Amazon Web Services ブログ
Amazon SageMaker Ground Truth を使って、セマンティックセグメンテーションのラベル付けを実行する際にオブジェクトを自動セグメント化する
Amazon SageMaker Ground Truth は、機械学習 (ML) 用の高精度なトレーニングデータセットをすばやく構築できるよう支援します。Ground Truth で、サードパーティおよび独自のラベル付けを行う人間の作業者に簡単にアクセスでき、一般的なラベル付けタスク用のビルトインのワークフローとインターフェースも提供できるようになります。さらに、Ground Truth では自動データラベル付けを使用して、ラベル付けのコストが最大 70% 削減します。自動データラベル付けとは、人間がラベルを付けたデータから Ground Truth をトレーニングし、サービスが独自にデータにラベルを付けることを学習するものです。
セマンティックセグメンテーションとは、画像内の個々のピクセルにクラスラベルを割り当てるなどのコンピュータービジョン ML の手法です。たとえば、移動中の車両が撮像した動画フレームで、クラスラベルに車両、歩行者、道路、信号機、建物、背景を含めることが可能です。画像内のさまざまなオブジェクトの位置を高い精度で理解することができるため、自律走行車やロボットの知覚システムの構築によく使用されます。セマンティックセグメンテーション用の ML モデルを構築するには、まずピクセルレベルで大量のデータにラベルを付ける必要があります。しかし、このラベル付けプロセスが複雑で、熟練したラベル付けの作業者とかなりの時間を要します。画像を正確にラベリングするのに最大 2 時間もかかる場合もあります。
Ground Truth ではセマンティックセグメンテーションのラベリングユーザーインターフェイスに自動セグメント機能を追加し、ラベル付けスループットと精度を向上し、かつ作業者の疲労を軽減することを目指しました。自動セグメント化ツールでは、最小限の入力だけで画像内の関心対象の領域に自動的にラベルを付けることができるため、タスクが簡素化します。これで、自動セグメントからの結果出力を受け入れる、元に戻す、または修正することができます。次のスクリーンショットは、ツールバーの自動セグメント化機能部分を強調し、画像内の犬をオブジェクトとしてキャプションしたことを示しています。この犬に割り当てられたラベルは Bubbles です。
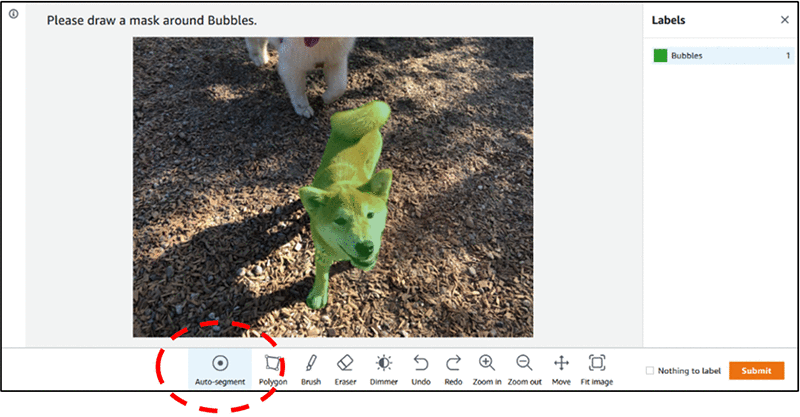
この新機能で、セマンティックセグメンテーションタスクの作業が最大 10 倍早くなります。多角形をきっちり描画したり、ブラシツールを使って画像内のオブジェクトをキャプションする必要はなく、オブジェクトの最上部、最下部、左端、右端の 4 つの部分を描画するだけです。Ground Truth はこれら 4 つのポイントを入力すると、Deep Extreme Cut (DEXTR) アルゴリズムを使用して、オブジェクトの周りにぴったりとフィットするマスクを生成します。次のデモは、このツールでより複雑なラベル付けタスクのスループットを高速化する方法をご紹介しています。
まとめ
この投稿では、セマンティックセグメンテーションと呼ばれるコンピュータービジョン ML の手法の目的と複雑さについてご紹介しました。自動セグメント化機能を使えば、作業者による最小限の入力で画像の関心領域のセグメンテーションを自動化でき、セマンティックセグメンテーションのラベリングタスクが高速化します。
いつものように、AWS では皆さんのフィードバックをお待ちしています。コメント欄よりご意見やご質問をお送りください。
著者について
 Krzysztof Chalupka は Amazon ML Solutions Lab のアプライドサイエンティストです。カリフォルニア工科大学で、因果推論とコンピュータービジョンの博士号を取得しました。Amazon では、コンピュータービジョンと深層学習で人間の知能を高める方法を解明しています。仕事以外の時間は家族とともに過ごし、森、木工細工 (あらゆる形態の木) 、そして読書も大好きです。
Krzysztof Chalupka は Amazon ML Solutions Lab のアプライドサイエンティストです。カリフォルニア工科大学で、因果推論とコンピュータービジョンの博士号を取得しました。Amazon では、コンピュータービジョンと深層学習で人間の知能を高める方法を解明しています。仕事以外の時間は家族とともに過ごし、森、木工細工 (あらゆる形態の木) 、そして読書も大好きです。
 Vikram Madan は Amazon SageMaker Ground Truth のプロダクトマネージャーです。機械学習ソリューションの構築を容易にする製品の提供に、力を注いでいます。余暇には、長距離のランニングやドキュメンタリーの鑑賞などをして過ごしています。
Vikram Madan は Amazon SageMaker Ground Truth のプロダクトマネージャーです。機械学習ソリューションの構築を容易にする製品の提供に、力を注いでいます。余暇には、長距離のランニングやドキュメンタリーの鑑賞などをして過ごしています。