AWS Storage Blog
Digital transformation at Discover using AWS Storage solutions
One of the biggest challenges any organization can face is how to tackle the notion of digital transformation. Even defining what that means for them and their employees can be a daunting task. For many organizations, that transformation includes a journey to the cloud and starting to examine other new (or new-ish) technologies. One lesson we’ve learned at Discover is not to get so caught up in the “digital” piece of the journey that you lose all sight of the “transformation” aspect. Ultimately, the goal isn’t to deliver new technology for technology’s sake. The goal is for technology to transform an organization’s capability to deliver on their customer promise more effectively (regardless of if those customers are internal or external).
It was with that customer promise in mind that our leadership team at Discover started to focus on our analytics and data science efforts. Part of doing business within the financial space means that we’ve had to be very good at analytics and data science for quite some time. We’ve leveraged analytics for years to gain competitive advantages around fraud detection, decisioning, marketing, and more. As a result, we’ve had individual analytics practices spring up around all of these related business units. Almost all of them had different requirements, different levels of skill, and different tool preferences. There are many very talented people at Discover doing cutting-edge research. From our leadership team’s perspective, it seemed only natural that bringing these people and teams together would help drive improvement in our analytics work across the board. From the technological perspective, we were posed with the problem of figuring out how to bring these people and teams together.
In this blog post, I detail our solution, a platform we developed called Air9. When solving this challenge, one of the first design principles we agreed upon was that there was strength in diversity. Not only in the diversity of the teams and their experiences, but also in varied approaches and tools. We were not going to deliver a one-size fits all approach to data science for this well-established analytics community. That led us to a simple plan, which was to centralize all of our users, tools, and data on to a single platform. This is the platform that would ultimately become Air9.
Before getting into the rest of this blog post, you can check out this video of Discover’s presentation at AWS re:Invent 2019 covering much of the same content:
Choosing the right storage solutions
On our journey to build the Air9 platform, Kubernetes was a natural fit as many of the data science tools naturally lent themselves to containerization. Having dedicated containers and pods allowed for isolated workloads. This isolation allowed users to install custom packages and adjust their environments that would be difficult to manage in a multi-tenant environment like a shared compute cluster. Leveraging Amazon EC2 Auto Scaling allowed for our compute capabilities to expand and contract with demand.
What seemed like a clean approach to a centralized data science platform soon hit a snag when we started to design the storage layer. Our analytics teams have some very large datasets. If you know a data scientist, you know that they very much prefer to work with local datasets as opposed to running their research against a data warehouse. We had some large datasets in our cloud data warehouse, yet we needed our data scientists to have local storage for them to do their individual work. They also needed a mechanism for them to share data among (and across) teams. This storage layer also had to be resilient and support quite a bit of growth over time.
Discover’s technology organization has always skewed towards the “we can build it ourselves” approach to new solutions, and as builders we enjoy those challenges. The team set out to leverage an open-source distributed storage solution as our data science platform’s storage layer. One important characteristic of a build-skewed organization is the ability to fail quickly, iterate on ideas, and know when to move on from an idea that just isn’t working. After spending a few weeks on our in-house distributed storage system, including some very headache inducing conversations about shard keys, I/O patterns, growth projections, and recovery point objectives, we didn’t seem to be making a whole lot of progress. In the meantime, we’d delivered a rudimentary implementation of the platform and saw a fair amount of data start to populate the storage solution from our beta users. Given all of the challenges to get to this point, the team was ambivalent about the solution being feasible and sustainable. Ultimately the decision was made to look for other storage options, and the cost chart below was the final nail in the coffin.

Figure 1: We have a billing problem
Typically, a data science platform is a compute-intensive environment. When we saw the costs associated with running our own storage platform exceed compute costs, we knew that something was wrong (Figure 1). Ultimately, excess cost was attributed to the replication factor for the distributed storage, but the tradeoff for reducing cost (decreasing the replication factor) wasn’t one we were comfortable making.
Since we had been leveraging the scalability of Amazon EC2 so successfully on the compute side of this platform, we reviewed AWS’s managed services for storage. Amazon Elastic File System (Amazon EFS) seemed like it fit the bill as far as scalability and costs. Thanks to some great work from the Kubernetes community, there are already storage class capabilities around EFS, which allowed us to accelerate our integration of EFS into the platform.
The approach for leveraging Amazon EFS is to provide users with two mechanisms for storing their data, their home directory, and their team directories. These storage capabilities are implemented as PersitentVolumeClaims against PersistentVolumes using the EFS storage class. Amazon Simple Storage Service (Amazon S3) also allowed us to customize our backup process so that we could have a second copy of the data available for safe-keeping. This was easy given Amazon S3’s seemingly unlimited storage capabilities and low cost. Overall our raw storage costs were reduced by at least 50% and the time spent managing the storage for this platform was reduced by 90%.
Securing our data science platform
One of the great, and I think unheralded, things about AWS Managed Services is the ability to do everything in a secure manner without much technical investment. We can implement our encryption processes so our datasets are protected at rest in the environment as well as when moving between our cloud environment and our on-premises data centers. In fact, it was so easy to implement, we had a high level of security in our development environments from Day 1. That would have taken weeks to implement on our own, not to mention countless hours to maintain security features.
While encryption is important, it’s not too effective without proper authorization and authentication mechanisms. To that end, we follow our security team’s guidance to mirror authorization similar to what we expect for our on-premises systems. When a user creates a container-based environment for their tool of choice, they are the only user able to log into that environment. This is implemented via LDAP integration, through the Linux-PAM module and the nslcd Linux package. The storage mechanism implements standard POSIX file system permissions and user/group ownership. Through mapping these local users to the container via PAM and adding proper permissions to the PVCs, we created an environment that has all the authorization and authentication capabilities our security teams require for our on-premises solutions (Figure 2). Combined with the fantastic encryption capabilities provided by AWS, we have a very secure data environment for our analytics community.
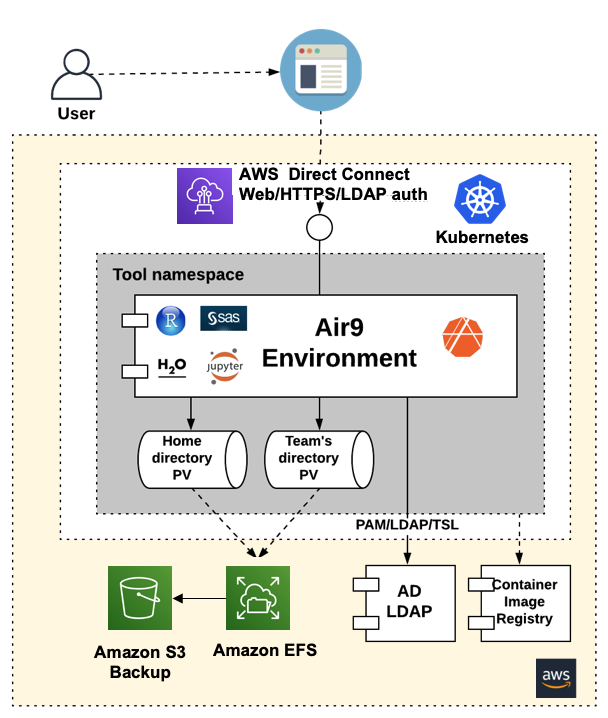
Figure 2: Leveraging AD/LDAP for authorization at the application and storage layers
Optimizing performance with Amazon EFS
We started with security first (as is our standard approach at Discover). There was a growing list of items for our teams to address, and at the top of that list was performance. Many of the operations our analytics teams were running involved I/O-intensive processes. While Amazon EFS has some respectable performance characteristics when properly configured, ultimately it didn’t meet our needs for an ultra-high performing storage layer. Thankfully, AWS recognized this early on and added options that allowed us to meet the requirements of our most advanced users.
Amazon EFS met the majority of our users’ needs, but for those who had some I/O-bound operations, we created a performance storage tier (Figure 3). The tier is derived from specifically provisioned Amazon EC2 instances with NVMe instance stores. We created striped/RAID-0 arrays using the instance stores, and we exposed these local arrays to Kubernetes. Kubernetes provide PVCs against this storage layer to specifically requested user environments via the use of labels and selectors. Since RAID-0 isn’t known for its longevity, we again brought in Amazon S3 to serve as a backup solution. This made sure that our performance-oriented users received the same level of resiliency as those running their analytics from EFS-backed PVCs.
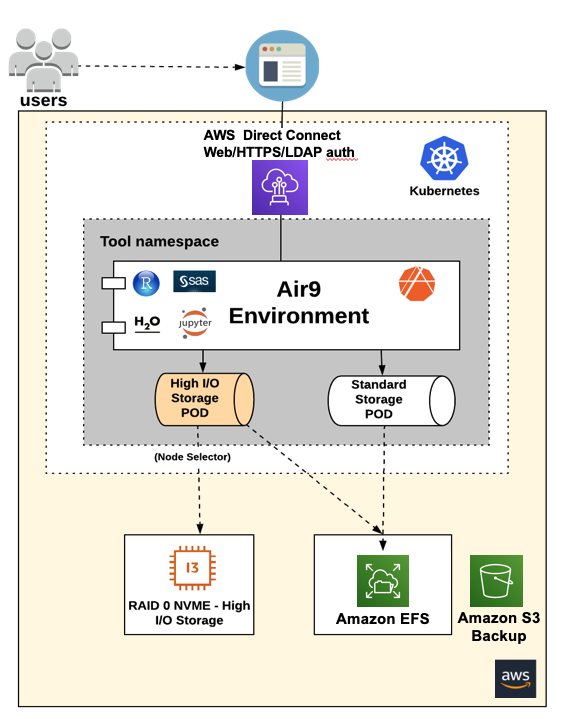
Figure 3: Using NVMe instance stores in RAID-0 as a high-performance storage tier
Discover’s digital transformation journey continues

Figure 4: Discover’s Air9 in-depth architecture
We’ve built out a collaborative platform that has 85% of our data scientists from across the company engaging with each other and sharing code, data, and analytics techniques. In a number of use cases, we’ve seen between 10x-20x improvement in execution time over on-premises systems. We’ve seen the platform pushed to its limits and used in ways we never envisioned. We’ve managed to achieve all of this while delivering over 50% reduction in storage costs thanks to Amazon EFS and Amazon S3.
The digital transformation journey at Discover continues, as do our efforts on the Air9 data science platform, and we’ve learned quite a bit along the way. We learned about ourselves, our strengths and weaknesses, and also about how effective cloud solutions can be in inspiring innovation and new approaches to problem solving for our users. No matter the issues we’ve encountered during this journey, AWS has been a fantastic partner who has been always been responsive to our questions and requests. The partnership between Discover and AWS has truly helped deliver on the promise of digital transformation, and we look forward to continuing to build a future together.
Thanks for reading this blog post and learning more about how Discover uses AWS services. If you have any questions or feedback about what was covered here, please leave a comment and the AWS team will make sure it gets back to us!
The content and opinions in this post are those of the third-party author and AWS is not responsible for the content or accuracy of this post.