Présentation
Dans ce didacticiel, découvrez comment créer et automatiser des flux de travail de machine learning (ML) de bout en bout à l'aide d'Amazon SageMaker Pipelines, Amazon SageMaker Model Registry et Amazon SageMaker Clarify.
SageMaker Pipelines est le premier service d'intégration et de livraison continues (CI/CD) spécialement créé pour le ML. Avec SageMaker Pipelines, vous pouvez automatiser différentes étapes du flux de travail de ML, notamment le chargement des données, leur transformation, l'entraînement, l'ajustement, l'évaluation et le déploiement. SageMaker Model Registry vous permet de suivre les versions des modèles, leurs métadonnées telles que le regroupement des cas d'utilisation et les références des métriques de performance des modèles dans un référentiel central où il est facile de choisir le bon modèle à déployer en fonction de vos exigences professionnelles. SageMaker Clarify offre une meilleure visibilité sur vos données et modèles d'entraînement afin que vous puissiez identifier et limiter les biais et expliquer les prédictions.
Dans ce didacticiel, vous implémentez un pipeline SageMaker pour créer, entraîner et déployer un modèle de classification binaire XGBoost qui prédit la probabilité qu'un sinistre d'assurance automobile soit frauduleux. Vous utilisez un jeu de données de synthèse de sinistres d'assurance automobile. Les entrées brutes sont deux tableaux de données d'assurance : un tableau des sinistres et un tableau des clients. Le tableau des sinistres comporte une colonne nommée fraud (fraude) qui indique si un sinistre est frauduleux ou non. Votre pipeline traite les données brutes, crée des jeux de données d'entraînement, de validation et de test, puis entraîne et évalue un modèle de classification binaire. Il utilise ensuite SageMaker Clarify pour tester le biais et l'explicabilité du modèle, et enfin, déploie le modèle pour l'inférence.
Qu'allez-vous accomplir ?
Avec ce guide, vous allez :
- Créer et exécuter un pipeline SageMaker pour automatiser le cycle de vie du ML de bout en bout
- Générer des prédictions en utilisant le modèle déployé
Prérequis
Pour pouvoir démarrer ce guide, vous avez besoin de ce qui suit :
- Un compte AWS : si vous n'en avez pas encore, suivez les instructions du guide de mise en route Configuration de votre environnement AWS pour une présentation rapide.
Expérience AWS
Durée
120 minutes
Coût de réalisation
Consultez la tarification de SageMaker pour estimer le coût de ce didacticiel.
Éléments requis
Vous devez être connecté à un compte AWS.
Services utilisés
Amazon SageMaker Studio, Amazon SageMaker Pipelines, Amazon SageMaker Clarify, Amazon SageMaker Model Registry
Date de la dernière mise à jour
24 juin 2022
Implémentation
Étape 1 : configuration de votre domaine Amazon SageMaker Studio
Un compte AWS ne peut avoir qu'un seul domaine SageMaker Studio par région. Si vous possédez déjà un domaine SageMaker Studio dans la région USA Est (Virginie du Nord), suivez le Guide de configuration de SageMaker Studio pour joindre les politiques AWS IAM requises à votre compte SageMaker Studio, puis sautez l'étape 1 et passez directement à l'étape 2.
Si vous ne disposez pas d'un domaine SageMaker Studio existant, poursuivez avec l'étape 1 pour exécuter un modèle AWS CloudFormation qui crée un domaine SageMaker Studio et ajoute les autorisations requises pour la suite de ce didacticiel.
Choisissez le lien de la pile AWS CloudFormation. Ce lien ouvre la console AWS CloudFormation et crée votre domaine SageMaker Studio ainsi qu'un utilisateur nommé studio-user. Il ajoute également les autorisations requises à votre compte SageMaker Studio. Dans la console CloudFormation, confirmez que USA Est (Virginie du Nord) est la région affichée dans le coin supérieur droit. Le nom de la pile doit être CFN-SM-IM-Lambda-Catalog, et ne doit pas être modifié. Cette pile prend environ 10 minutes pour créer toutes les ressources.
Cette pile repose sur l'hypothèse que vous avez déjà configuré un VPC public dans votre compte. Si vous ne disposez pas d'un VPC public, veuillez consulter la rubrique VPC with a single public subnet (VPC avec un seul sous-réseau public) pour savoir comment créer un VPC public.

Sélectionnez I acknowledge that AWS CloudFormation might create IAM resources (J'accepte qu'AWS CloudFormation puisse créer des ressources IAM), puis choisissez Create stack (Créer la pile).

Dans le volet CloudFormation, choisissez Stacks (Piles). Il faut environ 10 minutes pour que la pile soit créée. Lorsque la pile est créée, son statut passe de CREATE_IN_PROGRESS (Création en cours) à CREATE_COMPLETE (Création terminée).

Étape 2 : configuration d'un bloc-notes SageMaker Studio et paramétrage du pipeline
Au cours de cette étape, vous lancez un nouveau bloc-notes SageMaker Studio et configurez les variables SageMaker requises pour interagir avec Amazon Simple Storage Service (Amazon S3).
Saisissez SageMaker Studio dans la barre de recherche de la console AWS, puis choisissez SageMaker Studio. Choisissez USA Est (Virginie du Nord) dans la liste déroulante Region (Région) située dans le coin supérieur droit de la console.

Pour Launch app (Lancer l'application), sélectionnez Studio pour ouvrir SageMaker Studio à l'aide du profil studio-user.

Dans la barre de navigation SageMaker Studio, choisissez File (Fichier), New (Nouveau), Notebook (Bloc-notes).

Dans la boîte de dialogue Set up notebook environment (Configuration de l'environnement du bloc-notes), sous Image, sélectionnez Data Science (Science des données). Le noyau Python 3 est sélectionné automatiquement. Choisissez Select (Sélectionner).

Le kernel (noyau) dans le coin supérieur droit du bloc-notes devrait maintenant afficher Python 3 (Data Science) (Python 3 [Science des données]).

Pour importer les bibliothèques requises, copiez et collez le code suivant dans une cellule de votre bloc-notes et exécutez la cellule.
import pandas as pd
import json
import boto3
import pathlib
import io
import sagemaker
from sagemaker.deserializers import CSVDeserializer
from sagemaker.serializers import CSVSerializer
from sagemaker.xgboost.estimator import XGBoost
from sagemaker.sklearn.processing import SKLearnProcessor
from sagemaker.processing import (
ProcessingInput,
ProcessingOutput,
ScriptProcessor
)
from sagemaker.inputs import TrainingInput
from sagemaker.workflow.pipeline import Pipeline
from sagemaker.workflow.steps import (
ProcessingStep,
TrainingStep,
CreateModelStep
)
from sagemaker.workflow.check_job_config import CheckJobConfig
from sagemaker.workflow.parameters import (
ParameterInteger,
ParameterFloat,
ParameterString,
ParameterBoolean
)
from sagemaker.workflow.clarify_check_step import (
ModelBiasCheckConfig,
ClarifyCheckStep,
ModelExplainabilityCheckConfig
)
from sagemaker.workflow.step_collections import RegisterModel
from sagemaker.workflow.conditions import ConditionGreaterThanOrEqualTo
from sagemaker.workflow.properties import PropertyFile
from sagemaker.workflow.condition_step import ConditionStep
from sagemaker.workflow.functions import JsonGet
from sagemaker.workflow.lambda_step import (
LambdaStep,
LambdaOutput,
LambdaOutputTypeEnum,
)
from sagemaker.lambda_helper import Lambda
from sagemaker.model_metrics import (
MetricsSource,
ModelMetrics,
FileSource
)
from sagemaker.drift_check_baselines import DriftCheckBaselines
from sagemaker.image_uris import retrieveCopiez et collez le bloc de code suivant dans une cellule et exécutez-le pour configurer les objets clients S3 et SageMaker à l'aide des kits SDK SageMaker et AWS. Ces objets sont nécessaires pour permettre à SageMaker d'effectuer diverses actions telles que le déploiement et l'appel de points de terminaison, et d'interagir avec Amazon S3 et AWS Lambda. Le code configure également les emplacements du compartiment S3 où sont stockés les jeux de données bruts et traités et les artefacts du modèle. Remarquez que les compartiments de lecture et d'écriture sont séparés. Le compartiment de lecture est le compartiment S3 public nommé sagemaker-sample-files et il contient les jeux de données brutes. Le compartiment d'écriture est le compartiment S3 par défaut associé à votre compte nommé sagemaker-<votre-région>-<votre-identifiant de compte> et il est utilisé plus tard dans ce didacticiel pour stocker les jeux de données et les artefacts traités.
# Instantiate AWS services session and client objects
sess = sagemaker.Session()
write_bucket = sess.default_bucket()
write_prefix = "fraud-detect-demo"
region = sess.boto_region_name
s3_client = boto3.client("s3", region_name=region)
sm_client = boto3.client("sagemaker", region_name=region)
sm_runtime_client = boto3.client("sagemaker-runtime")
# Fetch SageMaker execution role
sagemaker_role = sagemaker.get_execution_role()
# S3 locations used for parameterizing the notebook run
read_bucket = "sagemaker-sample-files"
read_prefix = "datasets/tabular/synthetic_automobile_claims"
# S3 location where raw data to be fetched from
raw_data_key = f"s3://{read_bucket}/{read_prefix}"
# S3 location where processed data to be uploaded
processed_data_key = f"{write_prefix}/processed"
# S3 location where train data to be uploaded
train_data_key = f"{write_prefix}/train"
# S3 location where validation data to be uploaded
validation_data_key = f"{write_prefix}/validation"
# S3 location where test data to be uploaded
test_data_key = f"{write_prefix}/test"
# Full S3 paths
claims_data_uri = f"{raw_data_key}/claims.csv"
customers_data_uri = f"{raw_data_key}/customers.csv"
output_data_uri = f"s3://{write_bucket}/{write_prefix}/"
scripts_uri = f"s3://{write_bucket}/{write_prefix}/scripts"
estimator_output_uri = f"s3://{write_bucket}/{write_prefix}/training_jobs"
processing_output_uri = f"s3://{write_bucket}/{write_prefix}/processing_jobs"
model_eval_output_uri = f"s3://{write_bucket}/{write_prefix}/model_eval"
clarify_bias_config_output_uri = f"s3://{write_bucket}/{write_prefix}/model_monitor/bias_config"
clarify_explainability_config_output_uri = f"s3://{write_bucket}/{write_prefix}/model_monitor/explainability_config"
bias_report_output_uri = f"s3://{write_bucket}/{write_prefix}/clarify_output/pipeline/bias"
explainability_report_output_uri = f"s3://{write_bucket}/{write_prefix}/clarify_output/pipeline/explainability"
# Retrieve training image
training_image = retrieve(framework="xgboost", region=region, version="1.3-1")Copiez et collez le code suivant pour définir les noms des différents composants du pipeline SageMaker, tels que le modèle et le point de terminaison, et spécifier les types et le nombre d'instances d'entraînement et d'inférence. Ces valeurs sont utilisées pour paramétrer votre pipeline.
# Set names of pipeline objects
pipeline_name = "FraudDetectXGBPipeline"
pipeline_model_name = "fraud-detect-xgb-pipeline"
model_package_group_name = "fraud-detect-xgb-model-group"
base_job_name_prefix = "fraud-detect"
endpoint_config_name = f"{pipeline_model_name}-endpoint-config"
endpoint_name = f"{pipeline_model_name}-endpoint"
# Set data parameters
target_col = "fraud"
# Set instance types and counts
process_instance_type = "ml.c5.xlarge"
train_instance_count = 1
train_instance_type = "ml.m4.xlarge"
predictor_instance_count = 1
predictor_instance_type = "ml.m4.xlarge"
clarify_instance_count = 1
clarify_instance_type = "ml.m4.xlarge"SageMaker Pipelines prend en charge le paramétrage, ce qui vous permet de spécifier les paramètres d'entrée au moment de l'exécution sans modifier le code de votre pipeline. Vous pouvez utiliser les modules disponibles sous le module sagemaker.workflow.parameters, tels que ParameterInteger, ParameterFloat, ParameterString, et ParameterBoolean, pour spécifier des paramètres de pipeline de divers types de données. Copiez, collez et exécutez le code suivant pour configurer plusieurs paramètres d'entrée, y compris les configurations SageMaker Clarify.
# Set up pipeline input parameters
# Set processing instance type
process_instance_type_param = ParameterString(
name="ProcessingInstanceType",
default_value=process_instance_type,
)
# Set training instance type
train_instance_type_param = ParameterString(
name="TrainingInstanceType",
default_value=train_instance_type,
)
# Set training instance count
train_instance_count_param = ParameterInteger(
name="TrainingInstanceCount",
default_value=train_instance_count
)
# Set deployment instance type
deploy_instance_type_param = ParameterString(
name="DeployInstanceType",
default_value=predictor_instance_type,
)
# Set deployment instance count
deploy_instance_count_param = ParameterInteger(
name="DeployInstanceCount",
default_value=predictor_instance_count
)
# Set Clarify check instance type
clarify_instance_type_param = ParameterString(
name="ClarifyInstanceType",
default_value=clarify_instance_type,
)
# Set model bias check params
skip_check_model_bias_param = ParameterBoolean(
name="SkipModelBiasCheck",
default_value=False
)
register_new_baseline_model_bias_param = ParameterBoolean(
name="RegisterNewModelBiasBaseline",
default_value=False
)
supplied_baseline_constraints_model_bias_param = ParameterString(
name="ModelBiasSuppliedBaselineConstraints",
default_value=""
)
# Set model explainability check params
skip_check_model_explainability_param = ParameterBoolean(
name="SkipModelExplainabilityCheck",
default_value=False
)
register_new_baseline_model_explainability_param = ParameterBoolean(
name="RegisterNewModelExplainabilityBaseline",
default_value=False
)
supplied_baseline_constraints_model_explainability_param = ParameterString(
name="ModelExplainabilitySuppliedBaselineConstraints",
default_value=""
)
# Set model approval param
model_approval_status_param = ParameterString(
name="ModelApprovalStatus", default_value="Approved"
)Étape 3 : création des composants du pipeline
Un pipeline est une séquence d'étapes qui peuvent être créées individuellement, puis assemblées pour former un flux de travail de ML. Le diagramme suivant montre les étapes de haut niveau d'un pipeline.
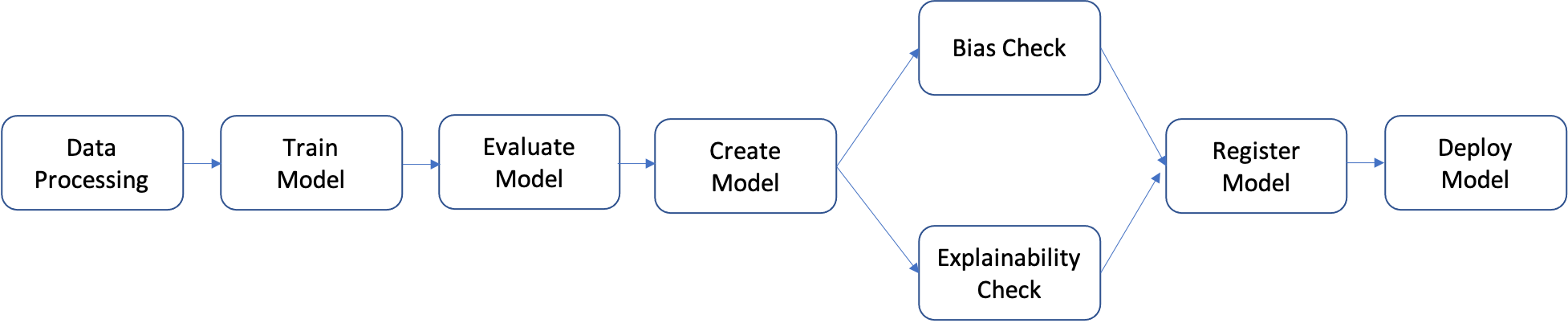
Dans ce didacticiel, vous créez un pipeline en suivant les étapes suivantes :
- Étape de traitement des données : exécute une tâche SageMaker Processing à l'aide des données brutes d'entrée dans S3 et produit des fractionnements d'entraînement, de validation et de test dans S3.
- Étape d'entraînement : entraîne un modèle XGBoost à l'aide de tâches d'entraînement SageMaker avec des données d'entraînement et de validation dans S3 comme entrées, et stocke l'artefact du modèle entraîné dans S3.
- Étape d'évaluation : évalue le modèle sur le jeu de données de test en exécutant une tâche SageMaker Processing en utilisant les données de test et l'artefact du modèle dans S3 comme entrées, et stocke le rapport d'évaluation des performances du modèle en sortie dans S3.
- Étape conditionnelle : compare les performances du modèle sur le jeu de données de test par rapport au seuil. Exécute une étape prédéfinie de SageMaker Pipelines en utilisant le rapport d'évaluation des performances du modèle dans S3 comme entrée, et enregistre la liste de sortie des étapes du pipeline qui seront exécutées si les performances du modèle sont acceptables.
- Étape de création de modèle : exécute une étape prédéfinie SageMaker Pipelines en utilisant l'artefact de modèle dans S3 comme entrée, et stocke le modèle SageMaker de sortie dans S3.
- Étape de vérification du biais : vérifie le biais du modèle en utilisant SageMaker Clarify avec les données d'entraînement et l'artefact du modèle dans S3 comme entrées et stocke le rapport sur le biais du modèle et les métriques de référence dans S3.
- Étape d'explicabilité du modèle : exécute SageMaker Clarify avec les données d'entraînement et l'artefact de modèle dans S3 comme entrées, et stocke le rapport d'explicabilité du modèle et les métriques de référence dans S3.
- Étape d'enregistrement : exécute une étape prédéfinie de SageMaker Pipelines en utilisant les métriques de référence du modèle, du biais et de l'explicabilité comme entrées pour enregistrer le modèle dans le registre de modèles de SageMaker.
- Étape de déploiement : exécute une étape prédéfinie de SageMaker Pipelines en utilisant une fonction de gestion AWS Lambda, le modèle et la configuration du point de terminaison comme entrées pour déployer le modèle vers un point de terminaison de l'inférence en temps réel SageMaker.
SageMaker Pipelines propose de nombreux types d'étapes prédéfinies, telles que des étapes pour le traitement des données, l'entraînement des modèles, le réglage des modèles et la transformation par lots. Pour en savoir plus, veuillez consulter la rubrique Pipeline Steps (Étapes du pipeline) dans le Guide du développeur Amazon SageMaker. Dans les étapes suivantes, vous configurez et définissez chaque étape du pipeline individuellement, puis vous définissez le pipeline lui-même en combinant les étapes du pipeline avec les paramètres d'entrée.
Étape de traitement des données : au cours de cette étape, vous préparez un script Python pour intégrer les fichiers bruts, vous effectuez des traitements tels que l'imputation des valeurs manquantes et l'ingénierie des fonctionnalités, et vous préparez les fractionnements d'entraînement, de validation et de test qui seront utilisés pour créer des modèles. Copiez, collez et exécutez le code suivant pour créer votre script de traitement.
%%writefile preprocessing.py
import argparse
import pathlib
import boto3
import os
import pandas as pd
import logging
from sklearn.model_selection import train_test_split
logger = logging.getLogger()
logger.setLevel(logging.INFO)
logger.addHandler(logging.StreamHandler())
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--train-ratio", type=float, default=0.8)
parser.add_argument("--validation-ratio", type=float, default=0.1)
parser.add_argument("--test-ratio", type=float, default=0.1)
args, _ = parser.parse_known_args()
logger.info("Received arguments {}".format(args))
# Set local path prefix in the processing container
local_dir = "/opt/ml/processing"
input_data_path_claims = os.path.join("/opt/ml/processing/claims", "claims.csv")
input_data_path_customers = os.path.join("/opt/ml/processing/customers", "customers.csv")
logger.info("Reading claims data from {}".format(input_data_path_claims))
df_claims = pd.read_csv(input_data_path_claims)
logger.info("Reading customers data from {}".format(input_data_path_customers))
df_customers = pd.read_csv(input_data_path_customers)
logger.debug("Formatting column names.")
# Format column names
df_claims = df_claims.rename({c : c.lower().strip().replace(' ', '_') for c in df_claims.columns}, axis = 1)
df_customers = df_customers.rename({c : c.lower().strip().replace(' ', '_') for c in df_customers.columns}, axis = 1)
logger.debug("Joining datasets.")
# Join datasets
df_data = df_claims.merge(df_customers, on = 'policy_id', how = 'left')
# Drop selected columns not required for model building
df_data = df_data.drop(['customer_zip'], axis = 1)
# Select Ordinal columns
ordinal_cols = ["police_report_available", "policy_liability", "customer_education"]
# Select categorical columns and filling with na
cat_cols_all = list(df_data.select_dtypes('object').columns)
cat_cols = [c for c in cat_cols_all if c not in ordinal_cols]
df_data[cat_cols] = df_data[cat_cols].fillna('na')
logger.debug("One-hot encoding categorical columns.")
# One-hot encoding categorical columns
df_data = pd.get_dummies(df_data, columns = cat_cols)
logger.debug("Encoding ordinal columns.")
# Ordinal encoding
mapping = {
"Yes": "1",
"No": "0"
}
df_data['police_report_available'] = df_data['police_report_available'].map(mapping)
df_data['police_report_available'] = df_data['police_report_available'].astype(float)
mapping = {
"15/30": "0",
"25/50": "1",
"30/60": "2",
"100/200": "3"
}
df_data['policy_liability'] = df_data['policy_liability'].map(mapping)
df_data['policy_liability'] = df_data['policy_liability'].astype(float)
mapping = {
"Below High School": "0",
"High School": "1",
"Associate": "2",
"Bachelor": "3",
"Advanced Degree": "4"
}
df_data['customer_education'] = df_data['customer_education'].map(mapping)
df_data['customer_education'] = df_data['customer_education'].astype(float)
df_processed = df_data.copy()
df_processed.columns = [c.lower() for c in df_data.columns]
df_processed = df_processed.drop(["policy_id", "customer_gender_unkown"], axis=1)
# Split into train, validation, and test sets
train_ratio = args.train_ratio
val_ratio = args.validation_ratio
test_ratio = args.test_ratio
logger.debug("Splitting data into train, validation, and test sets")
y = df_processed['fraud']
X = df_processed.drop(['fraud'], axis = 1)
X_train_val, X_test, y_train_val, y_test = train_test_split(X, y, test_size=test_ratio, random_state=42)
X_train, X_val, y_train, y_val = train_test_split(X_train_val, y_train_val, test_size=val_ratio, random_state=42)
train_df = pd.concat([y_train, X_train], axis = 1)
val_df = pd.concat([y_val, X_val], axis = 1)
test_df = pd.concat([y_test, X_test], axis = 1)
dataset_df = pd.concat([y, X], axis = 1)
logger.info("Train data shape after preprocessing: {}".format(train_df.shape))
logger.info("Validation data shape after preprocessing: {}".format(val_df.shape))
logger.info("Test data shape after preprocessing: {}".format(test_df.shape))
# Save processed datasets to the local paths in the processing container.
# SageMaker will upload the contents of these paths to S3 bucket
logger.debug("Writing processed datasets to container local path.")
train_output_path = os.path.join(f"{local_dir}/train", "train.csv")
validation_output_path = os.path.join(f"{local_dir}/val", "validation.csv")
test_output_path = os.path.join(f"{local_dir}/test", "test.csv")
full_processed_output_path = os.path.join(f"{local_dir}/full", "dataset.csv")
logger.info("Saving train data to {}".format(train_output_path))
train_df.to_csv(train_output_path, index=False)
logger.info("Saving validation data to {}".format(validation_output_path))
val_df.to_csv(validation_output_path, index=False)
logger.info("Saving test data to {}".format(test_output_path))
test_df.to_csv(test_output_path, index=False)
logger.info("Saving full processed data to {}".format(full_processed_output_path))
dataset_df.to_csv(full_processed_output_path, index=False)
Ensuite, copiez, collez et exécutez le bloc de code suivant pour instancier le processeur et l'action SageMaker Pipelines afin d'exécuter le script de traitement. Comme le script de traitement est écrit en Pandas, vous utilisez un SKLearnProcessor. La fonction ProcessingStep de SageMaker Pipelines prend les arguments suivants : le processeur, les emplacements S3 d'entrée pour les jeux de données bruts et les emplacements S3 de sortie pour enregistrer les jeux de données traités. Des arguments supplémentaires tels que les proportions de fractionnement d'entraînement, de validation et de test sont fournis par l'argument job_arguments.
from sagemaker.workflow.pipeline_context import PipelineSession
# Upload processing script to S3
s3_client.upload_file(
Filename="preprocessing.py", Bucket=write_bucket, Key=f"{write_prefix}/scripts/preprocessing.py"
)
# Define the SKLearnProcessor configuration
sklearn_processor = SKLearnProcessor(
framework_version="0.23-1",
role=sagemaker_role,
instance_count=1,
instance_type=process_instance_type,
base_job_name=f"{base_job_name_prefix}-processing",
)
# Define pipeline processing step
process_step = ProcessingStep(
name="DataProcessing",
processor=sklearn_processor,
inputs=[
ProcessingInput(source=claims_data_uri, destination="/opt/ml/processing/claims"),
ProcessingInput(source=customers_data_uri, destination="/opt/ml/processing/customers")
],
outputs=[
ProcessingOutput(destination=f"{processing_output_uri}/train_data", output_name="train_data", source="/opt/ml/processing/train"),
ProcessingOutput(destination=f"{processing_output_uri}/validation_data", output_name="validation_data", source="/opt/ml/processing/val"),
ProcessingOutput(destination=f"{processing_output_uri}/test_data", output_name="test_data", source="/opt/ml/processing/test"),
ProcessingOutput(destination=f"{processing_output_uri}/processed_data", output_name="processed_data", source="/opt/ml/processing/full")
],
job_arguments=[
"--train-ratio", "0.8",
"--validation-ratio", "0.1",
"--test-ratio", "0.1"
],
code=f"s3://{write_bucket}/{write_prefix}/scripts/preprocessing.py"
)Copiez, collez et exécutez le bloc de code suivant pour préparer le script d'entraînement. Ce script encapsule la logique d'entraînement du classificateur binaire XGBoost. Les hyperparamètres utilisés pour entraîner le modèle sont fournis plus loin dans le didacticiel lors de la définition de l'étape d'entraînement.
%%writefile xgboost_train.py
import argparse
import os
import joblib
import json
import pandas as pd
import xgboost as xgb
from sklearn.metrics import roc_auc_score
if __name__ == "__main__":
parser = argparse.ArgumentParser()
# Hyperparameters and algorithm parameters are described here
parser.add_argument("--num_round", type=int, default=100)
parser.add_argument("--max_depth", type=int, default=3)
parser.add_argument("--eta", type=float, default=0.2)
parser.add_argument("--subsample", type=float, default=0.9)
parser.add_argument("--colsample_bytree", type=float, default=0.8)
parser.add_argument("--objective", type=str, default="binary:logistic")
parser.add_argument("--eval_metric", type=str, default="auc")
parser.add_argument("--nfold", type=int, default=3)
parser.add_argument("--early_stopping_rounds", type=int, default=3)
# SageMaker specific arguments. Defaults are set in the environment variables
# Set location of input training data
parser.add_argument("--train_data_dir", type=str, default=os.environ.get("SM_CHANNEL_TRAIN"))
# Set location of input validation data
parser.add_argument("--validation_data_dir", type=str, default=os.environ.get("SM_CHANNEL_VALIDATION"))
# Set location where trained model will be stored. Default set by SageMaker, /opt/ml/model
parser.add_argument("--model_dir", type=str, default=os.environ.get("SM_MODEL_DIR"))
# Set location where model artifacts will be stored. Default set by SageMaker, /opt/ml/output/data
parser.add_argument("--output_data_dir", type=str, default=os.environ.get("SM_OUTPUT_DATA_DIR"))
args = parser.parse_args()
data_train = pd.read_csv(f"{args.train_data_dir}/train.csv")
train = data_train.drop("fraud", axis=1)
label_train = pd.DataFrame(data_train["fraud"])
dtrain = xgb.DMatrix(train, label=label_train)
data_validation = pd.read_csv(f"{args.validation_data_dir}/validation.csv")
validation = data_validation.drop("fraud", axis=1)
label_validation = pd.DataFrame(data_validation["fraud"])
dvalidation = xgb.DMatrix(validation, label=label_validation)
# Choose XGBoost model hyperparameters
params = {"max_depth": args.max_depth,
"eta": args.eta,
"objective": args.objective,
"subsample" : args.subsample,
"colsample_bytree":args.colsample_bytree
}
num_boost_round = args.num_round
nfold = args.nfold
early_stopping_rounds = args.early_stopping_rounds
# Cross-validate train XGBoost model
cv_results = xgb.cv(
params=params,
dtrain=dtrain,
num_boost_round=num_boost_round,
nfold=nfold,
early_stopping_rounds=early_stopping_rounds,
metrics=["auc"],
seed=42,
)
model = xgb.train(params=params, dtrain=dtrain, num_boost_round=len(cv_results))
train_pred = model.predict(dtrain)
validation_pred = model.predict(dvalidation)
train_auc = roc_auc_score(label_train, train_pred)
validation_auc = roc_auc_score(label_validation, validation_pred)
print(f"[0]#011train-auc:{train_auc:.2f}")
print(f"[0]#011validation-auc:{validation_auc:.2f}")
metrics_data = {"hyperparameters" : params,
"binary_classification_metrics": {"validation:auc": {"value": validation_auc},
"train:auc": {"value": train_auc}
}
}
# Save the evaluation metrics to the location specified by output_data_dir
metrics_location = args.output_data_dir + "/metrics.json"
# Save the trained model to the location specified by model_dir
model_location = args.model_dir + "/xgboost-model"
with open(metrics_location, "w") as f:
json.dump(metrics_data, f)
with open(model_location, "wb") as f:
joblib.dump(model, f)Configurez l'entraînement du modèle en utilisant un estimateur XGBoost de SageMaker et la fonction TrainingStep de SageMaker Pipelines.
# Set XGBoost model hyperparameters
hyperparams = {
"eval_metric" : "auc",
"objective": "binary:logistic",
"num_round": "5",
"max_depth":"5",
"subsample":"0.75",
"colsample_bytree":"0.75",
"eta":"0.5"
}
# Set XGBoost estimator
xgb_estimator = XGBoost(
entry_point="xgboost_train.py",
output_path=estimator_output_uri,
code_location=estimator_output_uri,
hyperparameters=hyperparams,
role=sagemaker_role,
# Fetch instance type and count from pipeline parameters
instance_count=train_instance_count,
instance_type=train_instance_type,
framework_version="1.3-1"
)
# Access the location where the preceding processing step saved train and validation datasets
# Pipeline step properties can give access to outputs which can be used in succeeding steps
s3_input_train = TrainingInput(
s3_data=process_step.properties.ProcessingOutputConfig.Outputs["train_data"].S3Output.S3Uri,
content_type="csv",
s3_data_type="S3Prefix"
)
s3_input_validation = TrainingInput(
s3_data=process_step.properties.ProcessingOutputConfig.Outputs["validation_data"].S3Output.S3Uri,
content_type="csv",
s3_data_type="S3Prefix"
)
# Set pipeline training step
train_step = TrainingStep(
name="XGBModelTraining",
estimator=xgb_estimator,
inputs={
"train":s3_input_train, # Train channel
"validation": s3_input_validation # Validation channel
}
)Copiez, collez et exécutez le bloc de code suivant, qui est utilisé pour créer un modèle SageMaker à l'aide de la fonction SageMaker Pipelines CreateModelStep. Cette étape utilise les résultats de l'étape d'entraînement pour préparer le modèle au déploiement. Notez que la valeur de l'argument de type d'instance est transmise à l'aide du paramètre SageMaker Pipelines que vous avez défini plus tôt dans le didacticiel.
# Create a SageMaker model
model = sagemaker.model.Model(
image_uri=training_image,
model_data=train_step.properties.ModelArtifacts.S3ModelArtifacts,
sagemaker_session=sess,
role=sagemaker_role
)
# Specify model deployment instance type
inputs = sagemaker.inputs.CreateModelInput(instance_type=deploy_instance_type_param)
create_model_step = CreateModelStep(name="FraudDetModel", model=model, inputs=inputs)Dans un flux de travail de ML, il est important d'évaluer les biais potentiels d'un modèle entraîné et de comprendre comment les différentes caractéristiques des données d'entrée affectent la prédiction du modèle. SageMaker Pipelines fournit une fonction ClarifyCheckStep qui peut être utilisée pour effectuer trois types de contrôles : contrôle du biais des données (pré-entraînement), contrôle du biais du modèle (post-entraînement) et contrôle de l'explicabilité du modèle. Pour réduire le temps d'exécution, dans ce didacticiel, vous n'implémentez que les contrôles de biais et d'explicabilité. Copiez, collez et exécutez le bloc de code suivant pour configurer SageMaker Clarify afin de vérifier le biais du modèle. Notez que cette étape récupère les ressources, telles que les données d'entraînement et le modèle SageMaker créé dans les étapes précédentes, par le biais de l'attribut properties (propriétés). Lors de l'exécution du pipeline, cette étape n'est démarrée qu'après la fin de l'exécution des étapes fournissant les entrées. Pour plus de détails, veuillez consulter la rubrique Data Dependency Between Steps (Dépendance des données entre les étapes) dans le Guide du développeur Amazon SageMaker. Pour gérer les coûts et le temps de fonctionnement du didacticiel, la fonction ModelBiasCheckConfig est configurée pour calculer une seule métrique de biais : DPPL. Pour plus d'informations sur les métriques de biais disponibles dans SageMaker Clarify, veuillez consulter la rubrique Measure Posttraining Data and Model Bias (Mesure des données de post-entraînement et des biais de modèle) dans le Guide du développeur Amazon SageMaker.
# Set up common configuration parameters to be used across multiple steps
check_job_config = CheckJobConfig(
role=sagemaker_role,
instance_count=1,
instance_type=clarify_instance_type,
volume_size_in_gb=30,
sagemaker_session=sess,
)
# Set up configuration of data to be used for model bias check
model_bias_data_config = sagemaker.clarify.DataConfig(
# Fetch S3 location where processing step saved train data
s3_data_input_path=process_step.properties.ProcessingOutputConfig.Outputs["train_data"].S3Output.S3Uri,
s3_output_path=bias_report_output_uri,
label=target_col,
dataset_type="text/csv",
s3_analysis_config_output_path=clarify_bias_config_output_uri
)
# Set up details of the trained model to be checked for bias
model_config = sagemaker.clarify.ModelConfig(
# Pull model name from model creation step
model_name=create_model_step.properties.ModelName,
instance_count=train_instance_count,
instance_type=train_instance_type
)
# Set up column and categories that are to be checked for bias
model_bias_config = sagemaker.clarify.BiasConfig(
label_values_or_threshold=[0],
facet_name="customer_gender_female",
facet_values_or_threshold=[1]
)
# Set up model predictions configuration to get binary labels from probabilities
model_predictions_config = sagemaker.clarify.ModelPredictedLabelConfig(probability_threshold=0.5)
model_bias_check_config = ModelBiasCheckConfig(
data_config=model_bias_data_config,
data_bias_config=model_bias_config,
model_config=model_config,
model_predicted_label_config=model_predictions_config,
methods=["DPPL"]
)
# Set up pipeline model bias check step
model_bias_check_step = ClarifyCheckStep(
name="ModelBiasCheck",
clarify_check_config=model_bias_check_config,
check_job_config=check_job_config,
skip_check=skip_check_model_bias_param,
register_new_baseline=register_new_baseline_model_bias_param,
supplied_baseline_constraints=supplied_baseline_constraints_model_bias_param
)Copiez, collez et exécutez le bloc de code suivant pour configurer les contrôles d'explicabilité des modèles. Cette étape fournit des informations telles que l'importance des caractéristiques (comment les caractéristiques d'entrée influencent les prédictions du modèle).
# Set configuration of data to be used for model explainability check
model_explainability_data_config = sagemaker.clarify.DataConfig(
# Fetch S3 location where processing step saved train data
s3_data_input_path=process_step.properties.ProcessingOutputConfig.Outputs["train_data"].S3Output.S3Uri,
s3_output_path=explainability_report_output_uri,
label=target_col,
dataset_type="text/csv",
s3_analysis_config_output_path=clarify_explainability_config_output_uri
)
# Set SHAP configuration for Clarify to compute global and local SHAP values for feature importance
shap_config = sagemaker.clarify.SHAPConfig(
seed=42,
num_samples=100,
agg_method="mean_abs",
save_local_shap_values=True
)
model_explainability_config = ModelExplainabilityCheckConfig(
data_config=model_explainability_data_config,
model_config=model_config,
explainability_config=shap_config
)
# Set pipeline model explainability check step
model_explainability_step = ClarifyCheckStep(
name="ModelExplainabilityCheck",
clarify_check_config=model_explainability_config,
check_job_config=check_job_config,
skip_check=skip_check_model_explainability_param,
register_new_baseline=register_new_baseline_model_explainability_param,
supplied_baseline_constraints=supplied_baseline_constraints_model_explainability_param
)Dans les systèmes de production, les modèles entraînés ne sont pas tous déployés. En général, seuls les modèles dont les performances sont supérieures au seuil fixé pour une métrique d'évaluation donnée sont déployés. Au cours de cette étape, vous créez un script Python qui évalue le modèle sur un ensemble de tests à l'aide de la métrique ROC-AUC (Receiver Operating Characteristic Area Under the Curve). La performance du modèle par rapport à cette métrique est utilisée dans une étape ultérieure pour déterminer si le modèle doit être enregistré et déployé. Copiez, collez et exécutez le code suivant pour créer un script d'évaluation qui ingère un jeu de données de test et génère la métrique AUC.
%%writefile evaluate.py
import json
import logging
import pathlib
import pickle
import tarfile
import numpy as np
import pandas as pd
import xgboost as xgb
from sklearn.metrics import roc_auc_score
logger = logging.getLogger()
logger.setLevel(logging.INFO)
logger.addHandler(logging.StreamHandler())
if __name__ == "__main__":
model_path = "/opt/ml/processing/model/model.tar.gz"
with tarfile.open(model_path) as tar:
tar.extractall(path=".")
logger.debug("Loading xgboost model.")
# The name of the file should match how the model was saved in the training script
model = pickle.load(open("xgboost-model", "rb"))
logger.debug("Reading test data.")
test_local_path = "/opt/ml/processing/test/test.csv"
df_test = pd.read_csv(test_local_path)
# Extract test set target column
y_test = df_test.iloc[:, 0].values
cols_when_train = model.feature_names
# Extract test set feature columns
X = df_test[cols_when_train].copy()
X_test = xgb.DMatrix(X)
logger.info("Generating predictions for test data.")
pred = model.predict(X_test)
# Calculate model evaluation score
logger.debug("Calculating ROC-AUC score.")
auc = roc_auc_score(y_test, pred)
metric_dict = {
"classification_metrics": {"roc_auc": {"value": auc}}
}
# Save model evaluation metrics
output_dir = "/opt/ml/processing/evaluation"
pathlib.Path(output_dir).mkdir(parents=True, exist_ok=True)
logger.info("Writing evaluation report with ROC-AUC: %f", auc)
evaluation_path = f"{output_dir}/evaluation.json"
with open(evaluation_path, "w") as f:
f.write(json.dumps(metric_dict))Ensuite, copiez, collez et exécutez le bloc de code suivant pour instancier le processeur et l'étape de SageMaker Pipelines pour exécuter le script d'évaluation. Pour traiter le script personnalisé, vous utilisez un ScriptProcessor. La fonction ProcessingStep de SageMaker Pipelines prend les arguments suivants : le processeur, l'emplacement d'entrée S3 pour le jeu de données de test, l'artefact de modèle et l'emplacement de sortie pour stocker les résultats de l'évaluation. En outre, un argument property_files est fourni. Vous utilisez les fichiers de propriétés pour stocker les informations de la sortie de l'étape de traitement, qui dans ce cas est un fichier json avec la métrique de performance du modèle. Comme on le verra plus loin dans le didacticiel, cette fonction est particulièrement utile pour déterminer quand une étape conditionnelle doit être exécutée.
# Upload model evaluation script to S3
s3_client.upload_file(
Filename="evaluate.py", Bucket=write_bucket, Key=f"{write_prefix}/scripts/evaluate.py"
)
eval_processor = ScriptProcessor(
image_uri=training_image,
command=["python3"],
instance_type=predictor_instance_type,
instance_count=predictor_instance_count,
base_job_name=f"{base_job_name_prefix}-model-eval",
sagemaker_session=sess,
role=sagemaker_role,
)
evaluation_report = PropertyFile(
name="FraudDetEvaluationReport",
output_name="evaluation",
path="evaluation.json",
)
# Set model evaluation step
evaluation_step = ProcessingStep(
name="XGBModelEvaluate",
processor=eval_processor,
inputs=[
ProcessingInput(
# Fetch S3 location where train step saved model artifacts
source=train_step.properties.ModelArtifacts.S3ModelArtifacts,
destination="/opt/ml/processing/model",
),
ProcessingInput(
# Fetch S3 location where processing step saved test data
source=process_step.properties.ProcessingOutputConfig.Outputs["test_data"].S3Output.S3Uri,
destination="/opt/ml/processing/test",
),
],
outputs=[
ProcessingOutput(destination=f"{model_eval_output_uri}", output_name="evaluation", source="/opt/ml/processing/evaluation"),
],
code=f"s3://{write_bucket}/{write_prefix}/scripts/evaluate.py",
property_files=[evaluation_report],
)Avec SageMaker Model Registry, vous pouvez cataloguer les modèles, gérer les versions des modèles et déployer sélectivement les modèles en production. Copiez, collez et exécutez le bloc de code suivant pour configurer l'étape du registre des modèles. Les deux paramètres, model_metrics et drift_check_baselines, contiennent les métriques de référence calculées précédemment dans le didacticiel par la fonction ClarifyCheckStep. Vous pouvez également fournir vos propres métriques de référence personnalisées. L'intention derrière ces paramètres est de fournir un moyen de configurer les références associées à un modèle afin qu'elles puissent être utilisées dans les vérifications de dérive et les tâches de surveillance du modèle. Chaque fois qu'un pipeline est exécuté, vous pouvez choisir de mettre à jour ces paramètres avec des références nouvellement calculées.
# Fetch baseline constraints to record in model registry
model_metrics = ModelMetrics(
bias_post_training=MetricsSource(
s3_uri=model_bias_check_step.properties.CalculatedBaselineConstraints,
content_type="application/json"
),
explainability=MetricsSource(
s3_uri=model_explainability_step.properties.CalculatedBaselineConstraints,
content_type="application/json"
),
)
# Fetch baselines to record in model registry for drift check
drift_check_baselines = DriftCheckBaselines(
bias_post_training_constraints=MetricsSource(
s3_uri=model_bias_check_step.properties.BaselineUsedForDriftCheckConstraints,
content_type="application/json",
),
explainability_constraints=MetricsSource(
s3_uri=model_explainability_step.properties.BaselineUsedForDriftCheckConstraints,
content_type="application/json",
),
explainability_config_file=FileSource(
s3_uri=model_explainability_config.monitoring_analysis_config_uri,
content_type="application/json",
),
)
# Define register model step
register_step = RegisterModel(
name="XGBRegisterModel",
estimator=xgb_estimator,
# Fetching S3 location where train step saved model artifacts
model_data=train_step.properties.ModelArtifacts.S3ModelArtifacts,
content_types=["text/csv"],
response_types=["text/csv"],
inference_instances=[predictor_instance_type],
transform_instances=[predictor_instance_type],
model_package_group_name=model_package_group_name,
approval_status=model_approval_status_param,
# Registering baselines metrics that can be used for model monitoring
model_metrics=model_metrics,
drift_check_baselines=drift_check_baselines
)Avec Amazon SageMaker, un modèle enregistré peut être déployé pour l'inférence de plusieurs manières. Au cours de cette étape, vous déployez le modèle à l'aide de la fonction LambdaStep. Bien que vous deviez généralement utiliser SageMaker Projects pour les déploiements robustes de modèles qui suivent les bonnes pratiques CI/CD, il peut y avoir des circonstances où il est judicieux d'utiliser LambdaStep pour les déploiements de modèles légers vers des points de terminaison de développement, de test et internes traitant de faibles volumes de trafic. La fonction LambdaStep offre une intégration native avec AWS Lambda, ce qui vous permet de mettre en œuvre une logique personnalisée dans votre pipeline sans avoir à provisionner ou à gérer des serveurs. Dans le contexte de SageMaker Pipelines, LambdaStep vous permet d'ajouter une fonction AWS Lambda à vos pipelines pour prendre en charge des opérations de calcul arbitraires, notamment des opérations légères de courte durée. N'oubliez pas que dans une LambdaStep de SageMaker Pipelines, une fonction Lambda est limitée à une durée d'exécution maximale de 10 minutes, avec un délai par défaut modifiable de 2 minutes.
Deux méthodes s'offrent à vous pour ajouter une LambdaStep à vos pipelines. La première vous permet de fournir l'ARN d'une fonction Lambda existante que vous avez créée avec l'AWS Cloud Development Kit (AWS CDK), la console de gestion AWS ou autre. La seconde utilise le kit SDK SageMaker Python de haut niveau, qui comporte une classe pratique d'aide Lambda que vous pouvez utiliser pour créer une nouvelle fonction Lambda avec le reste du code définissant votre pipeline. Vous utilisez la deuxième méthode dans ce didacticiel. Copiez, collez et exécutez le code suivant pour définir la fonction de gestion Lambda. Il s'agit du script Python personnalisé qui prend en compte les attributs du modèle, tels que le nom du modèle, et le déploie vers un point de terminaison en temps réel.
%%writefile lambda_deployer.py
"""
Lambda function creates an endpoint configuration and deploys a model to real-time endpoint.
Required parameters for deployment are retrieved from the event object
"""
import json
import boto3
def lambda_handler(event, context):
sm_client = boto3.client("sagemaker")
# Details of the model created in the Pipeline CreateModelStep
model_name = event["model_name"]
model_package_arn = event["model_package_arn"]
endpoint_config_name = event["endpoint_config_name"]
endpoint_name = event["endpoint_name"]
role = event["role"]
instance_type = event["instance_type"]
instance_count = event["instance_count"]
primary_container = {"ModelPackageName": model_package_arn}
# Create model
model = sm_client.create_model(
ModelName=model_name,
PrimaryContainer=primary_container,
ExecutionRoleArn=role
)
# Create endpoint configuration
create_endpoint_config_response = sm_client.create_endpoint_config(
EndpointConfigName=endpoint_config_name,
ProductionVariants=[
{
"VariantName": "Alltraffic",
"ModelName": model_name,
"InitialInstanceCount": instance_count,
"InstanceType": instance_type,
"InitialVariantWeight": 1
}
]
)
# Create endpoint
create_endpoint_response = sm_client.create_endpoint(
EndpointName=endpoint_name,
EndpointConfigName=endpoint_config_name
)Copiez, collez et exécutez le bloc de code suivant pour créer la LambdaStep. Tous les paramètres tels que le modèle, le nom du point de terminaison, le type et le nombre d'instances de déploiement sont fournis à l'aide de l'argument inputs (entrées).
# The function name must contain sagemaker
function_name = "sagemaker-fraud-det-demo-lambda-step"
# Define Lambda helper class can be used to create the Lambda function required in the Lambda step
func = Lambda(
function_name=function_name,
execution_role_arn=sagemaker_role,
script="lambda_deployer.py",
handler="lambda_deployer.lambda_handler",
timeout=600,
memory_size=10240,
)
# The inputs used in the lambda handler are passed through the inputs argument in the
# LambdaStep and retrieved via the `event` object within the `lambda_handler` function
lambda_deploy_step = LambdaStep(
name="LambdaStepRealTimeDeploy",
lambda_func=func,
inputs={
"model_name": pipeline_model_name,
"endpoint_config_name": endpoint_config_name,
"endpoint_name": endpoint_name,
"model_package_arn": register_step.steps[0].properties.ModelPackageArn,
"role": sagemaker_role,
"instance_type": deploy_instance_type_param,
"instance_count": deploy_instance_count_param
}
)Au cours de cette étape, vous utilisez la ConditionStep pour comparer les performances du modèle actuel en fonction de la métrique de l'aire sous la courbe (AUC). Ce n'est que si la performance est supérieure ou égale à un seuil AUC (choisi ici à 0,7) que le pipeline effectue des vérifications de biais et d'explicabilité, enregistre le modèle et le déploie. Des étapes conditionnelles comme celle-ci aident au déploiement sélectif des meilleurs modèles en production. Copiez, collez et exécutez le code suivant pour définir l'étape conditionnelle.
# Evaluate model performance on test set
cond_gte = ConditionGreaterThanOrEqualTo(
left=JsonGet(
step_name=evaluation_step.name,
property_file=evaluation_report,
json_path="classification_metrics.roc_auc.value",
),
right=0.7, # Threshold to compare model performance against
)
condition_step = ConditionStep(
name="CheckFraudDetXGBEvaluation",
conditions=[cond_gte],
if_steps=[create_model_step, model_bias_check_step, model_explainability_step, register_step, lambda_deploy_step],
else_steps=[]
)Étape 4 : création et exécution du pipeline
Après avoir défini toutes les étapes composantes, vous pouvez les assembler dans un objet SageMaker Pipelines. Vous n'avez pas besoin de spécifier l'ordre d'exécution, car SageMaker Pipelines déduit automatiquement la séquence d'exécution en fonction des dépendances entre les étapes.
Copiez, collez et exécutez le bloc de code suivant pour configurer le pipeline. La définition du pipeline reprend tous les paramètres que vous avez définis à l'étape 2 et la liste des étapes composantes. Les étapes telles que la création du modèle, les vérifications de biais et d'explicabilité, l'enregistrement du modèle et le déploiement lambda ne sont pas répertoriées dans la définition du pipeline, car elles ne s'exécutent que si l'étape conditionnelle est évaluée à vrai. Si l'étape conditionnelle est vraie, les étapes suivantes sont exécutées dans l'ordre en fonction de leurs entrées et sorties spécifiées.
# Create the Pipeline with all component steps and parameters
pipeline = Pipeline(
name=pipeline_name,
parameters=[process_instance_type_param,
train_instance_type_param,
train_instance_count_param,
deploy_instance_type_param,
deploy_instance_count_param,
clarify_instance_type_param,
skip_check_model_bias_param,
register_new_baseline_model_bias_param,
supplied_baseline_constraints_model_bias_param,
skip_check_model_explainability_param,
register_new_baseline_model_explainability_param,
supplied_baseline_constraints_model_explainability_param,
model_approval_status_param],
steps=[
process_step,
train_step,
evaluation_step,
condition_step
],
sagemaker_session=sess
)Copiez, collez et exécutez le code suivant dans une cellule de votre bloc-notes. Si le pipeline existe déjà, le code met à jour le pipeline. Si le pipeline n'existe pas, il en crée un. Ignorez les avertissements du kit SDK de SageMaker tels que « No finished training job found associated with this estimator (Aucune tâche d'entraînement terminée associée à cet estimateur). Please make sure this estimator is only used for building workflow config (Veuillez vous assurer que cet estimateur n'est utilisé que pour créer la configuration du flux de travail). »
# Create a new or update existing Pipeline
pipeline.upsert(role_arn=sagemaker_role)
# Full Pipeline description
pipeline_definition = json.loads(pipeline.describe()['PipelineDefinition'])
pipeline_definitionSageMaker encode le pipeline dans un graphe acyclique dirigé (DAG, Directed Acyclic Graph), où chaque nœud représente une étape et les connexions entre les nœuds représentent les dépendances. Pour inspecter le DAG du pipeline à partir de l'interface SageMaker Studio, sélectionnez l'onglet SageMaker Resources (Ressources SageMaker) dans le panneau de gauche, sélectionnez Pipelines dans la liste déroulante, puis choisissez FraudDetectXGBPipeline, Graph (Graphe). Vous pouvez voir que les étapes du pipeline que vous avez créées sont représentées par des nœuds dans le graphique et que les connexions entre les nœuds ont été déduites par SageMaker sur la base des entrées et des sorties fournies dans les définitions des étapes.

Exécutez le pipeline en lançant l'instruction de code suivante. Les paramètres d'exécution du pipeline sont fournis comme arguments dans cette étape. Accédez à l'onglet SageMaker Resources (Ressources SageMaker) dans le panneau de gauche, sélectionnez Pipelines dans la liste déroulante, puis choisissez FraudDetectXGBPipeline, Executions (Exécutions). L'exécution actuelle du pipeline est répertoriée.
# Execute Pipeline
start_response = pipeline.start(parameters=dict(
SkipModelBiasCheck=True,
RegisterNewModelBiasBaseline=True,
SkipModelExplainabilityCheck=True,
RegisterNewModelExplainabilityBaseline=True)
)
Pour examiner l'exécution du pipeline, choisissez l'onglet Statuts (Statut). Lorsque toutes les étapes sont exécutées avec succès, les nœuds du graphique deviennent verts.

Dans l'interface SageMaker Studio, sélectionnez l'onglet SageMaker Resources (Ressources SageMaker) dans le panneau de gauche, puis choisissez Model registry (Registre des modèles) dans la liste déroulante. Le modèle enregistré est répertorié sous Model group name (Nom du groupe de modèles) dans le volet de gauche. Sélectionnez le nom du groupe de modèles pour afficher la liste des versions du modèle. Chaque fois que vous exécutez le pipeline, une nouvelle version du modèle est ajoutée au registre si la version du modèle atteint le seuil conditionnel d'évaluation. Choisissez une version de modèle pour voir les détails, tels que le point de terminaison du modèle et le rapport d'explicabilité du modèle.

Étape 5 : test du pipeline en invoquant le point de terminaison
Dans ce didacticiel, le modèle obtient un score supérieur au seuil choisi de 0,7 AUC. Par conséquent, l'étape conditionnelle enregistre et déploie le modèle vers un point de terminaison d'inférence en temps réel.
Dans l'interface SageMaker Studio, sélectionnez l'onglet SageMaker Resources (Ressources SageMaker) dans le panneau de gauche, choisissez Endpoints (Points de terminaison) et attendez que l'état de fraud-detect-xgb-pipeline-endpoint passe à InService (En service).

Une fois que Endpoint status (Statut du point de terminaison) est passé à InService (En service), copiez, collez et exécutez le code suivant pour appeler le point de terminaison et exécuter les inférences d'exemple. Ce code renvoie les prédictions du modèle pour les cinq premiers échantillons du jeu de données de test.
# Fetch test data to run predictions with the endpoint
test_df = pd.read_csv(f"{processing_output_uri}/test_data/test.csv")
# Create SageMaker Predictor from the deployed endpoint
predictor = sagemaker.predictor.Predictor(endpoint_name,
sagemaker_session=sess,
serializer=CSVSerializer(),
deserializer=CSVDeserializer()
)
# Test endpoint with payload of 5 samples
payload = test_df.drop(["fraud"], axis=1).iloc[:5]
result = predictor.predict(payload.values)
prediction_df = pd.DataFrame()
prediction_df["Prediction"] = result
prediction_df["Label"] = test_df["fraud"].iloc[:5].values
prediction_dfÉtape 6 : nettoyage des ressources
Une bonne pratique consiste à supprimer les ressources que vous n'utilisez plus afin de ne pas encourir de frais imprévus.
Copiez et collez le bloc de code suivant pour supprimer la fonction Lambda, le modèle, la configuration du point de terminaison, le point de terminaison et le pipeline que vous avez créé dans ce didacticiel.
# Delete the Lambda function
func.delete()
# Delete the endpoint
sm_client.delete_endpoint(EndpointName=endpoint_name)
# Delete the EndpointConfig
sm_client.delete_endpoint_config(EndpointConfigName=endpoint_config_name)
# Delete the model
sm_client.delete_model(ModelName=pipeline_model_name)
# Delete the pipeline
sm_client.delete_pipeline(PipelineName=pipeline_name)Pour supprimer le compartiment S3, procédez comme suit :
- Ouvrez la console Amazon S3. Sur la barre de navigation, choisissez Buckets (Compartiments), sagemaker-<votre-région>-<votre-identifiant-de-compte>, puis cochez la case à côté de fraud-detect-demo. Puis choisissez Delete (Supprimer).
- Dans la boîte de dialogue Delete objects (Supprimer des objets), vérifiez que vous avez sélectionné le bon objet à supprimer et saisissez permanently delete (supprimer définitivement) dans la case de confirmation des Permanently delete objects (Supprimer définitivement des objets).
- Une fois que cette opération est terminée et que le compartiment est vide, vous pouvez supprimer le compartiment sagemaker-<votre-région>-<votre-identifiant-de-compte> en suivant à nouveau la même procédure.

Le noyau de Science des données utilisé pour exécuter l'image du bloc-notes dans ce didacticiel accumule les charges jusqu'à ce que vous arrêtiez le noyau ou que vous effectuiez les étapes suivantes pour supprimer les applications. Pour en savoir plus, veuillez consulter la rubrique Shut Down Resources (Arrêt des ressources) dans le Guide du développeur Amazon SageMaker.
Pour supprimer les applications SageMaker Studio, procédez comme suit : dans la console SageMaker Studio, choisissez studio-user, puis supprimez toutes les applications répertoriées sous Apps (Applications) en choisissant Delete app (Supprimer l'application). Attendez que le Status (Statut) de l'état passe à Deleted (Supprimé).

Si vous avez utilisé un domaine SageMaker Studio existant à l'étape 1, ignorez le reste de l'étape 6 et passez directement à la section de conclusion.
Si vous avez exécuté le modèle CloudFormation à l'étape 1 pour créer un domaine SageMaker Studio, poursuivez les étapes suivantes pour supprimer le domaine, l'utilisateur et les ressources créés par le modèle CloudFormation.
Pour ouvrir la console CloudFormation, saisissez CloudFormation dans la barre de recherche de la console AWS, puis choisissez CloudFormation dans les résultats de la recherche.

Dans le volet CloudFormation, choisissez Stacks (Piles). Dans la liste déroulante Status (Statut), sélectionnez Active (Actif). Sous Stack name (Nom de la pile), choisissez CFN-SM-IM-Lambda-Catalog pour ouvrir la page des détails de la pile.

Sur la page de détails de la pile CFN-SM-IM-Lambda-catalog, choisissez Delete (Supprimer) pour supprimer la pile ainsi que les ressources qu'elle a créées à l'étape 1.

Conclusion
Félicitations ! Vous avez terminé le didacticiel Automatisation des flux de travail de machine learning.
Vous avez utilisé avec succès Amazon SageMaker Pipelines pour automatiser le flux de travail de ML de bout en bout, depuis le traitement des données, l'entraînement des modèles, l'évaluation des modèles, la vérification des biais et de l'explicabilité, l'enregistrement des modèles conditionnels et le déploiement. Et pour finir, vous avez utilisé le kit SDK de SageMaker pour déployer le modèle vers un point de terminaison d'inférence en temps réel et l'avez testé avec un échantillon de charge utile.
Vous pouvez poursuivre votre parcours de machine learning avec Amazon SageMaker en suivant la section des prochaines étapes ci-dessous.
Déployer un modèle de machine learning
Entraîner un modèle de deep learning
Trouver d'autres didacticiels pratiques