),
ProcessingOutput(destination=f"{processing_output_uri}/processed_data", output_name="processed_data", source="/opt/ml/processing/full")
],
job_arguments=[
"--train-ratio", "0.8",
"--validation-ratio", "0.1",
"--test-ratio", "0.1"
],
code=f"s3://{write_bucket}/{write_prefix}/scripts/preprocessing.py"
)Copie, pegue y ejecute el siguiente bloque de código para preparar el script de entrenamiento. Este script encapsula la lógica de entrenamiento para el clasificador binario XGBoost. Los hiperparámetros utilizados en el entrenamiento del modelo se proporcionan más adelante en el tutorial a través de la definición del paso de entrenamiento.
%%writefile xgboost_train.py
import argparse
import os
import joblib
import json
import pandas as pd
import xgboost as xgb
from sklearn.metrics import roc_auc_score
if __name__ == "__main__":
parser = argparse.ArgumentParser()
# Hyperparameters and algorithm parameters are described here
parser.add_argument("--num_round", type=int, default=100)
parser.add_argument("--max_depth", type=int, default=3)
parser.add_argument("--eta", type=float, default=0.2)
parser.add_argument("--subsample", type=float, default=0.9)
parser.add_argument("--colsample_bytree", type=float, default=0.8)
parser.add_argument("--objective", type=str, default="binary:logistic")
parser.add_argument("--eval_metric", type=str, default="auc")
parser.add_argument("--nfold", type=int, default=3)
parser.add_argument("--early_stopping_rounds", type=int, default=3)
# SageMaker specific arguments. Defaults are set in the environment variables
# Set location of input training data
parser.add_argument("--train_data_dir", type=str, default=os.environ.get("SM_CHANNEL_TRAIN"))
# Set location of input validation data
parser.add_argument("--validation_data_dir", type=str, default=os.environ.get("SM_CHANNEL_VALIDATION"))
# Set location where trained model will be stored. Default set by SageMaker, /opt/ml/model
parser.add_argument("--model_dir", type=str, default=os.environ.get("SM_MODEL_DIR"))
# Set location where model artifacts will be stored. Default set by SageMaker, /opt/ml/output/data
parser.add_argument("--output_data_dir", type=str, default=os.environ.get("SM_OUTPUT_DATA_DIR"))
args = parser.parse_args()
data_train = pd.read_csv(f"{args.train_data_dir}/train.csv")
train = data_train.drop("fraud", axis=1)
label_train = pd.DataFrame(data_train["fraud"])
dtrain = xgb.DMatrix(train, label=label_train)
data_validation = pd.read_csv(f"{args.validation_data_dir}/validation.csv")
validation = data_validation.drop("fraud", axis=1)
label_validation = pd.DataFrame(data_validation["fraud"])
dvalidation = xgb.DMatrix(validation, label=label_validation)
# Choose XGBoost model hyperparameters
params = {"max_depth": args.max_depth,
"eta": args.eta,
"objective": args.objective,
"subsample" : args.subsample,
"colsample_bytree":args.colsample_bytree
}
num_boost_round = args.num_round
nfold = args.nfold
early_stopping_rounds = args.early_stopping_rounds
# Cross-validate train XGBoost model
cv_results = xgb.cv(
params=params,
dtrain=dtrain,
num_boost_round=num_boost_round,
nfold=nfold,
early_stopping_rounds=early_stopping_rounds,
metrics=["auc"],
seed=42,
)
model = xgb.train(params=params, dtrain=dtrain, num_boost_round=len(cv_results))
train_pred = model.predict(dtrain)
validation_pred = model.predict(dvalidation)
train_auc = roc_auc_score(label_train, train_pred)
validation_auc = roc_auc_score(label_validation, validation_pred)
print(f"[0]#011train-auc:{train_auc:.2f}")
print(f"[0]#011validation-auc:{validation_auc:.2f}")
metrics_data = {"hyperparameters" : params,
"binary_classification_metrics": {"validation:auc": {"value": validation_auc},
"train:auc": {"value": train_auc}
}
}
# Save the evaluation metrics to the location specified by output_data_dir
metrics_location = args.output_data_dir + "/metrics.json"
# Save the trained model to the location specified by model_dir
model_location = args.model_dir + "/xgboost-model"
with open(metrics_location, "w") as f:
json.dump(metrics_data, f)
with open(model_location, "wb") as f:
joblib.dump(model, f)Configure el entrenamiento del modelo con un estimador XGBoost de SageMaker y la función TrainingStep de las Canalizaciones de SageMaker.
# Set XGBoost model hyperparameters
hyperparams = {
"eval_metric" : "auc",
"objective": "binary:logistic",
"num_round": "5",
"max_depth":"5",
"subsample":"0.75",
"colsample_bytree":"0.75",
"eta":"0.5"
}
# Set XGBoost estimator
xgb_estimator = XGBoost(
entry_point="xgboost_train.py",
output_path=estimator_output_uri,
code_location=estimator_output_uri,
hyperparameters=hyperparams,
role=sagemaker_role,
# Fetch instance type and count from pipeline parameters
instance_count=train_instance_count,
instance_type=train_instance_type,
framework_version="1.3-1"
)
# Access the location where the preceding processing step saved train and validation datasets
# Pipeline step properties can give access to outputs which can be used in succeeding steps
s3_input_train = TrainingInput(
s3_data=process_step.properties.ProcessingOutputConfig.Outputs["train_data"].S3Output.S3Uri,
content_type="csv",
s3_data_type="S3Prefix"
)
s3_input_validation = TrainingInput(
s3_data=process_step.properties.ProcessingOutputConfig.Outputs["validation_data"].S3Output.S3Uri,
content_type="csv",
s3_data_type="S3Prefix"
)
# Set pipeline training step
train_step = TrainingStep(
name="XGBModelTraining",
estimator=xgb_estimator,
inputs={
"train":s3_input_train, # Train channel
"validation": s3_input_validation # Validation channel
}
)Copie, pegue y ejecute el siguiente bloque de código, que se usará para crear un modelo de SageMaker mediante la función CreateModelStep de las Canalizaciones de SageMaker. Este paso utiliza el resultado del paso de entrenamiento a fin de empaquetar el modelo para su implementación. Tenga en cuenta que el valor del argumento de tipo de instancia se pasa mediante el parámetro de Canalizaciones de SageMaker que definió anteriormente en el tutorial.
# Create a SageMaker model
model = sagemaker.model.Model(
image_uri=training_image,
model_data=train_step.properties.ModelArtifacts.S3ModelArtifacts,
sagemaker_session=sess,
role=sagemaker_role
)
# Specify model deployment instance type
inputs = sagemaker.inputs.CreateModelInput(instance_type=deploy_instance_type_param)
create_model_step = CreateModelStep(name="FraudDetModel", model=model, inputs=inputs)En un flujo de trabajo de ML, es importante evaluar un modelo entrenado en busca de posibles sesgos y comprender cómo las diversas características en los datos de entrada afectan la predicción del modelo. Las Canalizaciones de SageMaker proporcionan una función ClarifyCheckStep que se puede utilizar para realizar tres tipos de comprobaciones: comprobación de sesgo de datos (antes del entrenamiento), comprobación de sesgo del modelo (después del entrenamiento) y comprobación de explicabilidad del modelo. Para reducir el tiempo de ejecución, en este tutorial solo implementará las comprobaciones de sesgo y explicabilidad. Copie, pegue y ejecute el siguiente bloque de código a fin de configurar SageMaker Clarify para la comprobación de sesgo del modelo. Tenga en cuenta que este paso selecciona activos, como los datos de entrenamiento y el modelo de SageMaker creado en los pasos anteriores, a través del atributo properties. Cuando se ejecuta la canalización, este paso no se inicia hasta que los pasos que proporcionan las entradas terminan de ejecutarse. Para obtener más detalles, consulte Dependencia de datos entre pasos en la Guía para desarrolladores de Amazon SageMaker. Para administrar los costos y el tiempo de ejecución del tutorial, la función ModelBiasCheckConfig está configurada con el fin de calcular solo una métrica de sesgo, DPPL. Para obtener más información sobre las métricas de sesgo disponibles en SageMaker Clarify, consulte Medir los datos posteriores al entrenamiento y el sesgo del modelo en la Guía para desarrolladores de Amazon SageMaker.
# Set up common configuration parameters to be used across multiple steps
check_job_config = CheckJobConfig(
role=sagemaker_role,
instance_count=1,
instance_type=clarify_instance_type,
volume_size_in_gb=30,
sagemaker_session=sess,
)
# Set up configuration of data to be used for model bias check
model_bias_data_config = sagemaker.clarify.DataConfig(
# Fetch S3 location where processing step saved train data
s3_data_input_path=process_step.properties.ProcessingOutputConfig.Outputs["train_data"].S3Output.S3Uri,
s3_output_path=bias_report_output_uri,
label=target_col,
dataset_type="text/csv",
s3_analysis_config_output_path=clarify_bias_config_output_uri
)
# Set up details of the trained model to be checked for bias
model_config = sagemaker.clarify.ModelConfig(
# Pull model name from model creation step
model_name=create_model_step.properties.ModelName,
instance_count=train_instance_count,
instance_type=train_instance_type
)
# Set up column and categories that are to be checked for bias
model_bias_config = sagemaker.clarify.BiasConfig(
label_values_or_threshold=[0],
facet_name="customer_gender_female",
facet_values_or_threshold=[1]
)
# Set up model predictions configuration to get binary labels from probabilities
model_predictions_config = sagemaker.clarify.ModelPredictedLabelConfig(probability_threshold=0.5)
model_bias_check_config = ModelBiasCheckConfig(
data_config=model_bias_data_config,
data_bias_config=model_bias_config,
model_config=model_config,
model_predicted_label_config=model_predictions_config,
methods=["DPPL"]
)
# Set up pipeline model bias check step
model_bias_check_step = ClarifyCheckStep(
name="ModelBiasCheck",
clarify_check_config=model_bias_check_config,
check_job_config=check_job_config,
skip_check=skip_check_model_bias_param,
register_new_baseline=register_new_baseline_model_bias_param,
supplied_baseline_constraints=supplied_baseline_constraints_model_bias_param
)Copie, pegue y ejecute el siguiente bloque de código para configurar las comprobaciones de explicabilidad del modelo. Este paso proporciona información como la importancia de las características (cómo las características de entrada afectan las predicciones del modelo).
# Set configuration of data to be used for model explainability check
model_explainability_data_config = sagemaker.clarify.DataConfig(
# Fetch S3 location where processing step saved train data
s3_data_input_path=process_step.properties.ProcessingOutputConfig.Outputs["train_data"].S3Output.S3Uri,
s3_output_path=explainability_report_output_uri,
label=target_col,
dataset_type="text/csv",
s3_analysis_config_output_path=clarify_explainability_config_output_uri
)
# Set SHAP configuration for Clarify to compute global and local SHAP values for feature importance
shap_config = sagemaker.clarify.SHAPConfig(
seed=42,
num_samples=100,
agg_method="mean_abs",
save_local_shap_values=True
)
model_explainability_config = ModelExplainabilityCheckConfig(
data_config=model_explainability_data_config,
model_config=model_config,
explainability_config=shap_config
)
# Set pipeline model explainability check step
model_explainability_step = ClarifyCheckStep(
name="ModelExplainabilityCheck",
clarify_check_config=model_explainability_config,
check_job_config=check_job_config,
skip_check=skip_check_model_explainability_param,
register_new_baseline=register_new_baseline_model_explainability_param,
supplied_baseline_constraints=supplied_baseline_constraints_model_explainability_param
)En los sistemas de producción, no se implementan todos los modelos entrenados. Por lo general, solo se implementan los modelos que funcionan mejor que el umbral para una métrica de evaluación elegida. En este paso, creará un script de Python que puntúa el modelo en un conjunto de prueba mediante la métrica del área bajo la curva de características operativas del receptor (ROC-AUC). El rendimiento del modelo frente a esta métrica se usa en un paso posterior para determinar si el modelo debe registrarse e implementarse. Copie, pegue y ejecute el siguiente código para crear un script de evaluación que ingiera un conjunto de datos de prueba y genere la métrica del AUC.
%%writefile evaluate.py
import json
import logging
import pathlib
import pickle
import tarfile
import numpy as np
import pandas as pd
import xgboost as xgb
from sklearn.metrics import roc_auc_score
logger = logging.getLogger()
logger.setLevel(logging.INFO)
logger.addHandler(logging.StreamHandler())
if __name__ == "__main__":
model_path = "/opt/ml/processing/model/model.tar.gz"
with tarfile.open(model_path) as tar:
tar.extractall(path=".")
logger.debug("Loading xgboost model.")
# The name of the file should match how the model was saved in the training script
model = pickle.load(open("xgboost-model", "rb"))
logger.debug("Reading test data.")
test_local_path = "/opt/ml/processing/test/test.csv"
df_test = pd.read_csv(test_local_path)
# Extract test set target column
y_test = df_test.iloc[:, 0].values
cols_when_train = model.feature_names
# Extract test set feature columns
X = df_test[cols_when_train].copy()
X_test = xgb.DMatrix(X)
logger.info("Generating predictions for test data.")
pred = model.predict(X_test)
# Calculate model evaluation score
logger.debug("Calculating ROC-AUC score.")
auc = roc_auc_score(y_test, pred)
metric_dict = {
"classification_metrics": {"roc_auc": {"value": auc}}
}
# Save model evaluation metrics
output_dir = "/opt/ml/processing/evaluation"
pathlib.Path(output_dir).mkdir(parents=True, exist_ok=True)
logger.info("Writing evaluation report with ROC-AUC: %f", auc)
evaluation_path = f"{output_dir}/evaluation.json"
with open(evaluation_path, "w") as f:
f.write(json.dumps(metric_dict))A continuación, copie, pegue y ejecute el siguiente bloque de código para crear las instancias del procesador y el paso de Canalizaciones de SageMaker a fin de ejecutar el script de evaluación. Para procesar el script personalizado, se utiliza un ScriptProcessor. La función ProcessingStep de Canalizaciones de SageMaker toma los siguientes argumentos: el procesador, la ubicación de entrada de S3 para el conjunto de datos de prueba, el artefacto del modelo y la ubicación de salida para almacenar los resultados de la evaluación. Además, se proporciona un argumento property_files. Los archivos de propiedades se utilizan para almacenar información del resultado del paso de procesamiento, que en este caso es un archivo json con la métrica de rendimiento del modelo. Como se muestra más adelante en el tutorial, esto es particularmente útil para determinar cuándo se debe ejecutar un paso condicional.
# Upload model evaluation script to S3
s3_client.upload_file(
Filename="evaluate.py", Bucket=write_bucket, Key=f"{write_prefix}/scripts/evaluate.py"
)
eval_processor = ScriptProcessor(
image_uri=training_image,
command=["python3"],
instance_type=predictor_instance_type,
instance_count=predictor_instance_count,
base_job_name=f"{base_job_name_prefix}-model-eval",
sagemaker_session=sess,
role=sagemaker_role,
)
evaluation_report = PropertyFile(
name="FraudDetEvaluationReport",
output_name="evaluation",
path="evaluation.json",
)
# Set model evaluation step
evaluation_step = ProcessingStep(
name="XGBModelEvaluate",
processor=eval_processor,
inputs=[
ProcessingInput(
# Fetch S3 location where train step saved model artifacts
source=train_step.properties.ModelArtifacts.S3ModelArtifacts,
destination="/opt/ml/processing/model",
),
ProcessingInput(
# Fetch S3 location where processing step saved test data
source=process_step.properties.ProcessingOutputConfig.Outputs["test_data"].S3Output.S3Uri,
destination="/opt/ml/processing/test",
),
],
outputs=[
ProcessingOutput(destination=f"{model_eval_output_uri}", output_name="evaluation", source="/opt/ml/processing/evaluation"),
],
code=f"s3://{write_bucket}/{write_prefix}/scripts/evaluate.py",
property_files=[evaluation_report],
)Con SageMaker Model Registry, puede catalogar modelos, administrar versiones de modelos e implementar modelos de forma selectiva en producción. Copie, pegue y ejecute el siguiente bloque de código para configurar el paso de registro del modelo. Los dos parámetros, model_metrics y drift_check_baselines, contienen métricas de referencia calculadas previamente en el tutorial por la función ClarifyCheckStep. También puede proporcionar sus propias métricas de referencia personalizadas. La intención detrás de estos parámetros es proporcionar una forma de configurar las referencias asociadas con un modelo para que puedan usarse en las comprobaciones de desviación y los trabajos de monitoreo del modelo. Cada vez que se ejecuta una canalización, puede optar por actualizar estos parámetros con referencias recién calculadas.
# Fetch baseline constraints to record in model registry
model_metrics = ModelMetrics(
bias_post_training=MetricsSource(
s3_uri=model_bias_check_step.properties.CalculatedBaselineConstraints,
content_type="application/json"
),
explainability=MetricsSource(
s3_uri=model_explainability_step.properties.CalculatedBaselineConstraints,
content_type="application/json"
),
)
# Fetch baselines to record in model registry for drift check
drift_check_baselines = DriftCheckBaselines(
bias_post_training_constraints=MetricsSource(
s3_uri=model_bias_check_step.properties.BaselineUsedForDriftCheckConstraints,
content_type="application/json",
),
explainability_constraints=MetricsSource(
s3_uri=model_explainability_step.properties.BaselineUsedForDriftCheckConstraints,
content_type="application/json",
),
explainability_config_file=FileSource(
s3_uri=model_explainability_config.monitoring_analysis_config_uri,
content_type="application/json",
),
)
# Define register model step
register_step = RegisterModel(
name="XGBRegisterModel",
estimator=xgb_estimator,
# Fetching S3 location where train step saved model artifacts
model_data=train_step.properties.ModelArtifacts.S3ModelArtifacts,
content_types=["text/csv"],
response_types=["text/csv"],
inference_instances=[predictor_instance_type],
transform_instances=[predictor_instance_type],
model_package_group_name=model_package_group_name,
approval_status=model_approval_status_param,
# Registering baselines metrics that can be used for model monitoring
model_metrics=model_metrics,
drift_check_baselines=drift_check_baselines
)Con Amazon SageMaker, un modelo registrado se puede implementar para la inferencia de varias maneras. En este paso, se implementa el modelo mediante la función LambdaStep. Aunque, por lo general, debe usar SageMaker Projects para implementaciones sólidas de modelos que sigan las prácticas recomendadas de CI/CD, puede haber circunstancias en las que tenga sentido usar LambdaStep para implementaciones de modelos livianos para desarrollo, pruebas y puntos de conexión internos que atienden volúmenes de tráfico bajos. La función LambdaStep proporciona una integración nativa con AWS Lambda, por lo que puede implementar una lógica personalizada en su canalización sin aprovisionar ni administrar servidores. En el contexto de las Canalizaciones de SageMaker, LambdaStep lo habilita para agregar una función de AWS Lambda a sus canalizaciones para admitir operaciones informáticas arbitrarias, especialmente operaciones ligeras que tienen una duración corta. Tenga en cuenta que en un LambdaStep de Canalizaciones de SageMaker, una función Lambda está limitada a un tiempo de ejecución máximo de 10 minutos, con un tiempo de espera predeterminado modificable de 2 minutos.
Tiene dos formas de agregar un LambdaStep a sus canalizaciones. En primer lugar, puede proporcionar el ARN de una función Lambda existente que haya creado con el AWS Cloud Development Kit (AWS CDK), la consola de administración de AWS o de otro modo. En segundo lugar, el SDK para Python de SageMaker de alto nivel tiene una clase de ventaja auxiliar de Lambda que puede usar para crear una nueva función Lambda junto con su otro código que define la canalización. Se utiliza el segundo método en este tutorial. Copie, pegue y ejecute el siguiente código para definir la función del controlador de Lambda. Este es el script de Python personalizado que toma los atributos del modelo, como el nombre del modelo, y se implementa en un punto de conexión en tiempo real.
%%writefile lambda_deployer.py
"""
Lambda function creates an endpoint configuration and deploys a model to real-time endpoint.
Required parameters for deployment are retrieved from the event object
"""
import json
import boto3
def lambda_handler(event, context):
sm_client = boto3.client("sagemaker")
# Details of the model created in the Pipeline CreateModelStep
model_name = event["model_name"]
model_package_arn = event["model_package_arn"]
endpoint_config_name = event["endpoint_config_name"]
endpoint_name = event["endpoint_name"]
role = event["role"]
instance_type = event["instance_type"]
instance_count = event["instance_count"]
primary_container = {"ModelPackageName": model_package_arn}
# Create model
model = sm_client.create_model(
ModelName=model_name,
PrimaryContainer=primary_container,
ExecutionRoleArn=role
)
# Create endpoint configuration
create_endpoint_config_response = sm_client.create_endpoint_config(
EndpointConfigName=endpoint_config_name,
ProductionVariants=[
{
"VariantName": "Alltraffic",
"ModelName": model_name,
"InitialInstanceCount": instance_count,
"InstanceType": instance_type,
"InitialVariantWeight": 1
}
]
)
# Create endpoint
create_endpoint_response = sm_client.create_endpoint(
EndpointName=endpoint_name,
EndpointConfigName=endpoint_config_name
)Copie, pegue y ejecute el siguiente bloque de código para crear el LambdaStep. Todos los parámetros, como el modelo, el nombre del punto de conexión y el tipo y recuento de instancias de implementación, se proporcionan mediante el argumento de inputs.
# The function name must contain sagemaker
function_name = "sagemaker-fraud-det-demo-lambda-step"
# Define Lambda helper class can be used to create the Lambda function required in the Lambda step
func = Lambda(
function_name=function_name,
execution_role_arn=sagemaker_role,
script="lambda_deployer.py",
handler="lambda_deployer.lambda_handler",
timeout=600,
memory_size=10240,
)
# The inputs used in the lambda handler are passed through the inputs argument in the
# LambdaStep and retrieved via the `event` object within the `lambda_handler` function
lambda_deploy_step = LambdaStep(
name="LambdaStepRealTimeDeploy",
lambda_func=func,
inputs={
"model_name": pipeline_model_name,
"endpoint_config_name": endpoint_config_name,
"endpoint_name": endpoint_name,
"model_package_arn": register_step.steps[0].properties.ModelPackageArn,
"role": sagemaker_role,
"instance_type": deploy_instance_type_param,
"instance_count": deploy_instance_count_param
}
)En este paso, se utiliza ConditionStep para comparar el rendimiento del modelo actual en función de la métrica del área bajo la curva (AUC). Solo si el rendimiento es superior o igual a un umbral del AUC (aquí elegido como 0,7), la canalización realizará comprobaciones de sesgo y explicabilidad, registrará el modelo y lo implementará. Los pasos condicionales como este ayudan en la implementación selectiva de los mejores modelos en producción. Copie, pegue y ejecute el siguiente código para definir el paso condicional.
# Evaluate model performance on test set
cond_gte = ConditionGreaterThanOrEqualTo(
left=JsonGet(
step_name=evaluation_step.name,
property_file=evaluation_report,
json_path="classification_metrics.roc_auc.value",
),
right=0.7, # Threshold to compare model performance against
)
condition_step = ConditionStep(
name="CheckFraudDetXGBEvaluation",
conditions=[cond_gte],
if_steps=[create_model_step, model_bias_check_step, model_explainability_step, register_step, lambda_deploy_step],
else_steps=[]
)Paso 4: crear y ejecutar la canalización
Después de definir todos los pasos de componentes, puede ensamblarlos en un objeto de Canalizaciones de SageMaker. No es necesario que especifique el orden de ejecución, ya que las Canalizaciones de SageMaker infieren automáticamente la secuencia de ejecución en función de las dependencias entre los pasos.
Copie, pegue y ejecute el siguiente código para configurar la canalización. La definición de la canalización toma todos los parámetros que definió en el paso 2 y la lista de pasos de componentes. Pasos como la creación del modelo, las comprobaciones de sesgo y explicabilidad, el registro del modelo y la implementación de lambda no se enumeran en la definición de canalización porque no se ejecutan a menos que el paso condicional se evalúe como verdadero. Si el paso condicional es verdadero, los pasos subsiguientes se ejecutan en orden según sus entradas y salidas especificadas.
# Create the Pipeline with all component steps and parameters
pipeline = Pipeline(
name=pipeline_name,
parameters=[process_instance_type_param,
train_instance_type_param,
train_instance_count_param,
deploy_instance_type_param,
deploy_instance_count_param,
clarify_instance_type_param,
skip_check_model_bias_param,
register_new_baseline_model_bias_param,
supplied_baseline_constraints_model_bias_param,
skip_check_model_explainability_param,
register_new_baseline_model_explainability_param,
supplied_baseline_constraints_model_explainability_param,
model_approval_status_param],
steps=[
process_step,
train_step,
evaluation_step,
condition_step
],
sagemaker_session=sess
)Copie, pegue y ejecute el siguiente código en una celda de su cuaderno. Si la canalización ya existe, el código actualiza la canalización. Si la canalización no existe, crea una nueva. Ignore las advertencias del SDK de SageMaker como “No finished training job found associated with this estimator. Please make sure this estimator is only used for building workflow config” (No se encontró ningún trabajo de entrenamiento terminado asociado con este estimador. Asegúrese de que este estimador solo se use para crear la configuración del flujo de trabajo).
# Create a new or update existing Pipeline
pipeline.upsert(role_arn=sagemaker_role)
# Full Pipeline description
pipeline_definition = json.loads(pipeline.describe()['PipelineDefinition'])
pipeline_definitionSageMaker codifica la canalización en un gráfico acíclico dirigido (DAG), donde cada nodo representa un paso y las conexiones entre los nodos representan dependencias. Para inspeccionar el DAG de la canalización desde la interfaz de SageMaker Studio, seleccione la pestaña SageMaker Resources (Recursos de SageMaker) en el panel izquierdo, seleccione Pipelines (Canalizaciones) en la lista desplegable y luego elija FraudDetectXGBPipeline, Graph (Gráfico). Puede ver que los pasos de canalización que creó están representados por nodos en el gráfico y SageMaker infirió las conexiones entre los nodos en función de las entradas y salidas proporcionadas en las definiciones de los pasos.

Ejecute la canalización mediante la siguiente instrucción de código. Los parámetros de ejecución de la canalización se proporcionan como argumentos en este paso. Vaya a la pestaña SageMaker Resources (Recursos de SageMaker) en el panel izquierdo, seleccione Pipelines (Canalizaciones) en la lista desplegable y luego elija FraudDetectXGBPipeline, Executions (Ejecuciones). Se muestra la ejecución actual de la canalización.
# Execute Pipeline
start_response = pipeline.start(parameters=dict(
SkipModelBiasCheck=True,
RegisterNewModelBiasBaseline=True,
SkipModelExplainabilityCheck=True,
RegisterNewModelExplainabilityBaseline=True)
)
Para revisar la ejecución de la canalización, seleccione la pestaña Status (Estado). Cuando todos los pasos se ejecutan correctamente, los nodos del gráfico se vuelven verdes.

En la interfaz de SageMaker Studio, seleccione la pestaña SageMaker Resources (Recursos de SageMaker) en el panel izquierdo y elija Model registry (Registro de modelo) en la lista desplegable. El modelo registrado aparece en Model group name (Nombre del grupo de modelos) en el panel izquierdo. Seleccione el nombre del grupo de modelos para mostrar la lista de versiones de modelos. Cada vez que ejecuta la canalización, se agrega una nueva versión del modelo al registro si la versión del modelo alcanza el umbral condicional para la evaluación. Elija una versión del modelo para ver los detalles, como el punto de conexión y el informe de explicabilidad del modelo.

Paso 5: probar la canalización mediante la invocación del punto de conexión
En este tutorial, el modelo logra una valor superior al umbral del AUC elegido de 0,7. Por lo tanto, el paso condicional registra e implementa el modelo en un punto de conexión de inferencia en tiempo real.
En la interfaz de SageMaker Studio, seleccione la pestaña SageMaker Resources (Recursos de SageMaker) en el panel izquierdo, elija Endpoints (Puntos de conexión) y espere hasta que el estado de fraud-detect-xgb-pipeline-endpoint cambie a InService.

Después de que el Endpoint status (Estado del punto de conexión) cambie a InService, copie, pegue y ejecute el siguiente código para invocar el punto de conexión y ejecutar inferencias de muestra. El código devuelve las predicciones del modelo de las primeras cinco muestras en el conjunto de datos de prueba.
# Fetch test data to run predictions with the endpoint
test_df = pd.read_csv(f"{processing_output_uri}/test_data/test.csv")
# Create SageMaker Predictor from the deployed endpoint
predictor = sagemaker.predictor.Predictor(endpoint_name,
sagemaker_session=sess,
serializer=CSVSerializer(),
deserializer=CSVDeserializer()
)
# Test endpoint with payload of 5 samples
payload = test_df.drop(["fraud"], axis=1).iloc[:5]
result = predictor.predict(payload.values)
prediction_df = pd.DataFrame()
prediction_df["Prediction"] = result
prediction_df["Label"] = test_df["fraud"].iloc[:5].values
prediction_dfPaso 6: eliminar los recursos
Una práctica recomendada es eliminar los recursos que ya no se utilizan para no incurrir en cargos no deseados.
Copie y pegue el siguiente bloque de código para eliminar la función Lambda, el modelo, la configuración del punto de conexión, el punto de conexión y la canalización que creó en este tutorial.
# Delete the Lambda function
func.delete()
# Delete the endpoint
sm_client.delete_endpoint(EndpointName=endpoint_name)
# Delete the EndpointConfig
sm_client.delete_endpoint_config(EndpointConfigName=endpoint_config_name)
# Delete the model
sm_client.delete_model(ModelName=pipeline_model_name)
# Delete the pipeline
sm_client.delete_pipeline(PipelineName=pipeline_name)Para eliminar el bucket de S3, haga lo siguiente:
- Abra la consola de Amazon S3. En la barra de navegación, elija Buckets, sagemaker-<your-Region>-<your-account-id> y, a continuación, marque la casilla de verificación junto a fraud-detect-demo. Luego, seleccione Delete (Eliminar).
- En el cuadro de diálogo Delete objects (Eliminar objetos), verifique que haya seleccionado el objeto apropiado para eliminar e ingrese permanently delete (eliminar de forma permanente) en la casilla de confirmación Permanently delete objects (Eliminar objetos de forma permanente).
- Una vez que haya finalizado esto y el bucket esté vacío, puede eliminar el bucket sagemaker-<your-Region>-<your-account-id> siguiendo el mismo procedimiento nuevamente.

El kernel de ciencia de datos utilizado para ejecutar la imagen del cuaderno en este tutorial acumulará cargos hasta que lo detenga o realice los siguientes pasos para eliminar las aplicaciones. Para obtener más información, consulte Apagar recursos en la Guía para desarrolladores de Amazon SageMaker.
Para eliminar las aplicaciones de SageMaker Studio, haga lo siguiente: en la consola de SageMaker Studio, elija studio-user y, a continuación, elimine todas las aplicaciones que aparecen en Apps (Aplicaciones) al seleccionar Delete app (Eliminar aplicación). Espere hasta que el Status (Estado) cambie a Deleted (Eliminado).

Si usó un dominio existente de SageMaker Studio en el paso 1, omita el resto del paso 6 y vaya directamente a la sección de conclusión.
Si ejecutó la plantilla de CloudFormation en el paso 1 para crear un dominio de SageMaker Studio nuevo, continúe con los siguientes pasos a fin de eliminar el dominio, el usuario y los recursos creados por la plantilla de CloudFormation.
Para abrir la consola de CloudFormation, ingrese CloudFormation en la barra de búsqueda de la consola de AWS y elija CloudFormation en los resultados de búsqueda.

En el panel de CloudFormation, elija Stacks (Pilas). En la lista desplegable de estado, seleccione Active (Activo). En Stack name (Nombre de la pila), elija CFN-SM-IM-Lambda-catalog para abrir la página de detalles de la pila.

En la página de detalles de la pila CFN-SM-IM-Lambda-catalog, elija Delete (Eliminar) para eliminar la pila junto con los recursos que creó en el paso 1.

Conclusión
¡Felicitaciones! Ha terminado el tutorial Automatización de flujos de trabajo de machine learning.
Ha utilizado correctamente las Canalizaciones de Amazon SageMaker para automatizar el flujo de trabajo de machine learning de un extremo a otro a partir del procesamiento de datos, el entrenamiento de modelos, la evaluación de modelos, la comprobación de sesgos y explicabilidad, el registro de modelos condicionales y la implementación. Por último, ha utilizado el SDK de SageMaker para implementar el modelo en un punto de conexión de inferencia en tiempo real y lo ha probado con una carga de muestra.
Puede continuar su viaje de machine learning con Amazon SageMaker en la siguiente sección de pasos.
Implementar un modelo de machine learning
Entrenar un modelo de aprendizaje profundo
Encontrar más tutoriales prácticos