Amazon Web Services ブログ
AWS Glue を使用することによってオンプレミスデータストアにアクセスして分析する方法
AWS Glue は、データのカタログ化、クリーニング、強化を行い、様々なデータストア間で確実に移動させる完全マネージド型 ETL (抽出、変換、ロード) サービスです。AWS Glue ETL ジョブは、AWS 環境の内外にある多種多様なデータソースとやり取りすることができます。ハイブリッド環境での最適な運用には、AWS Glue に追加のネットワーク、ファイアウォール、または DNS 設定が必要になる場合があります。
この記事では、一般的なデータレイクの取り込みパイプラインをシミュレートする、AWS Glue を使用したデータの変換と、オンプレミスデータストアから Amazon S3 へのデータの移動のためのソリューションについて説明します。AWS Glue は、Amazon S3 と、Amazon RDS、Amazon Redshift、または Amazon EC2 で実行されているデータベースなどの Virtual Private Cloud (VPC) に接続できます。詳細については、「データストアに接続を追加する」を参照してください。AWS Glue は、PostgreSQL、MySQL、Oracle、Microsoft SQL サーバー、および MariaDB などの各種オンプレミス JDBC データストアにも接続できます。
AWS Glue ETL ジョブは、Amazon S3、VPC 内のデータストア、またはオンプレミス JDBC データストアをソースとして使用できます。AWS Glue ジョブはデータを抽出し、それを変換して、結果として生成されたデータを S3、VPC 内のデータストア、またはオンプレミス JDBC データストアをターゲットとしてロードします。
以下の図は、この記事で説明するハイブリッド環境内で AWS Glue を使用するアーキテクチャを示しています。このソリューションは、Amazon VPC 内の Elastic Network Interface (ENI) を用いる JDBC 接続を使用します。VPC 内の ENI は、仮想プライベートネットワーク (VPN) または AWS Direct Connect (DX) を経由してオンプレミスデータベースサーバーに接続するために役立ちます。
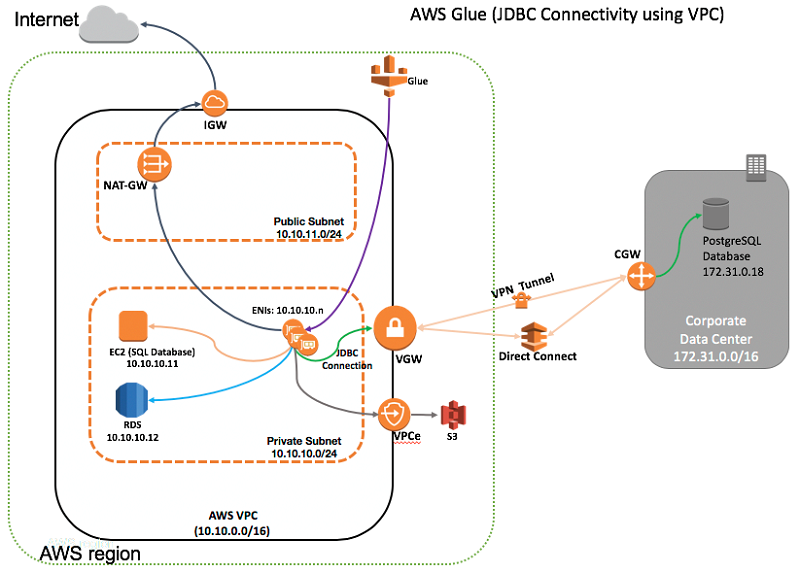
図に示されたソリューションアーキテクチャは、以下のように機能します。
- 仮想プライベートネットワーク (VPN) または AWS Direct Connect (DX) を使用したネットワーク接続が Amazon VPC とオンプレミスネットワークの間に存在する。
- JDBC 接続がデータストアのパラメーターを定義する — 例えば、オンプレミスネットワーク上で実行される PostgreSQL サーバーへの JDBC 接続などです。
- AWS Glue が VPC/プライベートサブネットで Elastic Network Interfaces (ENI) を作成する。これらのネットワークインターフェイスは、この後、VPC 経由で AWS Glue のためのネットワーク接続を提供します。
- ENI にアタッチされたセキュリティグループが、選択された JDBC 接続によって設定される。
- ENI の数が AWS Glue ETL ジョブ用に選択されたデータ処理ユニット (DPU) の台数に応じて異なる。AWS Glue DPU インスタンスは互いに通信し、JDBC 対応データベースとも ENI を使用して通信します。
- AWS Glue が、VPN または DX 接続経由でオンプレミスデータストアと通信できる。Elastic Network Interface は、VPC レベルのルーティングを使用して、同じサブネットまたは異なるサブネット内の EC2 データベースインスタンスまたは RDS インスタンスにアクセスできます。ENI は、同じ AWS リージョン内の異なる VPC 内にあるデータベースインスタンスにアクセスすることもでき、別のリージョン内の場合は VPC ピアリングを使ってアクセスできます。
- AWS Glue が Amazon S3 を使用して ETL スクリプトと一時ファイルを保存する。S3 は、変換されたデータのためのソースおよびターゲットにすることもできます。Amazon S3 VPC エンドポイント (VPCe) は、「Amazon S3 における Amazon VPC エンドポイント」で説明されているとおり、S3 へのアクセスを提供します。
- オプションとして、AWS Glue ETL ジョブにパブリック API を使用した AWS のサービスへのアクセス、または発信インターネットアクセスが必要となる場合は、パブリックサブネット内の NAT ゲートウェイまたは NAT インスタンスのセットアップがインターネットへのアクセスを提供する。
- AWS Glue クローラが S3 または JDBC 接続を使用してデータソースをカタログ化し、AWS Glue ETL ジョブが S3 または JDBC 接続をソースまたはターゲットデータストアとして使用する。
以下のウォークスルーは、まずオンプレミスデータストアのために JDBC 接続を準備する手順について説明します。次に、AWS Glue で JDBC 接続を使用することによって、サンプルデータに ETL 操作を実行する方法を説明します。
オンプレミスデータストアのための JDBC 接続の準備
これらの手順に従って JDBC 接続をセットアップします。
ステップ 1: VPC で AWS Glue ENI のためのセキュリティグループを作成する
AWS Glue がそのコンポーネントと通信できるようにするには、すべての TCP ポートに対して自己参照のインバウンドルールを持つセキュリティグループを指定します。この例では、このセキュリティグループを glue-security-group と呼びます。セキュリティグループは、指定された VPC/サブネット内の AWS Glue Elastic Network Interface にアタッチします。これは、VPC/サブネット内の ENI 間における無制限の通信を可能にし、他の詳細不明ソースからの着信ネットワークアクセスを防ぎます。

デフォルトで、セキュリティグループはすべてのアウトバウンドトラフィックを許可し、AWS Glue 要件を十分に満たします。
希望する場合は、オプションで、特定の AWS Glue ETL ジョブに必要な一部のネットワークトラフィックへのアウトバウンドアクセスを制限することができます。例えば、以下のセキュリティグループセットアップは、オンプレミス PostgreSQL データベースに対して、JDBC 接続を使った AWS Glue ETL ジョブに必要な最小限の発信ネットワークトラフィックを有効にします。お使いの設定はこれと異なる場合があるため、特定のセットアップに応じてアウトバウンドルールを編集してください。

この例では、以下のアウトバウンドトラフィックが許可されています。これらのルールは、セットアップに応じて編集してください。
- AWS Glue がそのコンポーネントと通信できるようにするには、すべての TCP ポートに対して自己参照のアウトバウンドルールを持つセキュリティグループを指定します。これは、VPC/サブネット内の AWS Glue ENI 間における無制限の通信を可能にします。
- ポート 5432/tcp: オンプレミス PostgreSQL データベースサーバーにアクセスするためのものです。
- ポート 53/udp、ポート 53/tcp: オンプレミス DNS サーバー、または EC2 インスタンスで実行される DNS サーバーなど、カスタム DNS サーバーを使用するときの DNS 解決に必要です。宛先は、セットアップに応じて変更してください。
- ポート 443/tcp: ETL ジョブが実行されている AWS リージョンについて、すべての S3 IP アドレス範囲へのトラフィックを許可します。この例では、us-east-1 リージョンについて、VPCe 経由のアウトバウンドトラフィックがすべての S3 IP プレフィックスに許可されています。S3 バケットが異なるリージョンに置かれている場合は、これらのルールを適切に編集してください。
AWS は、S3 とその他サービスのために、JSON フォーマットの IP 範囲を発行します。IP 範囲のデータは、時折変更されます。「AWS IP アドレスの範囲」の説明に従って変更通知にサブスクライブし、それに応じてセキュリティグループを更新してください。
以下のコマンド例は、JSON データを解析し、us-east-1 リージョンの現行 S3 IP プレフィックスをすべてリストするために、curl と jq ツールを使用します。S3 VPC エンドポイントを使用しているか、NAT ゲートウェイのセットアップ経由で S3 パブリックエンドポイントにアクセスしているかにかかわらず、S3 アウトバウンドアクセスのためのセキュリティグループにこれらを使用してください。
ステップ 2: AWS Glue のための IAM ロールを作成する
AWS Glue サービスのための IAM ロールを作成します。ロールタイプには、[AWS サービス]、[Glue] と選択します。詳細情報については、「AWS Glue 用の IAM ロールを作成する」を参照してください。
AWS Glue サービスと S3 バケットへのアクセスを許可するための IAM ポリシーを追加します。この例では、IAM ロールは glue_access_s3_full です。
ステップ 3: JDBC 接続を追加する
JDBC 接続を追加するには、AWS Glue コンソールのナビゲーションペインで [接続の追加] を選択します。接続名を入力し、接続タイプに [JDBC] を選択して、[次へ] を選択します。

次の画面で、以下の情報を提供します。
- データストアの JDBC URL を入力します。このフィールドは、ほとんどのデータベースエンジンに対して以下のフォーマットになります。
詳細については、「AWS Glue コンソールでの接続の操作」を参照してください。この例では、IP アドレス 172.31.0.18 を持つオンプレミス PostgreSQL サーバー用に、jdbc:postgresql://172.31.0.18:5432/glue_demo という JDBC URL を使用します。PostgreSQL サーバーは、デフォルトのポート 5432 でリッスンし、glue_demo データベースにデータを提供します。
- データベースのユーザー名とパスワードを入力します。最小権限の原則に従って、データベースユーザーには必要な許可のみを付与してください。
- VPC、プライベートサブネット、および先ほど作成したセキュリティグループ glue-security-group を選択します。AWS Glue はプライベートサブネット内に複数の ENI を作成し、ネットワーク経由での通信のためにセキュリティグループを関連付けます。
- 以下にあるとおり、情報を見直して残りのセットアップを完了します。

ステップ 4: オンプレミスデータセンターで適切なファイアウォールポートを開く
オンプレミスのファイアウォール設定を編集して、前のステップで JDBC 接続用に選択したプライベートサブネットからの受信接続を許可します。AWS Glue は、ENI を作成するときに、プライベートサブネットの使用可能な IP アドレスをどれでも選択できます。ここで説明する例には、オンプレミスのファイアウォールが、ネットワークブロック 10.10.10.0/24 からポート 5432/tcp で実行されている PostgreSQL データベースへの受信接続を許可する必要があります。
また、PostgreSQL 用のデータベース固有のファイル (pg_hba.conf など) を編集して、リモートネットワークブロックからの受信接続を許可する行を追加する必要がある場合もあります。このような受信接続は、お使いのデータベースエンジンに固有のドキュメントに従って有効化してください。
ステップ 5: JDBC 接続をテストする
AWS Glue コンソールで JDBC 接続を選択し、[接続のテスト] を選択します。前のステップで作成した IAM ロールを選択して、[接続のテスト] を選択します。結果が表示されるまでに、数分かかる場合があります。エラーを受け取った場合は、以下をチェックしてください。
- 正しい JDBC URL が提供されている。
- 必要な特権を持つデータベースに対して、正しいユーザー名とパスワードが提供されている。
- AWS Glue ENI のために正しいネットワークルーティングパスがセットアップされており、サブネットからのデータベースポートアクセスが選択されている。
- ENI のセキュリティグループが、それらの間における必要な受信および送信トラフィック、データベースへの発信アクセス、カスタム DNS サーバーへのアクセス (使用されている場合) 、および Amazon S3 へのネットワークアクセスを許可している。
これで、AWS Glue ジョブで JDBC 接続を使用する準備ができました。
JDBC 接続を使用した AWS Glue での ETL の実行
このセクションでは、JDBC 接続と、アメリカ国勢調査局のサイトで公開されている全国貨物純流動調査 (CFS) オープンデータセットからのサンプル CSV データを使用した ETL 操作のデモを行います。この例は、以下のように、サンプルデータを使用して 2 つの ETL ジョブのデモを実行します。
- パート 1: AWS Glue ETL ジョブが JDBC 接続 を使用して、S3 バケットからオンプレミス PostgreSQL データベースにサンプル CSV データファイルをロードします。この後、データセットはパート 2 でオンプレミス PostgreSQL データベースサーバー内のデータソースとして機能します。
- パート 2: AWS Glue ETL ジョブが、オンプレミス PostgreSQL データベースからターゲット S3 バケットへのソースデータを Apache Parquet フォーマットに変換します。
各パートでは、AWS Glue が、「クローラを使用してテーブルを分類する」で説明されているように、S3 バケット、または JDBC 対応データベースに保存された既存のデータをクロールします。クローラは、ソースデータをサンプリングして、AWS Glue Data Catalog にメタデータを構築します。次に、「AWS Glue でジョブを追加する」で説明されているとおりに、Data Catalog メタデータを参照する ETL ジョブを構築します。
オプションとして、AWS Glue API を使って、Data Catalog に直接メタデータを構築する他の手法を使用することもできます。AWS Glue コンソール、AWS CloudFormation テンプレート、または AWS CLI を使用することによって、Data Catalog に手動でデータを投入することができます。また、Boto 3 Python ライブラリを使用することによって、pySpark ETL ジョブ内に Data Catalog メタデータを構築し、更新することも可能です。Data Catalog は Hive Metastore 対応で、GitHub ウェブサイトにあるこの README ファイルの説明通りに、既存の Hive Metastore を AWS Glue に移行することができます。
パート 1: AWS Glue ETL ジョブで S3 バケット からオンプレミス PostgreSQL データベースに CSV データをロードする
お使いのコンピュータにサンプル CSV データファイルをダウンロードして、ファイルを解凍することから始めます。解凍された CSV ファイル、cfs_2012_pumf_csv.txt を S3 バケットにアップロードします。CSV データファイルは、S3 バケット内のデータソースとして AWS Glue ETL ジョブ用に使用できます。サンプル CSV データファイルには、以下にあるように、ヘッダー行とデータ数行が含まれています。

まず、クローラをセットアップして、S3 データソースのために AWS Glue Data Catalog のテーブルメタデータにデータを投入します。AWS Glue コンソールのナビゲーションペインで [クローラ] を選択することから始めます。次に、[クローラの追加] を選択します。クローラの名前を指定します。
データソースについて尋ねられたら、S3 を選択して CSV サンプルデータファイルがある S3 バケットプレフィックスを指定します。S3 プレフィックスには、ひとつ、または複数の CSV ファイルを置くことができます。AWS Glue クローラがサンプルデータをクロールし、テーブルスキーマを生成します。

次に、先ほど作成した IAM ロールを選択します。IAM ロール は、アクセス AWS Glue サービスと S3 バケットへのアクセスを許可する必要があります。

次に、Data Catalog 内の既存のデータベースを選択、または新しいデータベースエントリを作成します。この例では、cfs が Data Catalog 内のデータベースの名前です。

残りのセットアップを終了し、クローラを少なくとも 1 回実行して、S3 バケット内のソース CSV データのためのカタログエントリを作成します。

完了後、Data Catalog に生成されたテーブルを見直します。クローラは cfs_full という名前のテーブルを作成し、データタイプを CSV として正しく識別します。

テーブル名 cfs_full を選択して、データソース用に作成されたスキーマを見直します。スキーマは、ソース CSV データファイルからヘッダー行をピックアップして、列名に使用しています。

これで、S3 データをソース、オンプレミス PostgreSQL データベースを宛先として使用して、AWS Glue ETL ジョブをセットアップできるようになりました。ここでお見せするデモは、比較的シンプルなものです。このデモでは、JDBC 接続経由で、ターゲット PostgreSQL データベース内にある単一のテーブルに S3 からのデータをロードします。
ETL ジョブを作成するには、ナビゲーションペインで [ジョブ] を選択してから、[ジョブの追加] を選択します。ETL ジョブの名前を cfs_full_s3_to_onprem_postgres と命名します。
IAM ロール、ETL スクリプトを保存するための S3 の場所、および一時ディレクトリ領域を選択します。IAM ロールは、ETL ジョブで使用される、指定の S3 バケットプレフィックスへのアクセスを許可する必要があります。オプションとして、ETL ジョブのためにジョブのブックマークを有効化します。このオプションを使用すると、同じ ETL ジョブを再実行し、ソース S3 バケットからのすでに処理されたデータをスキップすることができます。

データソースには、AWS Glue Data Catalog テーブルから cfs_full テーブルを選択します。

次に、データターゲットに [データターゲットでテーブルを作成する] を選択します。選択後、ドロップダウンリストで [JDBC] を選択します。[接続] には、データベース名 glue_demo で実行されているオンプレミス PostgreSQL データベースサーバー用に先ほど作成した JDBC 接続である my-jdbc-connection を選択します。

デフォルトのマッピングを使って残りのセットアップを行い、ETL ジョブの作成を完了します。
最後に、自動生成された ETL スクリプトの画面が表示されます。スクリプトを見直して、必要に応じて追加の ETL 変更を行います。準備ができたら、[ジョブの実行] を選択して ETL ジョブを実行します。

ETL ジョブは、終了までに数分かかります。S3 バケットにある CSV ファイルからロードされたデータで、PostgreSQL データベースに cfs_full という名前の新しいテーブルが作成されます。よく使う SQL クライアントを使って、データベースをクエリすることでテーブルとデータを検証します。例えば、以下の SQL クエリを実行して結果を表示します。
SELECT * FROM cfs_full ORDER BY shipmt_id LIMIT 10;

これで、オンプレミス PostgreSQL データベースにあるテーブルデータが、次に説明するパート 2 のソースデータとして機能するようになります。
パート 2: AWS Glue ETL ジョブでオンプレミス PostgreSQL データベースからのデータを Apache Parquet フォーマットに変換する
このセクションでは、ETL ジョブのソースとしてオンプレミス PostgreSQL データベーステーブルを設定します。これは、データを Apache Parquet フォーマットに変換し、それを宛先 S3 バケットに保存します。
PostgreSQL データベーステーブルにポイントする別のクローラをセットアップして、データソースとして AWS Glue Data Catalog にテーブルメタデータを作成します。オプションとして、前述したように、他の手法を使って Data Catalog に直接メタデータを構築することもできます。

次に、先ほどオンプレミス PostgreSQL データベースサーバー用に作成した JDBC 接続 my-jdbc-connection を選択します。[インクルードパス] には、テーブル名パスを glue_demo/public/cfs_full として入力します。これは、glue_demo という名前のデータベースがある public スキーマ内の PostgreSQL テーブル名 cfs_full を参照します。

残りのセットアップ手順に従って、IAM ロールを提供し、前に作成した既存のデータベース cfs に AWS Glue Data Catalog テーブルを作成します。オプションとして、オンプレミス PostgreSQL テーブルデータを表す、Data Catalog で作成されたテーブル名 onprem_postgres_ のプレフィックスを入力します。
クローラを実行して、AWS Glue Data Catalog で onprem_postgres_glue_demo_public_cfs_full という名前で作成されたテーブルを表示します。テーブルスキーマを検証して、クローラがスキーマ詳細をキャプチャしたことを確認します。

(オプション) JDBC 読み取り並列性のためのチューニング
場合によっては、大容量データベーステーブルでの AWS Glue ETL ジョブの実行によって out-of-memory (OOM) エラーを生じることがあります。すべてのデータが単一のエグゼキュータに読み込まれることが理由です。この状況を避けるには、Apache Spark パーティションの数と、ジョブ実行中に開かれる並行 JDBC 接続の数を最適化できます。
データベーステーブルをクロールした後、これらの手順に従ってパラメーターのチューニングを行ってください。
- Data Catalog で、テーブルを編集してパーティションパラメーター hashexpression または hashfield を追加します。ジョブは、以下に説明するように、これらのパラメーターのために選択された列と共に、大容量テーブルのデータをパーティション分割します。
- hashexpression: データベーステーブルに固有 ID または同様のデータなどの数値を含む列がある場合は、パラメーター hashexpression 用にその列の名前を選択します。この例では、shipmt_id が単調増加列で、hashexpression に適切な候補となります。
- Hashfield: 適切な数値列がない場合、バランス良く均等に分散された文字列値が含まれる列 (高カーディナリティ) を見つけて、パラメーター hashfield 用にその列の名前を選択します。
- hashpartitions: hashpartition の値を数値として提供します。デフォルトで、この値は 7 に設定されています。このパラメーターは、Spark パーティションの数を判断し、その結果となる数の JDBC 接続がターゲットデータベースに対して開かれます。
この例では、hashexpression が hashpartition 値 15 の shipmt_id として選択されています。

次に、cfs_onprem_postgres_to_s3_parquet という名前で別の ETL ジョブを作成します。ETL スクリプト用に、IAM ロールおよび S3 バケット の場所の選択などを行います。
次の画面で、オンプレミス PostgreSQL データテーブルをポイントする AWS Glue Data Catalog から、データソース onprem_postgres_glue_demo_public_cfs_full を選択します。次に、[データターゲットでテーブルを作成する] を選択します。[形式] に [Parquet] を選択し、データターゲットパスを S3 バケットプレフィックスに設定します。

ETL スクリプト画面が表示されるまで、プロンプトに従います。自動生成された pySpark スクリプトは、オンプレミス PostgreSQL データベーステーブルからデータを取得し、ターゲット S3 バケットに複数の Parquet ファイルを書き込むように設定されています。デフォルトで、すべての Parquet ファイルが同じ S3 プレフィックスレベルで書き込まれます。

オプションとして、S3 への書き込み時にデータをパーティション分割したい場合は、AWS Glue ドキュメントで説明されているように、ETL スクリプトを編集して partitionKeys パラメーターを追加することができます。この例では、ここに示されているように、pySpark スクリプトを編集して、オプション “partitionKeys“:[“Quarter“] を追加する行を検索します。
[保存]、[ジョブの実行] を選択します。ジョブが実行され、S3 バケットへの Parquet ファイルの書き込み時に、データが複数のパーティションに出力されます。各出力パーティションは、PostgreSQL データベーステーブルの column name quarter にある別個の値に対応します。
ETL ジョブ は CFS データを Parquet フォーマットに変換し、データを 4 つの S3 バケットプレフィックス (四半期ごとにひとつ) に分類します。以下に示す S3 バケット出力リストは S3 CLI を使用しています。

AWS Glue が、前に設定した hashpartitions パラメーターの値に基づいて、ETL ジョブ実行中に数個のデータベース接続を並行して開くことに注目してください。PostgreSQL では、以下の SQL コマンドを使用してアクティブなデータベース接続の数を確認できます。
これで変換されたデータが S3 で使用可能になり、データレイクとして機能できるようになります。データは、Amazon Redshift ベースのデータウェアハウスへのアップロード、または Amazon Athena と Amazon QuickSight を使用した分析の実行などの他のサービスに取り込まれる準備が整っています。
デモを行うために、新しいクローラを作成して、それを前の手順で生成されたパーティション分割されている Parquet データで実行します。Data Catalog で作成された新しいテーブルに移動して、[アクション]、[データの表示] と選択します。その後、以下にあるように、Athena のクエリエディタで、パーティション分割された Parquet データでの SQL クエリを実行できます。

以下は、Athena を使った SQL クエリ例です。Athena クエリ時に S3 バケットでスキャンされるデータの量を制限するため、SQL クエリで WHERE 句と共に partition key quarter が使用されていることに注意してください。

ハイブリッド環境に関するその他考慮事項
シナリオには、環境に追加の設定が必要となるものがあります。このセクションでは、カスタム DNS サーバー使用時のセットアップにおける考慮事項と、複数の JDBC 接続使用時の VPC/サブネットルーティングとセキュリティグループに関する考慮事項について説明します。
カスタム DNS サーバー
VPC については、ネットワーク属性の enableDnsHostnames と enableDnsSupport が true に設定されていることを確認してください。詳細については、「VPC での DNS のセットアップ」を参照してください。
名前解決用にカスタム DNS サーバーを使用するときは、フォワード DNS ルックアップとリバース DNS ルックアップの両方を AWS Glue Elastic Network Interface のために使用される VPC/サブネット全体に実装する必要があります。ENI は一時的なものであり、サブネット内で使用できる IP アドレスならどれでも使用できます。ETL ジョブは、フォワードおよびリバース DNS ルックアップの両方が ENI IP アドレスに対して失敗するときに、DNS エラーを受け取る場合があります。
例えば、AWS Glue ENI が VPC/サブネットで IP アドレス 10.10.10.14 を取得するとします。デフォルトの VPC DNS リゾルバ を使うと、リゾルバが IP アドレス 10.10.10.14 のリバース DNS を ip-10-10-10-14.ec2.internal として正しく解決し、 名前 ip-10-10-10-14.ec2.internal. のフォワード DNS を 10.10.10.14 として解決します。ETL ジョブは、DNS エラーをスローしません。
VPN または DX 経由で接続するオンプレミス DNS サーバーなどのカスタム DNS サーバーを使用するときは、同様の DNS 解決セットアップを実装するようにしてください。お使いの DNS サーバーのドキュメントを参照してください。例えば、BIND を使用している場合は、一連のレコードを簡単に作成するために $GENERATE directive を使用できます。
もうひとつのオプションは、VPC に DNS フォワーダーを実装し、オンプレミス DNS サーバーと VPC DNS リゾルバの両方を使用して解決するためのハイブリッド DNS 解決をセットアップすることです。実装の詳細については、以下の AWS セキュリティブログ記事を参照してください。
- How to Set Up DNS Resolution Between On-Premises Networks and AWS by Using Unbound
- How to Set Up DNS Resolution Between On-Premises Networks and AWS Using AWS Directory Service and Microsoft Active Directory
複数の JDBC 接続を使った AWS Glue ETL ジョブ
単一の JDBC 接続をテストする、または単一の JDBC 接続を使ってクローラを実行するとき、AWS Glue は、選択された JDBC 接続設定から ENI のための VPC/サブネットとセキュリティグループパラメーターを取得します。AWS Glue は次に、ENI を作成して、ネットワーク経由で JDBC データストアにアクセスします。また、これは単一の JDBC 接続でセットアップされている AWS Glue ETL ジョブでも良好に機能します。
ジョブが複数の JDBC 接続を使用するように設定されている場合は、追加のセットアップ考慮事項が該当する場合があります。例えば、最初の JDBC 接続が PostgreSQL データベースに接続するソースとして使用され、2 番目の JDBC 接続が Amazon Aurora データベースに接続するターゲットとして使用されます。このシナリオでは、AWS Glue がそれぞれの JDBC 接続から JDBC ドライバ (JDBC URL) と資格情報 (ユーザー名とパスワード) をピックアップしますが、
ENI については、ETL ジョブ用に設定された 2 つの JDBC 接続うちひとつの接続からしかネットワークパラメーター (VPC/サブネットおよびセキュリティグループ) 情報をピックアップしません。AWS Glue は次に VPC/サブネット で ENI を作成し、ひとつの JDBC 接続だけを使って、定義されたとおりにセキュリティグループを関連付けます。その後、同じ ENI 一式を使ってネットワーク経由で両方の JDBC データストアにアクセスしようとします。
場合によっては、これが原因で、ひとつの JDBC 接続から選択した VPC/サブネットとセキュリティグループパラメーターを使って作成された ENI が 2 番目の JDBC データストアへのアクセスを禁止する場合に、ジョブエラーが生じる可能性があります。
以下の表は、AWS Glue ETL ジョブを複数の JDBC 接続で動作させるためのいくつかのシナリオと、追加のセットアップ考慮事項を説明するものです。
| 2 つの JDBC 接続を使った ETL ジョブのシナリオ |
追加のセットアップ考慮事項 | 仕組みの説明 |
| 両方の JDBC 接続が同じ VPC/サブネットとセキュリティグループパラメーターを使用する。 | 追加のセットアップは必要ありません。 | AWS Glue は、どちらかの JDBC 接続から選択された、同じ VPC/サブネットとセキュリティグループ用のパラメーターで ENI を作成します。 この場合、ETL ジョブは 2 つの JDBC 接続で良好に機能します。 |
| 両方の JDBC 接続が同じ VPC/サブネットを使用するが、異なる セキュリティグループパラメーターを使用する。 | オプション 1: すべてのセキュリティグループ (SG) ルールをマージすることによって、両方の JDBC 接続に適用された SG を統合します。統合されたルールのすべてを使用して、新しい共通のセキュリティグループを作成します。新しい共通のセキュリティグループを両方の JDBC 接続に適用します。 オプション 2: 両方の JDBC 接続に適用されたすべてのセキュリティグループを含む結合リストを作成します。結合リストからのすべてのセキュリティグループを両方の JDBC 接続に適用します。 |
AWS Glue は、どちらかの JDBC 接続から選択された、同じ VPC/サブネットとセキュリティグループ用のパラメーターで ENI を作成します。 この場合、追加のセットアップステップを適用した後で、ETL ジョブが 2 つの JDBC 接続で良好に機能するようになります。 |
| 両方の JDBC 接続が異なる VPC/サブネットと異なる セキュリティグループパラメーターを使用する。 | セキュリティグループについては、前のシナリオにあるオプション 1 またはオプション 2 に似たセットアップを適用します。 VPC/サブネットについては、両方の JDBC データストアがどちらの VPC/サブネットからもアクセスされるようにルーティングテーブルとネットワークパスが設定されていることを確認してください。 |
AWS Glue は、どちらかの JDBC 接続から選択された同じセキュリティグループパラメーターを使って ENI を作成します。 VPC/サブネットのルーティングレベルでのセットアップは、AWS Glue ENI が、選択されたどちらの VPC/サブネットからでも JDBC データストアにアクセスできることを確実にします。 この場合、追加のセットアップステップを適用した後で、ETL ジョブが 2 つの JDBC 接続で良好に機能するようになります。 |
まとめ
この記事では、ハイブリッド環境で AWS Glue をセットアップする方法のデモを行いました。クラウド内で AWS Glue をマネージド ETL サービスとして使用すると、大幅な移行取り組みを行うことなく、VPC とデータセンター間の既存の接続を使って既存のデータベースサービスにアクセスすることができます。これは、即時的なメリットを提供してくれます。
また、2 つの異なる VPC でワークロードを実行するときにも、同じようなセットアップを使用できます。JDBC 接続は、ひとつの AWS リージョン内または異なるリージョンにまたがる 2 つの VPC 間の VPC ピアリングリンク経由で、またはインターリージョン VPC ピアリングを使ってセットアップできます。
Amazon S3 を使用してデータレイクセットアップを作成し、データを定期的にデータソースからデータレイクに移動させることができます。AWS Glue と、Amazon Athena、Amazon Redshift Spectrum、および Amazon QuickSight などのその他のクラウドサービスは、コスト効率が極めて高い方法でデータレイクとやり取りすることができます。詳細については、Build a Data Lake Foundation with AWS Glue and Amazon S3 を参照してください。
その他の参考資料
この記事が役に立つと思われる場合は、AWS Step FunctionsとAWS Lambdaを使って複数のETLジョブの統合を行う、および AWS Glue のリソースも併せてお読みください。
今回のブログ投稿者について
 Rajeev Meharwal は、AWS Public Sector Team のソリューションアーキテクトです。Rajeev は、クラウドで最新鋭のアーキテクチャを実装するためにお客様と交流し、サポートすることに情熱を持っており、彼の焦点の中核は、クラウド内でのネットワーキング、サーバーレスコンピューティング、およびデータ分析です。Rajeev は、家族とのハイキング、バドミントン、そして元気な飼い犬を追いかけることを楽しんでいます。
Rajeev Meharwal は、AWS Public Sector Team のソリューションアーキテクトです。Rajeev は、クラウドで最新鋭のアーキテクチャを実装するためにお客様と交流し、サポートすることに情熱を持っており、彼の焦点の中核は、クラウド内でのネットワーキング、サーバーレスコンピューティング、およびデータ分析です。Rajeev は、家族とのハイキング、バドミントン、そして元気な飼い犬を追いかけることを楽しんでいます。