AWS Open Source Blog
Demystifying Elasticsearch shard allocation
At the core of OpenSearch’s ability to provide a seamless scaling experience, lies its ability distribute its workload across machines. This is achieved via sharding. When you create an index you set a primary and replica shard count for that index. Elasticsearch distributes your data and requests across those shards, and the shards across your data nodes.
The capacity and performance of your cluster depend critically on how Elasticsearch allocates shards on nodes. If all of your traffic goes to one or two nodes because they contain the active indexes in your cluster, those nodes will show high CPU, RAM, disk, and network use. You might have tens or hundreds of nodes in your cluster sitting idle while these few nodes melt down.
In this post, I will dig into Elasticsearch’s shard allocation strategy and discuss the reasons for “hot” nodes in your cluster. With this understanding, you can fix the root cause to achieve better performance and a more stable cluster.
Shard skew can result in cluster failure
In an optimal shard distribution, each machine has uniform resource utilization: every shard has the same storage footprint, every request is serviced by every shard, and every request uses CPU, RAM, disk, and network resources equally. As you scale vertically or horizontally, additional nodes contribute equally to performing the work of the cluster, increasing its capacity.
So much for the optimal case. In practice, you run more than one index in a cluster, the distribution of data is uneven, and requests are processed at different rates on different nodes. In a prior post Jon Handler explained how storage usage can become skewed. When shard distribution is skewed, CPU, network, and disk bandwidth usage can also become skewed.
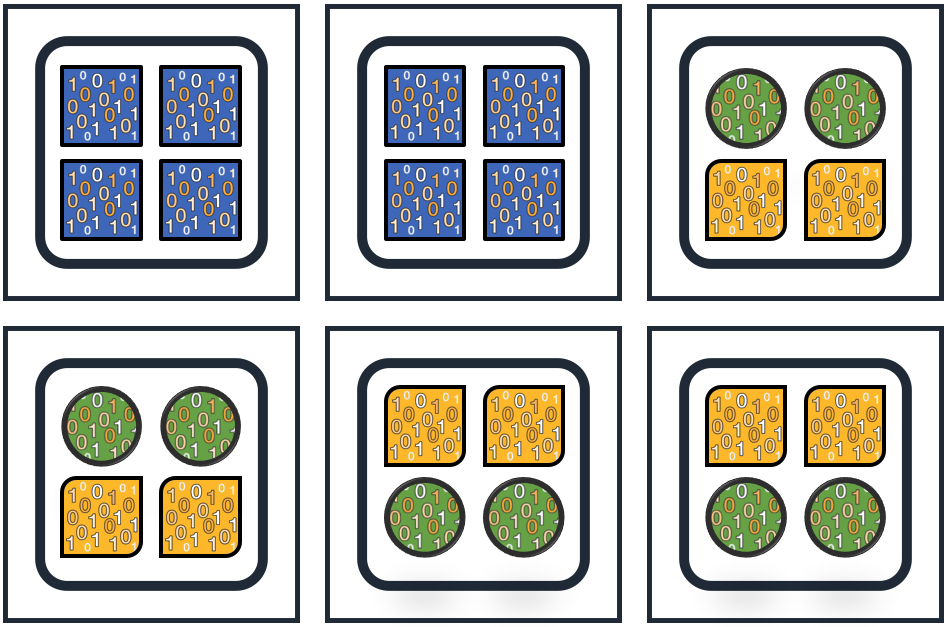
For example, let’s say you have a cluster with three indexes, each with four primary shards, deployed on six nodes as in the figure below. The shards for the square index have all landed on two nodes, while the circle and rounded-rectangle indexes are mixed on four nodes. If the square index is receiving ten times the traffic of the other two indices, those nodes will need ten times the CPU, disk, network, and RAM (likely) as the other four nodes. You either need to overscale based on the requirements for the square index, or see your cluster fall over if you have scaled for the other indexes.
The correct allocation strategy should make intelligent decisions that respect system requirements. This is a difficult problem, and Elasticsearch does a good job of solving it. Let’s dive into Elasticsearch’s algorithm.
ShardsAllocator figures out where to place shards
The ShardsAllocator is an interface in Elasticsearch whose implementations are responsible for shard placement. When shards are unassigned for any reason, ShardsAllocator decides on which nodes in the cluster to place them.
ShardsAllocator engages to determine shard locations in the following conditions:
- Index Creation – when you add an index to your cluster (or restore an index from snapshot),
ShardsAllocatordecides where to place its shards. When you increase replica count for an index, it decides locations for the new replica copies. - Node failure – if a node drops out of the cluster,
ShardsAllocatorfigures out where to place the shards that were on that node. - Cluster resize – if nodes are added or removed from the cluster,
ShardsAllocatordecides how to rebalance the cluster. - Disk high water mark – when disk usage on a node hits the high water mark (90% full, by default), Elasticsearch engages
ShardsAllocatorto move shards off that node. - Manual shard routing – when you manually route shards,
ShardsAllocatoralso moves other shards to ensure that the cluster stays balanced. - Routing related setting updates — when you change cluster or index settings that affect shard routing, such as allocation awareness, exclude or include a node (by ip or node attribute), or filter indexes to include/exclude specific nodes.
Shard placement strategy can be broken into two smaller subproblems: which shard to act on, and which target node to place it at. The default Elasticsearch implementation, BalancedShardsAllocator, divides its responsibilities into three major code paths: allocate unassigned shards, move shards, and rebalance shards. Each of these internally solves the primitive subproblems and decides an action for the shard: whether to allocate it on a specific node, move it from one node to another, or simply leave it as-is.
The overall placement operation, called reroute in Elasticsearch, is invoked when there are cluster state changes that can affect shard placement.
Node selection
Elasticsearch gets the list of eligible nodes by processing a series of Allocation Deciders. Node eligibility can vary depending on the shard and on the current allocation on the node. Not all nodes may be eligible to accept a particular shard. For example, Elasticsearch won’t put a replica shard on the same node as the primary. Or, if a node’s disk is full, Elasticsearch cannot place another shard on it.
Elasticsearch follows a greedy approach for shard placement: it makes locally optimal decisions, hoping to reach global optimum. A node’s eligibility for a hosting a shard is abstracted out to a weight function, then each shard is allocated to the node that is currently most eligible to accept it. Think of this weight function as a mathematical function which, given some parameters, returns the weight of a shard on a node. The most eligible node for a shard is one with minimum weight.
AllocateUnassigned
The first operation that a reroute invocation undertakes is allocateUnassigned. Each time an index is created, its shards (both the primary and replicas) are unassigned. When a node leaves the cluster, shards that were on that node are lost. For lost primary shards, their surviving replicas (if any) are promoted to primary (this is done by a different module), and the corresponding replicas are rendered unassigned. All of these are allocated to nodes in this operation.
For allocateUnassigned(), the BalancedShardsAllocator iterates through all unassigned shards, finds the subset of nodes eligible to accept the shard (Allocation Deciders), and out of these, picks the node with minimum weight.
There is a set order in which Elasticsearch picks unassigned shards for allocation. It picks primary shards first, allocating all shards for one index before moving on to the next index’s primaries. To choose indexes, it uses a comparator based on index priority, creation data and index name (see PriorityComparator). This ensures that Elasticsearch assigns all primaries for as many indices as possible, rather than creating several partially-assigned indices. Once Elasticsearch has assigned all primaries, it moves to the first replica for each index. Then, it moves to the second replica for each index, and so on.
Move Shards
Consider a scenario when you are scaling down your cluster. Responding to seasonal variation in your workload, you have just passed a high-traffic season and are now back to moderate workloads. You want to right-size your cluster by removing some nodes. If you remove nodes that hold data too quickly, you might remove nodes that hold a primary and its replicas, permanently losing that data. A better approach is to exclude a subset of nodes, wait for all shards to move out, and then terminate them.
Or, consider a situation where a node has its disk full and some shards must be moved out to free up space. In such cases, a shard must be moved out of a node. This is handled by the moveShards() operation, triggered right after allocateUnassigned() completes.
For “move shards”, Elasticsearch iterates through each shard in the cluster, and checks whether it can remain on its current node. If not, it selects the node with minimum weight, from the subset of eligible nodes (filtered by deciders), as the target node for this shard. A shard relocation is then triggered from current node to target node.
The move operation only applies to STARTED shards; shards in any other state are skipped. To move shards uniformly from all nodes, moveShards uses a nodeInterleavedShardIterator. This iterator goes breadth first across nodes, picking one shard from each node, followed by the next shard, and so on. Thus all shards on all nodes are evaluated for move, without preferring one over the other.
Rebalance shards
As you hit workload limits, you may decide to add more nodes to scale your cluster. Elasticsearch should automatically detect these nodes and relocate shards for better distribution. The addition or removal of nodes may not always require shard movement – what if the nodes had very few shards (say just one), and extra nodes were added only as a proactive scaling measure?
Elasticsearch generalizes this decision using the weight function abstraction in shard allocator. Given current allocations on a node, the weight function provides the weight of a shard on a node. Nodes with a high weight value are less suited to place the shard than nodes with a lower weight value. Comparing the weight of a shard on different nodes, Elasticsearch decides whether relocating can improve the overall weight distribution.
For rebalance decisions, Elasticsearch computes the weight for each index on every node, and the delta between min and max possible weights for an index. (This can be done at index level, since each shard in an index is treated equally in Elasticsearch.) Indexes are then processed in the order of most unbalanced index first.
Shard movement is a heavy operation. Before actual relocation, Elasticsearch models shard weights pre- and post-rebalance; shards are relocated only if the operation leads to a more balanced distribution of weights.
Finally, rebalancing is an optimization problem. Beyond a threshold, the cost of moving shards begins to outweigh the benefits of balanced weights. In Elasticsearch, this threshold is currently a fixed value, configurable by the dynamic setting cluster.routing.allocation.balance.threshold. When the computed weight delta for an index — the difference between its min and max weights across nodes — is less than this threshold, the index is considered balanced.
Conclusion
In this post, we covered the algorithms that power shard placement and balancing decisions in Elasticsearch. Each reroute invocation goes through the process of allocating unassigned shards, moving shards that must be evacuated from their current nodes, and rebalancing shards wherever possible. Together, they maintain a stable balanced cluster.
In the next post, we will dive deep into the default weight function implementation, which is responsible for selecting one node over another for a given shard’s placement.