AWS News Blog
New – Parallel Query for Amazon Aurora

|
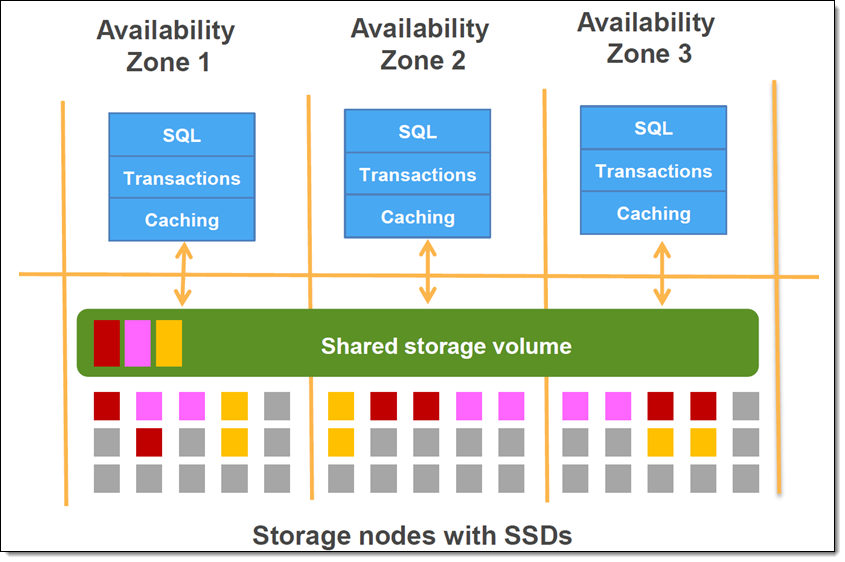
Amazon Aurora is a relational database that was designed to take full advantage of the abundance of networking, processing, and storage resources available in the cloud. While maintaining compatibility with MySQL and PostgreSQL on the user-visible side, Aurora makes use of a modern, purpose-built distributed storage system under the covers. Your data is striped across hundreds of storage nodes distributed over three distinct AWS Availability Zones, with two copies per zone, on fast SSD storage. Here’s what this looks like (extracted from Getting Started with Amazon Aurora):
New Parallel Query
When we launched Aurora we also hinted at our plans to apply the same scale-out design principle to other layers of the database stack. Today I would like to tell you about our next step along that path.
Each node in the storage layer pictured above also includes plenty of processing power. Aurora is now able to make great use of that processing power by taking your analytical queries (generally those that process all or a large part of a good-sized table) and running them in parallel across hundreds or thousands of storage nodes, with speed benefits approaching two orders of magnitude. Because this new model reduces network, CPU, and buffer pool contention, you can run a mix of analytical and transactional queries simultaneously on the same table while maintaining high throughput for both types of queries.
The instance class determines the number of parallel queries that can be active at a given time:
- db.r*.large – 1 concurrent parallel query session
- db.r*.xlarge – 2 concurrent parallel query sessions
- db.r*.2xlarge – 4 concurrent parallel query sessions
- db.r*.4xlarge – 8 concurrent parallel query sessions
- db.r*.8xlarge – 16 concurrent parallel query sessions
- db.r4.16xlarge – 16 concurrent parallel query sessions
You can use the aurora_pq parameter to enable and disable the use of parallel queries at the global and the session level.
Parallel queries enhance the performance of over 200 types of single-table predicates and hash joins. The Aurora query optimizer will automatically decide whether to use Parallel Query based on the size of the table and the amount of table data that is already in memory; you can also use the aurora_pq_force session variable to override the optimizer for testing purposes.
Parallel Query in Action
You will need to create a fresh cluster in order to make use of the Parallel Query feature. You can create one from scratch, or you can restore a snapshot.
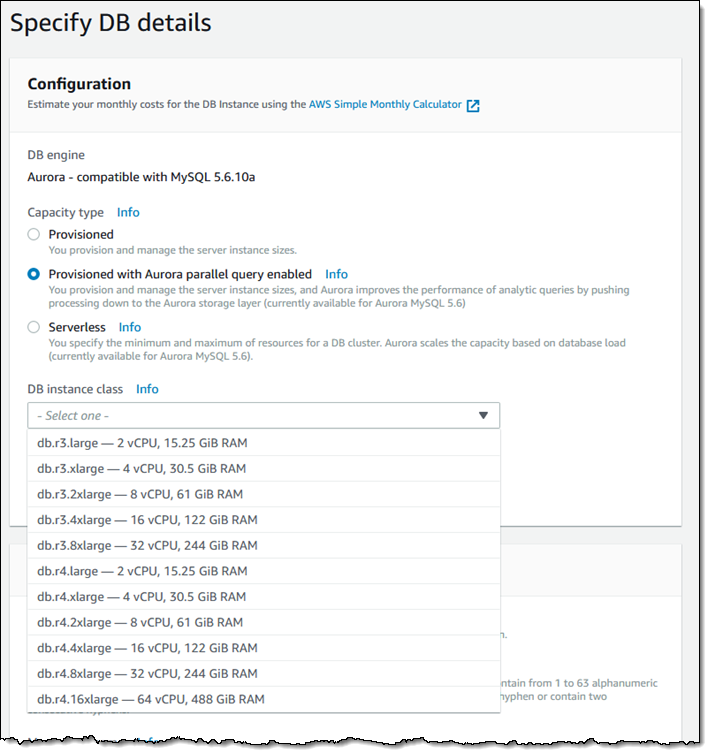
To create a cluster that supports Parallel Query, I simply choose Provisioned with Aurora parallel query enabled as the Capacity type:
I used the CLI to restore a 100 GB snapshot for testing, and then explored one of the queries from the TPC-H benchmark. Here’s the basic query:
The EXPLAIN command shows the query plan, including the use of Parallel Query:
Here is the relevant part of the Extras column:
The query runs in less than 2 minutes when Parallel Query is used:
I can disable Parallel Query for the session (I can use an RDS custom cluster parameter group for a longer-lasting effect):
The query runs considerably slower without it:
This was on a db.r4.2xlarge instance; other instance sizes, data sets, access patterns, and queries will perform differently. I can also override the query optimizer and insist on the use of Parallel Query for testing purposes:
Things to Know
Here are a couple of things to keep in mind when you start to explore Amazon Aurora Parallel Query:
Engine Support - We are launching with support for MySQL 5.6, and are working on support for MySQL 5.7 and PostgreSQL.
Table Formats - The table row format must be COMPACT; partitioned tables are not supported.
Data Types - The TEXT, BLOB, and GEOMETRY data types are not supported.
DDL - The table cannot have any pending fast online DDL operations.
Cost - You can make use of Parallel Query at no extra charge. However, because it makes direct access to storage, there is a possibility that your IO cost will increase.
Give it a Shot
This feature is available now and you can start using it today!
— Jeff;