Crea, addestra e implementa un modello di machine learning con Amazon SageMaker
TUTORIAL
Introduzione
In questo tutorial, scoprirai come utilizzare Amazon SageMaker per creare, addestrare e implementare un modello di machine learning (ML) usando l'algoritmo di ML XGBoost. Amazon SageMaker è un servizio completamente gestito che consente a ogni sviluppatore e data scientist di creare, addestrare e implementare in modo rapido modelli di machine learning.
Portare i modelli ML dalla concettualizzazione alla produzione è in genere complesso e richiede tempo. È necessario gestire grandi quantità di dati e scegliere l'algoritmo migliore per addestrare il modello, gestire la capacità di calcolo durante l'addestramento e quindi distribuire il modello in un ambiente di produzione. Amazon SageMaker riduce questa complessità semplificando la creazione e implementazione di modelli ML. Dopo che avrai scelto gli algoritmi e i framework più adatti dalla vasta gamma di opzioni disponibili, SageMaker gestisce tutta l'infrastruttura sottostante per addestrare il modello su scala petabyte e implementarlo in produzione.
In questo tutorial, assumerai il ruolo di uno sviluppatore di machine learning che lavora in una banca. Ti è stato chiesto di sviluppare un modello di machine learning per prevedere se un cliente richiederà un certificato di deposito (CD).
In questo tutorial, imparerai come:
- Creare un'istanza del notebook SageMaker
- Preparare i dati
- Addestrare il modello per apprendere dai dati
- Distribuzione del modello
- Valutare le prestazioni del modello ML
Il modello verrà addestrato sul set di dati di marketing della banca che contiene informazioni sui dati demografici dei clienti, risposte a eventi di marketing e fattori esterni. I dati sono stati etichettati per comodità dell'utente e una colonna nel set di dati identifica se il cliente è censito per un prodotto offerto dalla banca. Una versione di questo set di dati è disponibile pubblicamente nel repository di machine learning a cura dell'Università della California, Irvine.
Le risorse create e utilizzate in questo tutorial sono idonee per il piano gratuito AWS. Il costo di questo workshop è inferiore a 1 USD.
Esperienza AWS
Principiante
Tempo per il completamento
10 minuti
Costo richiesto per il completamento
Meno di 1 USD. Idoneo per il Piano gratuito.
Requisiti
- Account AWS
- Browser consigliato: l'ultima versione di Chrome o Firefox
[**]Gli account creati nelle ultime 24 ore potrebbero non avere ancora accesso a tutti i servizi richiesti per questo tutorial.
Servizi utilizzati
Ultimo aggiornamento
23 agosto 2022
Prima di iniziare
Devi disporre di un account AWS per completare questo tutorial. Se non disponi ancora di un account, fai clic su Iscriviti ad AWS e crea un nuovo account.
Hai già un account?
Accedi all'account AWS
Fase 1: Creazione di un'istanza del notebook Amazon SageMaker
In questa fase, crei l'istanza notebook da utilizzare per scaricare ed elaborare i dati. Come parte del processo di creazione, crei anche un ruolo di Identity and Access Management (IAM) che consente ad Amazon SageMaker di accedere ai dati in Amazon Simple Storage Service (Amazon S3).
a. Accedi alla console Amazon SageMaker e, nell'angolo in alto a destra, seleziona la tua Regione AWS preferita. Questo tutorial utilizza la Regione Stati Uniti occidentali (Oregon).

b. Nel riquadro di navigazione a sinistra, scegli Istanze del notebook, quindi scegli Crea istanza del notebook.

c. Nella pagina Crea istanza del notebook, nella casella delle impostazioni dell'istanza del notebook, compila i seguenti campi:
- Per il nome dell'istanza del notebook, digita SageMaker-Tutorial.
- Per tipo di istanza del notebook, scegli ml.t2.medium.
- Per l'inferenza elastica, mantieni la selezione predefinita, ovvero nessuna.
- Per l'identificatore della piattaforma, mantieni la selezione predefinita.

d. Nella sezione Autorizzazioni e crittografia, per il ruolo IAM, scegli Crea un nuovo ruolo e nella finestra di dialogo Crea un ruolo IAM, seleziona Qualsiasi bucket S3 e scegli Crea ruolo.
Nota: Se desideri utilizzare un bucket di cui disponi già, seleziona Bucket S3 specifici e specifica il nome del bucket.

Amazon SageMaker crea il ruolo AmazonSageMaker-ExecutionRole-***.

e. Mantieni le impostazioni predefinite per le opzioni rimanenti e scegli Crea istanza del notebook.
Nella sezione Istanze del notebook, la nuova istanza del notebook SageMaker-Tutorial viene visualizzata con lo stato In sospeso. Il notebook sarà pronto quando lo stato diventa InService.

Fase 2: Preparazione dei dati
In questa fase, utilizzi la tua istanza del notebook Amazon SageMaker per pre-elaborare i dati necessari per addestrare il tuo modello di machine learning e quindi caricare i dati su Amazon S3.
a. Dopo che lo stato dell'istanza del notebook SageMaker-Tutorial è cambiato in InService, scegli Apri Jupyter.

b. In Jupyter, scegli Nuovo e quindi scegli conda_python3.

c. Nel tuo notebook Jupyter, copia e incolla il codice seguente in una nuova cella del codice e seleziona Esegui.
Questo codice importa le librerie richieste e definisce le variabili di ambiente necessarie per preparare i dati e addestrare e distribuire il modello ML.
# import libraries
import boto3, re, sys, math, json, os, sagemaker, urllib.request
from sagemaker import get_execution_role
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from IPython.display import Image
from IPython.display import display
from time import gmtime, strftime
from sagemaker.predictor import csv_serializer
# Define IAM role
role = get_execution_role()
prefix = 'sagemaker/DEMO-xgboost-dm'
my_region = boto3.session.Session().region_name # set the region of the instance
# this line automatically looks for the XGBoost image URI and builds an XGBoost container.
xgboost_container = sagemaker.image_uris.retrieve("xgboost", my_region, "latest")
print("Success - the MySageMakerInstance is in the " + my_region + " region. You will use the " + xgboost_container + " container for your SageMaker endpoint.")
d. Crea il bucket S3 per archiviare i tuoi dati. Copia e incolla il codice seguente nella cella di codice successiva e seleziona Esegui.
Nota: Assicurati di sostituire il bucket_name your-s3-bucket-name con un nome di bucket S3 univoco. Se non ricevi un messaggio di successo dopo aver eseguito il codice, modifica il nome del bucket e riprova.
bucket_name = 'your-s3-bucket-name' # <--- CHANGE THIS VARIABLE TO A UNIQUE NAME FOR YOUR BUCKET
s3 = boto3.resource('s3')
try:
if my_region == 'us-east-1':
s3.create_bucket(Bucket=bucket_name)
else:
s3.create_bucket(Bucket=bucket_name, CreateBucketConfiguration={ 'LocationConstraint': my_region })
print('S3 bucket created successfully')
except Exception as e:
print('S3 error: ',e)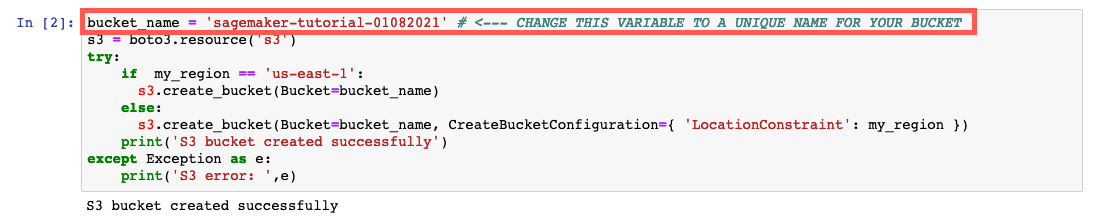
e. Scarica i dati sulla tua istanza SageMaker e carica i dati in un dataframe. Copia e incolla il codice seguente nella cella di codice successiva e seleziona Esegui.
try:
urllib.request.urlretrieve ("https://d1.awsstatic.com/tmt/build-train-deploy-machine-learning-model-sagemaker/bank_clean.27f01fbbdf43271788427f3682996ae29ceca05d.csv", "bank_clean.csv")
print('Success: downloaded bank_clean.csv.')
except Exception as e:
print('Data load error: ',e)
try:
model_data = pd.read_csv('./bank_clean.csv',index_col=0)
print('Success: Data loaded into dataframe.')
except Exception as e:
print('Data load error: ',e)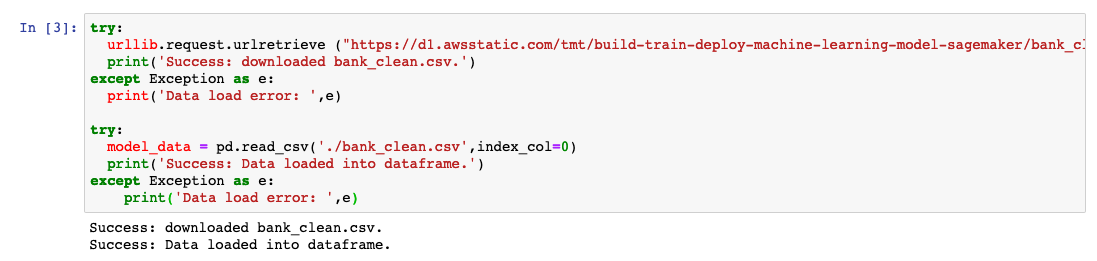
f. Mescola e dividi i dati in dati di addestramento e dati di test. Copia e incolla il codice seguente nella cella di codice successiva e seleziona Esegui.
I dati di addestramento (il 70% dei clienti) vengono utilizzati durante il ciclo di addestramento del modello. Utilizza l'ottimizzazione basata sul gradiente per perfezionare in modo iterativo i parametri del modello. L'ottimizzazione basata sul gradiente è un modo per trovare i valori dei parametri del modello che riducono al minimo l'errore del modello, usando il gradiente della funzione di perdita del modello.
I dati di test (il restante 30% dei clienti) vengono utilizzati per valutare le prestazioni del modello e misurano quanto il modello addestrato si generalizza rispetto ai dati invisibili.
train_data, test_data = np.split(model_data.sample(frac=1, random_state=1729), [int(0.7 * len(model_data))])
print(train_data.shape, test_data.shape)
Fase 3: Addestramento del modello ML
In questa fase, il modello di machine learning verrà addestrato con il set di dati di addestramento.
a. Nel tuo notebook Jupyter, copia e incolla il codice seguente in una nuova cella del codice e seleziona Esegui.
Questo codice riformatta l'intestazione e la prima colonna dei dati di addestramento e quindi carica i dati dal bucket S3. Questo passaggio è necessario per utilizzare l'algoritmo XGBoost predefinito di Amazon SageMaker.
pd.concat([train_data['y_yes'], train_data.drop(['y_no', 'y_yes'], axis=1)], axis=1).to_csv('train.csv', index=False, header=False)
boto3.Session().resource('s3').Bucket(bucket_name).Object(os.path.join(prefix, 'train/train.csv')).upload_file('train.csv')
s3_input_train = sagemaker.inputs.TrainingInput(s3_data='s3://{}/{}/train'.format(bucket_name, prefix), content_type='csv')
b. Imposta la sessione Amazon SageMaker, crea un'istanza del modello XGBoost (uno stimatore) e definisci gli iperparametri del modello. Copia e incolla il codice seguente nella cella di codice successiva e seleziona Esegui.
sess = sagemaker.Session()
xgb = sagemaker.estimator.Estimator(xgboost_container,role, instance_count=1, instance_type='ml.m4.xlarge',output_path='s3://{}/{}/output'.format(bucket_name, prefix),sagemaker_session=sess)
xgb.set_hyperparameters(max_depth=5,eta=0.2,gamma=4,min_child_weight=6,subsample=0.8,silent=0,objective='binary:logistic',num_round=100)
c. Inizia il lavoro di addestramento. Copia e incolla il codice seguente nella cella di codice successiva e seleziona Esegui.
Questo codice addestra il modello utilizzando l'ottimizzazione del gradiente su un'istanza ml.m4.xlarge. Dopo alcuni minuti, dovresti vedere i log di addestramento generati nel tuo notebook Jupyter.
xgb.fit({'train': s3_input_train})
Fase 4: Implementazione del modello
In questa fase, implementi il modello addestrato su un endpoint, riformatti e carichi i dati CSV, quindi esegui il modello per creare previsioni.
a. Nel tuo notebook Jupyter, copia e incolla il codice seguente in una nuova cella del codice e seleziona Esegui.
Questo codice distribuisce il modello su un server e crea un endpoint SageMaker a cui puoi accedere. Il completamento di questo processo può richiedere alcuni minuti.
xgb_predictor = xgb.deploy(initial_instance_count=1,instance_type='ml.m4.xlarge')
b. Per prevedere se i clienti nei dati di test sono stati censiti o meno per il prodotto bancario, copia il codice seguente nella cella di codice successiva e seleziona Esegui.
from sagemaker.serializers import CSVSerializer
test_data_array = test_data.drop(['y_no', 'y_yes'], axis=1).values #load the data into an array
xgb_predictor.serializer = CSVSerializer() # set the serializer type
predictions = xgb_predictor.predict(test_data_array).decode('utf-8') # predict!
predictions_array = np.fromstring(predictions[1:], sep=',') # and turn the prediction into an array
print(predictions_array.shape)
Fase 5: Valutazione delle prestazioni del modello
In questa fase, valuterai le prestazioni e l'accuratezza del modello di machine learning.
Nel tuo notebook Jupyter, copia e incolla il codice seguente in una nuova cella del codice e seleziona Esegui.
Questo codice confronta i valori effettivi e previsti in una tabella denominata matrice di confusione.
Sulla base della previsione, possiamo concludere che hai stimato che un cliente richiederà un certificato di deposito con una precisione del 90% per i clienti nei dati di test, con una precisione del 65% (278/429) per i clienti censiti e del 90% (10.785/11.928) per i clienti non censiti.
cm = pd.crosstab(index=test_data['y_yes'], columns=np.round(predictions_array), rownames=['Observed'], colnames=['Predicted'])
tn = cm.iloc[0,0]; fn = cm.iloc[1,0]; tp = cm.iloc[1,1]; fp = cm.iloc[0,1]; p = (tp+tn)/(tp+tn+fp+fn)*100
print("\n{0:<20}{1:<4.1f}%\n".format("Overall Classification Rate: ", p))
print("{0:<15}{1:<15}{2:>8}".format("Predicted", "No Purchase", "Purchase"))
print("Observed")
print("{0:<15}{1:<2.0f}% ({2:<}){3:>6.0f}% ({4:<})".format("No Purchase", tn/(tn+fn)*100,tn, fp/(tp+fp)*100, fp))
print("{0:<16}{1:<1.0f}% ({2:<}){3:>7.0f}% ({4:<}) \n".format("Purchase", fn/(tn+fn)*100,fn, tp/(tp+fp)*100, tp))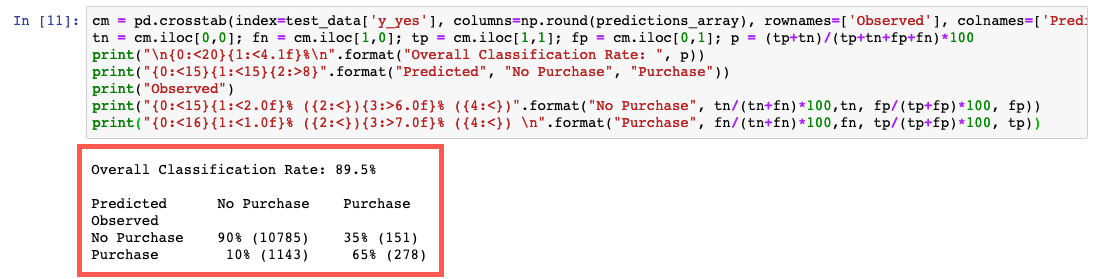
Fase 6: Eliminazione
In questo passaggio, è necessario arrestare le risorse utilizzate in questo laboratorio.
Importante: l'arresto delle risorse che non vengono utilizzate attivamente consente di ridurre i costi e costituisce una best practice. La mancata interruzione delle risorse determinerà costi non desiderati.
a. Elimina il tuo endpoint: nel tuo notebook Jupyter, copia e incolla il seguente codice e seleziona Esegui.
xgb_predictor.delete_endpoint(delete_endpoint_config=True)b. Elimina gli artefatti di addestramento e il bucket S3: nel tuo notebook Jupyter, copia e incolla il seguente codice e scegli Esegui.
bucket_to_delete = boto3.resource('s3').Bucket(bucket_name)
bucket_to_delete.objects.all().delete()c. Elimina il tuo notebook SageMaker: arresta ed elimina il tuo notebook SageMaker.
- Apri la console SageMaker.
- In Notebook, scegli Istanze del notebook.
- Scegli l'istanza del notebook che hai creato per questo tutorial, quindi scegli Azioni, Arresta. L'interruzione dell'istanza del notebook richiede diversi minuti. Quando lo stato cambia in Interrotto, passa alla fase successiva.
- Scegli Azioni, quindi Elimina.
- Seleziona Elimina.
Conclusioni
Hai imparato a utilizzare Amazon SageMaker per preparare, addestrare, implementare e valutare un modello di machine learning. Amazon SageMaker semplifica la creazione di modelli ML fornendoti tutto il necessario per connetterti rapidamente ai dati di addestramento e selezionare l'algoritmo e il framework migliori per la tua applicazione, gestendo al contempo tutta l'infrastruttura sottostante, affinché tu possa addestrare modelli su scala petabyte.
Fasi successive
Ora che hai preparato, addestrato, implementato e valutato un modello di machine learning, puoi basarti su ciò che hai appreso esplorando altre risorse Amazon SageMaker.