Créer, entraîner et déployer un modèle de machine learning avec Amazon SageMaker
DIDACTICIEL
Introduction
Dans ce tutoriel, vous découvrirez comment utiliser Amazon SageMaker pour créer, entraîner et déployer un modèle de machine learning (ML) à l'aide de l'algorithme de ML XGBoost (langue française non garantie). Amazon SageMaker est un service entièrement géré permettant aux développeurs et aux scientifiques des données de créer, d'entraîner et de déployer rapidement des modèles de ML.
En règle générale, le processus qui va de la conceptualisation à la production des modèles de ML est complexe et chronophage. L'entraînement du modèle nécessite la gestion de grandes quantités de données, le choix du meilleur algorithme, la gestion de la capacité de calcul pendant l'entraînement, puis le déploiement du modèle dans un environnement de production. Amazon SageMaker allège cette complexité en facilitant la création et le déploiement de modèles de ML. Une fois que vous avez choisi les bons algorithmes et cadres parmi le large éventail de choix disponibles, SageMaker gère toute l'infrastructure sous-jacente pour entraîner votre modèle à l'échelle du pétaoctet et le déployer en production.
Dans ce tutoriel, vous jouerez le rôle d'un développeur de solutions à technologie machine learning au sein d'une banque. Mission vous a été confiée de développer un modèle de machine learning pour prédire si un client va s'inscrire pour un certificat de dépôt (CD).
Dans ce didacticiel, vous allez apprendre à :
- Créer une instance de bloc-notes SageMaker
- Préparer les données
- Entraîner le modèle à apprendre à partir des données
- Déployer le modèle
- Évaluer la performance de votre modèle de ML
Le modèle sera entraîné à partir d'un ensemble de données Bank Marketing qui contient des informations sur les caractéristiques sociodémographiques des clients, les réactions aux événements marketing et les facteurs externes. Les données ont été étiquetées pour plus de commodité et une colonne dans l'ensemble de données indique si le client est inscrit pour un produit offert par la banque. Une version de ce jeu de données est accessible au public sur le référentiel de ML de l'Université de Californie à Irvine.
Les ressources créées et utilisées dans ce tutoriel sont éligibles à l'offre gratuite d'AWS. Le coût de cet atelier est inférieur à 1 USD.
Expérience AWS
Débutant
Temps nécessaire
10 minutes
Coût de réalisation
Inférieur à 1 USD. Admissible à l'offre gratuite.
Éléments requis
- Compte AWS
- Dernière version de Chrome ou de Firefox (recommandé)
[**] Les comptes créés dans les dernières 24 heures sont susceptibles de ne pas encore avoir accès aux services nécessaires pour ce didacticiel.
Services utilisés
Date de la dernière mise à jour
23 août 2022
Avant de commencer
Vous devez disposer d'un compte AWS pour suivre ce didacticiel. Si vous n'avez pas encore de compte, cliquez sur S'inscrire sur AWS et créez un nouveau compte.
Vous possédez déjà un compte ?
Connectez-vous à votre compte
Étape 1 : créer une instance de bloc-notes Amazon SageMaker
Au cours de cette étape, vous allez créer l'instance de bloc-notes que vous utilisez pour télécharger et traiter vos données. Dans le cadre du processus de création, vous créez également un rôle de gestion des identités et des accès (IAM) qui permet à Amazon SageMaker d'accéder aux données d'Amazon Simple Storage Service (Amazon S3).
a. Connectez-vous à la console Amazon SageMaker, et, dans le coin supérieur droit, sélectionnez la Région AWS de votre choix. Ce didacticiel utilise la Région USA Ouest (Oregon).

b. Dans le volet de navigation de gauche, choisissez Instances de bloc-notes, puis choisissez Créer une instance de bloc-notes.

c. Sur la page Créer une instance de bloc-notes, dans la zone des Paramètres d'instances de blocs-notes, renseignez les champs suivants :
- Pour le Nom de l'instance de bloc-notes, saisissez SageMaker-Tutorial.
- Pour Type d'instance de bloc-notes, choisissez ml.t2.medium.
- Pour Prédiction élastique, conservez la sélection par défaut de Aucun.
- Pour Identifiant de plateforme, conservez la sélection par défaut.

d. Dans la section Autorisations et chiffrement, pour Rôle IAM, choisissez Créer un nouveau rôle, puis dans la boîte de dialogue Créer un rôle IAM, sélectionnez N'importe quel compartiment S3 et choisissez Créer un rôle.
Remarque : si vous avez déjà un compartiment que vous souhaitez utiliser à la place, sélectionnez Compartiments S3 spécifiques et indiquez le nom du compartiment.

Amazon SageMaker crée le rôle AmazonSageMaker-ExecutionRole-***.

e. Conservez les paramètres par défaut pour les autres options et choisissez Créer une instance de bloc-notes.
Dans la section Instances de bloc-notes, la nouvelle instance de bloc-notes SageMaker-Tutorial s'affiche avec pour Statut En attente. Le bloc-notes est prêt lorsque le Statut passe à En service.

Étape 2 : préparer les données
Au cours de cette étape, vous utilisez votre instance de bloc-notes Amazon SageMaker pour prétraiter les données dont vous avez besoin pour entraîner votre modèle de machine learning, puis vous les téléchargez sur Amazon S3.
a. Une fois que le statut de votre instance de bloc-notes SageMaker-Tutorial est passé à En service, choisissez Ouvrir Jupyter.

b. Dans Jupyter, choisissez Nouveau, puis conda_python3.

c. Dans votre bloc-notes Jupyter, copiez et collez le code suivant dans une nouvelle cellule de code et choisissez Exécuter.
Ce code importe les bibliothèques requises et définit les variables d'environnement dont vous avez besoin pour préparer les données, ainsi que pour entraîner et déployer le modèle de ML.
# import libraries
import boto3, re, sys, math, json, os, sagemaker, urllib.request
from sagemaker import get_execution_role
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from IPython.display import Image
from IPython.display import display
from time import gmtime, strftime
from sagemaker.predictor import csv_serializer
# Define IAM role
role = get_execution_role()
prefix = 'sagemaker/DEMO-xgboost-dm'
my_region = boto3.session.Session().region_name # set the region of the instance
# this line automatically looks for the XGBoost image URI and builds an XGBoost container.
xgboost_container = sagemaker.image_uris.retrieve("xgboost", my_region, "latest")
print("Success - the MySageMakerInstance is in the " + my_region + " region. You will use the " + xgboost_container + " container for your SageMaker endpoint.")
d. Créez un compartiment S3 pour stocker vos données. Copiez et collez le code suivant dans une nouvelle cellule de code et sélectionnez Exécuter.
Remarque : veillez à remplacer le bucket_name your-s3-bucket-name par un nom de compartiment S3 unique. Si vous ne recevez pas de message de réussite après avoir exécuté le code, modifiez le nom du compartiment et réessayez.
bucket_name = 'your-s3-bucket-name' # <--- CHANGE THIS VARIABLE TO A UNIQUE NAME FOR YOUR BUCKET
s3 = boto3.resource('s3')
try:
if my_region == 'us-east-1':
s3.create_bucket(Bucket=bucket_name)
else:
s3.create_bucket(Bucket=bucket_name, CreateBucketConfiguration={ 'LocationConstraint': my_region })
print('S3 bucket created successfully')
except Exception as e:
print('S3 error: ',e)
e. Téléchargez les données sur votre instance SageMaker et chargez-les dans une trame de données. Copiez et collez le code suivant dans une nouvelle cellule de code et sélectionnez Exécuter.
try:
urllib.request.urlretrieve ("https://d1.awsstatic.com/tmt/build-train-deploy-machine-learning-model-sagemaker/bank_clean.27f01fbbdf43271788427f3682996ae29ceca05d.csv", "bank_clean.csv")
print('Success: downloaded bank_clean.csv.')
except Exception as e:
print('Data load error: ',e)
try:
model_data = pd.read_csv('./bank_clean.csv',index_col=0)
print('Success: Data loaded into dataframe.')
except Exception as e:
print('Data load error: ',e)
f. Mélangez et divisez les données en données d'entraînement et en données de test. Copiez et collez le code suivant dans une nouvelle cellule de code et sélectionnez Exécuter.
Les données d'entraînement (70 % des clients) sont utilisées pendant la boucle d'entraînement du modèle. Utilisez l'optimisation par gradient pour affiner itérativement les paramètres du modèle. L'optimisation par gradient est un moyen de trouver les valeurs des paramètres du modèle qui minimalisent l'erreur du modèle, en particulier en utilisant le gradient de la fonction de perte du modèle.
Les données de test (30 % des clients restants) sont utilisées pour transférer les performances du modèle ainsi que pour évaluer la mesure dans laquelle le modèle entraîné se généralise à des données invisibles.
train_data, test_data = np.split(model_data.sample(frac=1, random_state=1729), [int(0.7 * len(model_data))])
print(train_data.shape, test_data.shape)
Étape 3 : entraîner le modèle de ML
Au cours de cette étape, vous utilisez votre ensemble de données d'entraînement pour entraîner votre modèle de machine learning.
a. Dans votre bloc-notes Jupyter, copiez et collez le code suivant dans une nouvelle cellule de code et choisissez Exécuter.
Ce code reformate l'en-tête et la première colonne des données d'entraînement, puis charge les données depuis le compartiment S3. Cette étape est requise pour utiliser l'algorithme XGBoost prédéfini d'Amazon SageMaker.
pd.concat([train_data['y_yes'], train_data.drop(['y_no', 'y_yes'], axis=1)], axis=1).to_csv('train.csv', index=False, header=False)
boto3.Session().resource('s3').Bucket(bucket_name).Object(os.path.join(prefix, 'train/train.csv')).upload_file('train.csv')
s3_input_train = sagemaker.inputs.TrainingInput(s3_data='s3://{}/{}/train'.format(bucket_name, prefix), content_type='csv')
b. Configurez la séance Amazon SageMaker, créer une instance du modèle XGBoost (un estimateur), et définir les hyperparamètres du modèle. Copiez et collez le code suivant dans une nouvelle cellule de code et sélectionnez Exécuter.
sess = sagemaker.Session()
xgb = sagemaker.estimator.Estimator(xgboost_container,role, instance_count=1, instance_type='ml.m4.xlarge',output_path='s3://{}/{}/output'.format(bucket_name, prefix),sagemaker_session=sess)
xgb.set_hyperparameters(max_depth=5,eta=0.2,gamma=4,min_child_weight=6,subsample=0.8,silent=0,objective='binary:logistic',num_round=100)
c. Commencez le processus d'entraînement. Copiez et collez le code suivant dans une nouvelle cellule de code et sélectionnez Exécuter.
Ce code entraîne le modèle à l'aide de l'optimisation du gradient sur une instance ml.m4.xlarge. Au bout de quelques minutes, vous devriez voir les journaux d'entraînement générés dans votre bloc-notes Jupyter.
xgb.fit({'train': s3_input_train})
Étape 4 : déployer le modèle
Dans cette étape, vous déployez le modèle entraîné sur un point de terminaison, le reformatez, chargez les données CSV, puis l'exécutez pour créer des prédictions.
a. Dans votre bloc-notes Jupyter, copiez et collez le code suivant dans une nouvelle cellule de code et choisissez Exécuter.
Ce code déploie le modèle sur un serveur et crée un point de terminaison SageMaker auquel vous pouvez accéder. Cette étape peut prendre quelques minutes.
xgb_predictor = xgb.deploy(initial_instance_count=1,instance_type='ml.m4.xlarge')
b. Pour prévoir si les clients dans les données de test se sont inscrits pour le produit bancaire ou non, copiez le code suivant dans la prochaine cellule de code et choisissez Exécuter :
from sagemaker.serializers import CSVSerializer
test_data_array = test_data.drop(['y_no', 'y_yes'], axis=1).values #load the data into an array
xgb_predictor.serializer = CSVSerializer() # set the serializer type
predictions = xgb_predictor.predict(test_data_array).decode('utf-8') # predict!
predictions_array = np.fromstring(predictions[1:], sep=',') # and turn the prediction into an array
print(predictions_array.shape)
Étape 5 : évaluer la performance du modèle
Dans cette étape, vous évaluez la performance et la précision du modèle de machine learning.
Dans votre bloc-notes Jupyter, copiez et collez le code suivant dans une nouvelle cellule de code et choisissez Exécuter.
Ce code compare les valeurs réelles et prédites dans un tableau appelé matrice de confusion.
Sur la base de cette prédiction, nous pouvons conclure que vous avez prédit qu'un client s'inscrira pour un certificat de dépôt avec une précision de 90 % dans les données de test, avec une précision de 65 % (278/429) pour les inscrits et 90 % (10 785/11 928) pour les non inscrits.
cm = pd.crosstab(index=test_data['y_yes'], columns=np.round(predictions_array), rownames=['Observed'], colnames=['Predicted'])
tn = cm.iloc[0,0]; fn = cm.iloc[1,0]; tp = cm.iloc[1,1]; fp = cm.iloc[0,1]; p = (tp+tn)/(tp+tn+fp+fn)*100
print("\n{0:<20}{1:<4.1f}%\n".format("Overall Classification Rate: ", p))
print("{0:<15}{1:<15}{2:>8}".format("Predicted", "No Purchase", "Purchase"))
print("Observed")
print("{0:<15}{1:<2.0f}% ({2:<}){3:>6.0f}% ({4:<})".format("No Purchase", tn/(tn+fn)*100,tn, fp/(tp+fp)*100, fp))
print("{0:<16}{1:<1.0f}% ({2:<}){3:>7.0f}% ({4:<}) \n".format("Purchase", fn/(tn+fn)*100,fn, tp/(tp+fp)*100, tp))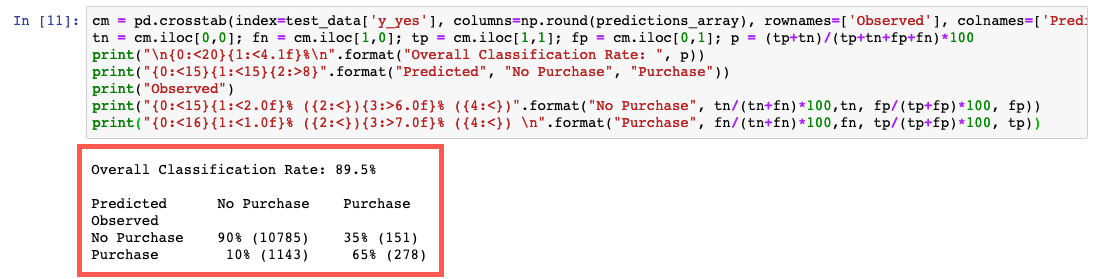
Étape 6 : nettoyage
À ce stade, vous résiliez les ressources utilisées dans cet atelier.
Important : il est conseillé de résilier les ressources qui ne sont pas utilisées de façon active, afin de réduire les coûts. Des ressources non résiliées peuvent entraîner des frais sur votre compte.
a. Suppression de votre point de terminaison : dans votre bloc-notes Jupyter, copiez et collez le code suivant et choisissez Exécuter.
xgb_predictor.delete_endpoint(delete_endpoint_config=True)b. Supprimez vos artefacts d'entraînement et votre compartiment S3 : dans votre bloc-notes Jupyter, copiez et collez le code suivant et choisissez Exécuter.
bucket_to_delete = boto3.resource('s3').Bucket(bucket_name)
bucket_to_delete.objects.all().delete()c. Supprimer votre bloc-notes SageMaker : arrêtez et supprimez votre bloc-notes SageMaker.
- Ouvrez la console SageMaker.
- Sous Blocs-notes, choisissez Instances de bloc-notes.
- Choisissez l'instance de bloc-notes que vous avez créée pour ce didacticiel, puis choisissez Actions, Arrêter. L'arrêt de l'instance de bloc-notes peut prendre plusieurs minutes. Lorsque le Statut passe à Arrêté, passez à l'étape suivante.
- Choisissez Actions, puis Supprimer.
- Choisissez Supprimer.
Conclusion
Vous savez désormais comment utiliser Amazon SageMaker pour préparer, entraîner, déployer et évaluer un modèle de machine learning. Amazon SageMaker facilite la création de modèles de ML en fournissant tout ce dont vous avez besoin pour vous connecter rapidement à vos données d'entraînement et sélectionner le meilleur algorithme et le meilleur cadre pour votre application, le tout en gérant toute l'infrastructure sous-jacente, afin que vous puissiez entraîner des modèles à l'échelle du pétaoctet.
Étapes suivantes
Maintenant que vous avez préparé, formé, déployé et évalué un modèle de machine learning, vous pouvez tirer parti de ce que vous avez appris en explorant d'autres ressources Amazon SageMaker.